机器之心 & ArXiv Weekly Radiostation
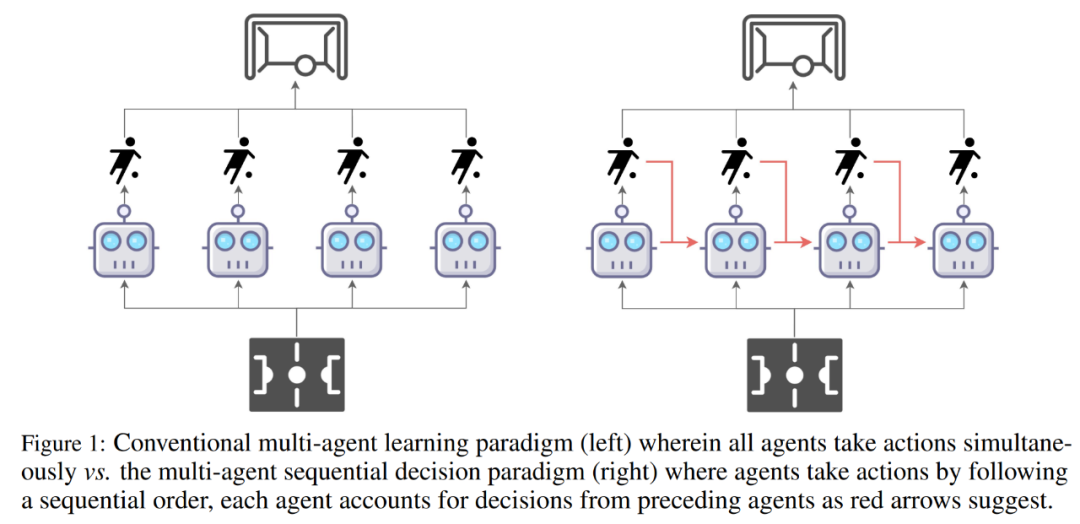
本周主要论文包括:上海交通大学、Digital Brain Lab、牛津大学等的研究者用新型 Transformer 架构解决多智能体强化学习问题;ICRA 2022 最佳论文出炉,美团无人机团队获唯一最佳导航论文奖等研究。
Multi-Agent Reinforcement Learning is A Sequence Modeling Problem
StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets
End-to-end symbolic regression with transformers
EDPLVO: Efficient Direct Point-Line Visual Odometry
A Ceramic-Electrolyte Glucose Fuel Cell for Implantable Electronics
An Evolutionary Approach to Dynamic Introduction of Tasks in Large-scale Multitask Learning Systems
Bridging Video-text Retrieval with Multiple Choice Questions
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:Multi-Agent Reinforcement Learning is A Sequence Modeling Problem
摘要:
如何用序列模型解决 MARL(多智能体强化学习) 问题?来自上海交通大学、Digital Brain Lab、牛津大学等的研究者提出一种新型多智能体 Transformer(MAT,Multi-Agent Transformer) 架构,该架构可以有效地将协作 MARL 问题转化为序列模型问题,其任务是将智能体的观测序列映射到智能体的最优动作序列。
本文的目标是在 MARL 和 SM 之间建立桥梁,以便为 MARL 释放现代序列模型的建模能力。MAT 的核心是编码器 - 解码器架构,它利用多智能体优势分解定理,将联合策略搜索问题转化为序列决策过程,这样多智能体问题就会表现出线性时间复杂度,最重要的是,这样做可以保证 MAT 单调性能提升。与 Decision Transformer 等先前技术需要预先收集的离线数据不同,MAT 以在线策略方式通过来自环境的在线试验和错误进行训练。
为了验证 MAT,研究者在 StarCraftII、Multi-Agent MuJoCo、Dexterous Hands Manipulation 和 Google Research Football 基准上进行了广泛的实验。结果表明,与 MAPPO 和 HAPPO 等强基线相比,MAT 具有更好的性能和数据效率。此外,该研究还证明了无论智能体的数量如何变化,MAT 在没见过的任务上表现较好,可是说是一个优秀的小样本学习者。
在本节中,研究者首先介绍了协作 MARL 问题公式和多智能体优势分解定理,这是本文的基石。然后,他们回顾了现有的与 MAT 相关的 MARL 方法,最后引出了 Transformer。
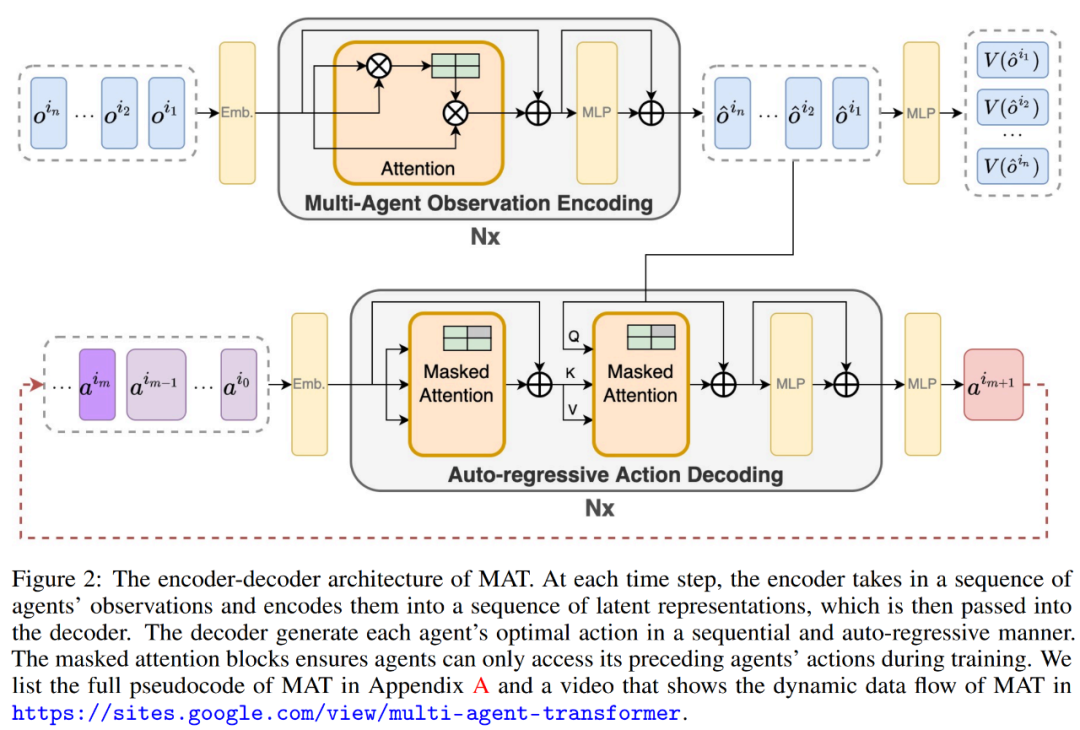
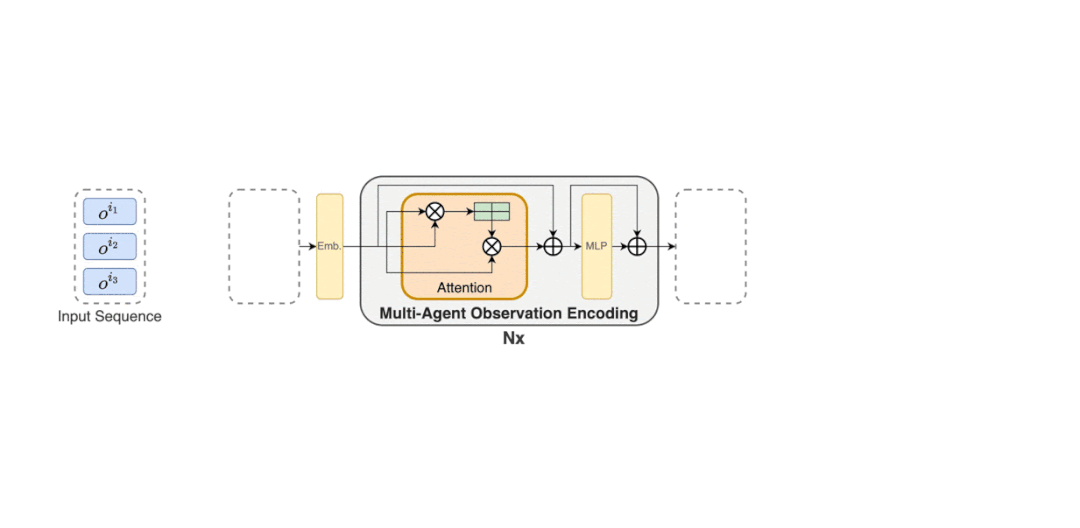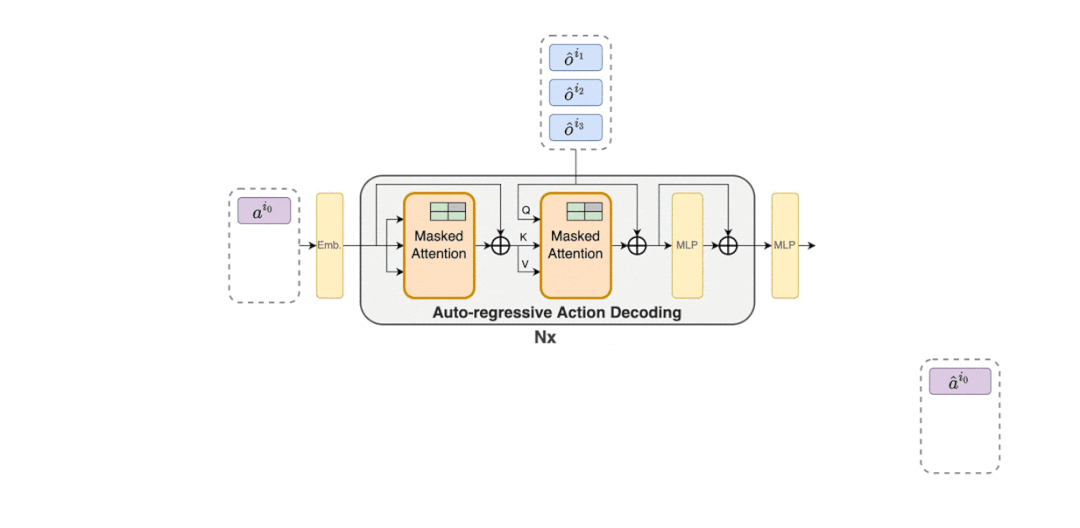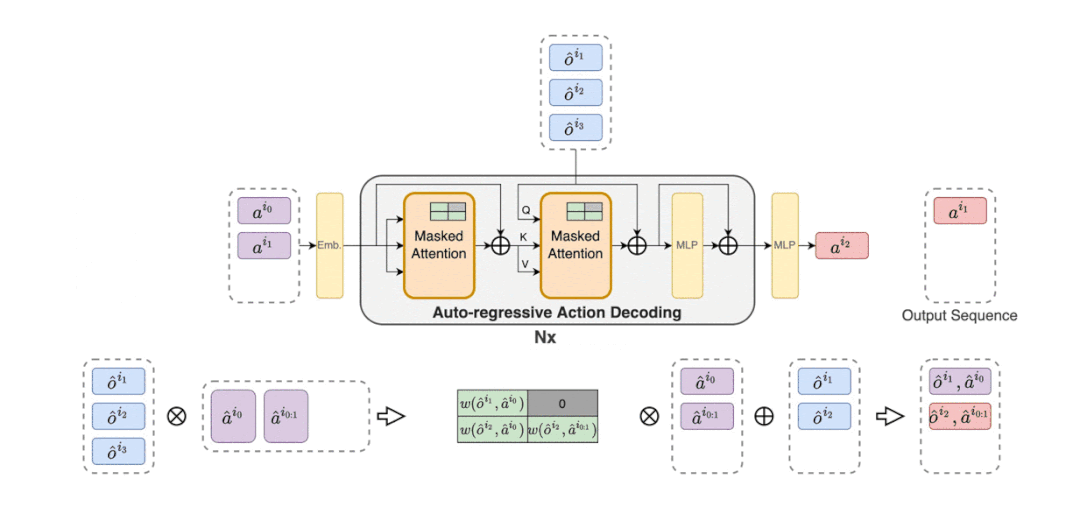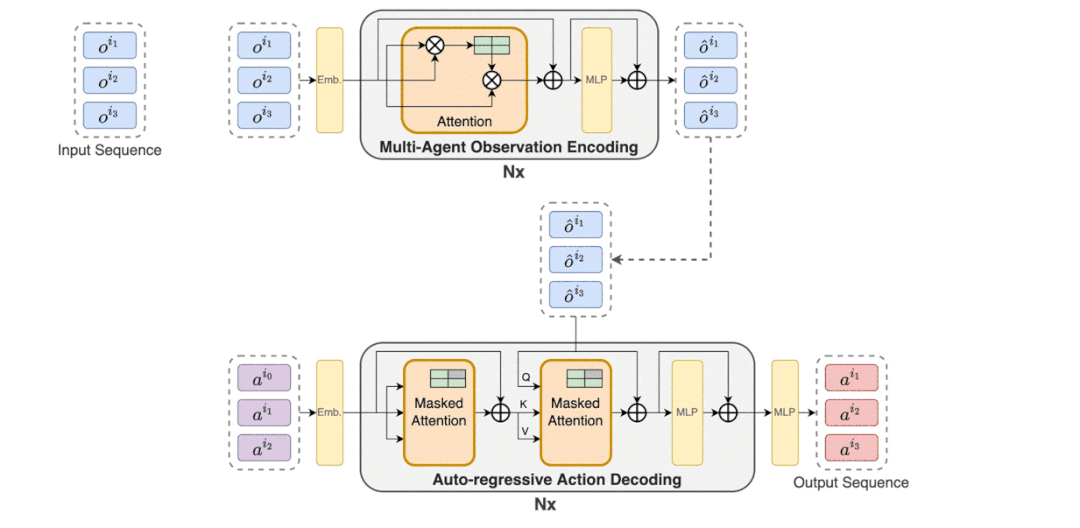
MAT 中包含了一个用于学习联合观察表示的编码器和一个以自回归方式为每个智能体输出动作的解码器。
![]()
推荐:
星际争霸 II 协作对抗基准超越 SOTA,新型 Transformer 架构解决多智能体强化学习问题。
论文 2:StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets
摘要:
近日,英伟达提出了一种新的架构变化,并根据最新的 StyleGAN3 设计了渐进式生长的策略。研究者将改进后的模型称为 StyleGAN-XL,该研究目前已经入选了 SIGGRAPH 2022。
这些变化结合了 Projected GAN 方法,超越了此前在 ImageNet 上训练 StyleGAN 的表现。为了进一步改进结果,研究者分析了 Projected GAN 的预训练特征网络,发现当计算机视觉的两种标准神经结构 CNN 和 ViT [ Dosovitskiy et al. 2021] 联合使用时,性能显著提高。最后,研究者利用了分类器引导这种最初为扩散模型引入的技术,用以注入额外的类信息。
总体来说,这篇论文的贡献在于推动模型性能超越现有的 GAN 和扩散模型,实现了大规模图像合成 SOTA。论文展示了 ImageNet 类的反演和编辑,发现了一个强大的新反演范式 Pivotal Tuning Inversion (PTI)[ Roich et al. 2021] ,这一范式能够与模型很好地结合,甚至平滑地嵌入域外图像到学习到的潜在空间。高效的训练策略使得标准 StyleGAN3 的参数能够增加三倍,同时仅用一小部分训练时间就达到扩散模型的 SOTA 性能。
这使得 StyleGAN-XL 能够成为第一个在 ImageNet-scale 上演示 1024^2 分辨率图像合成的模型。
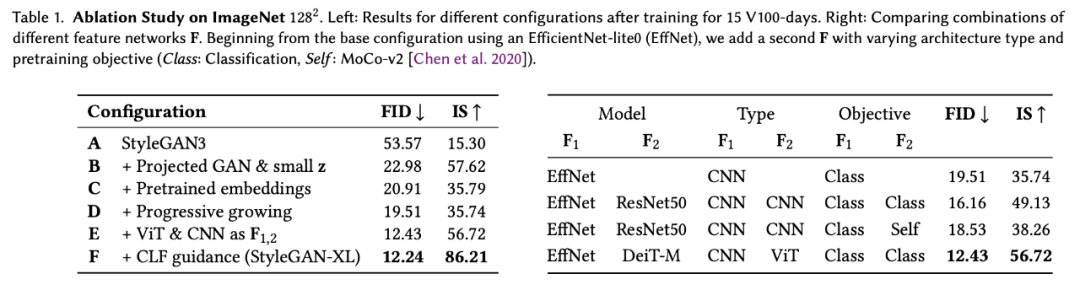
实验表明,即使是最新的 StyleGAN3 也不能很好地扩展到 ImageNet 上,如图 1 所示。特别是在高分辨率时,训练会变得不稳定。因此,研究者的第一个目标是在 ImageNet 上成功地训练一个 StyleGAN3 生成器。成功的定义取决于主要通过初始评分 (IS)[Salimans et al. 2016] 衡量的样本质量和 Fréchet 初始距离 (FID)[Heusel et al. 2017] 衡量的多样性。在论文中,研究者也介绍了 StyleGAN3 baseline 进行的改动,所带来的提升如下表 1 所示:
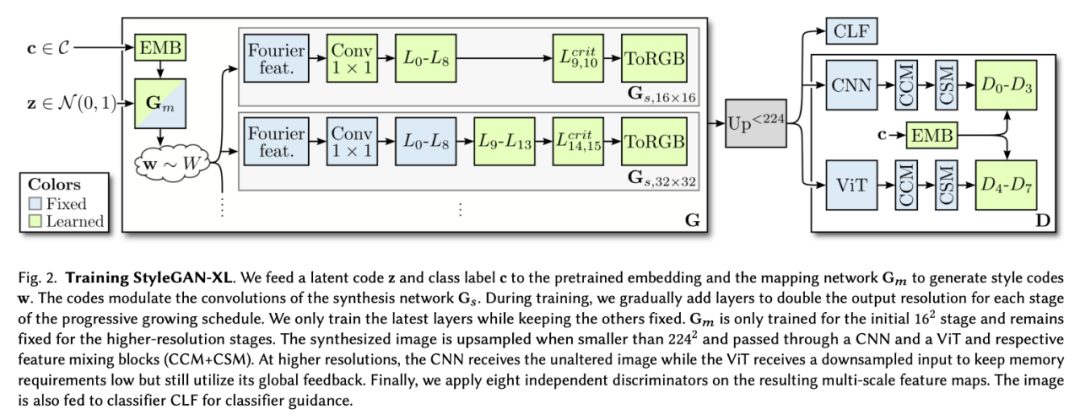
StyleGAN-XL 在深度和参数计数方面比标准的 StyleGAN3 大三倍。然而,为了在 512^2 像素的分辨率下匹配 ADM [Dhariwal and Nichol 2021] 先进的性能,在一台 NVIDIA Tesla V100 上训练模型需要 400 天,而以前需要 1914 天。(图 2)。
推荐:
英伟达公布 StyleGAN-XL:参数量 3 倍于 StyleGAN3,计算时间仅为五分之一。
论文 3:End-to-end symbolic regression with transformers
摘要:
符号回归,即根据观察函数值来预测函数数学表达式的任务,通常涉及两步过程:预测表达式的「主干」并选择数值常数,然后通过优化非凸损失函数来拟合常数。其中用到的方法主要是遗传编程,通过多次迭代子程序实现算法进化。神经网络最近曾在一次尝试中预测出正确的表达式主干,但仍然没有那么强大。
在近期的一项研究中,来自 Meta AI(Facebook)、法国索邦大学、巴黎高师的研究者提出了一种 E2E 模型,尝试一步完成预测,让 Transformer 直接预测完整的数学表达式,包括其中的常数。随后通过将预测常数作为已知初始化提供给非凸优化器来更新预测常数。
该研究进行消融实验以表明这种端到端方法产生了更好的结果,有时甚至不需要更新步骤。研究者针对 SRBench 基准测试中的问题评估了该模型,并表明该模型接近 SOTA 遗传编程的性能,推理速度提高了几个数量级。
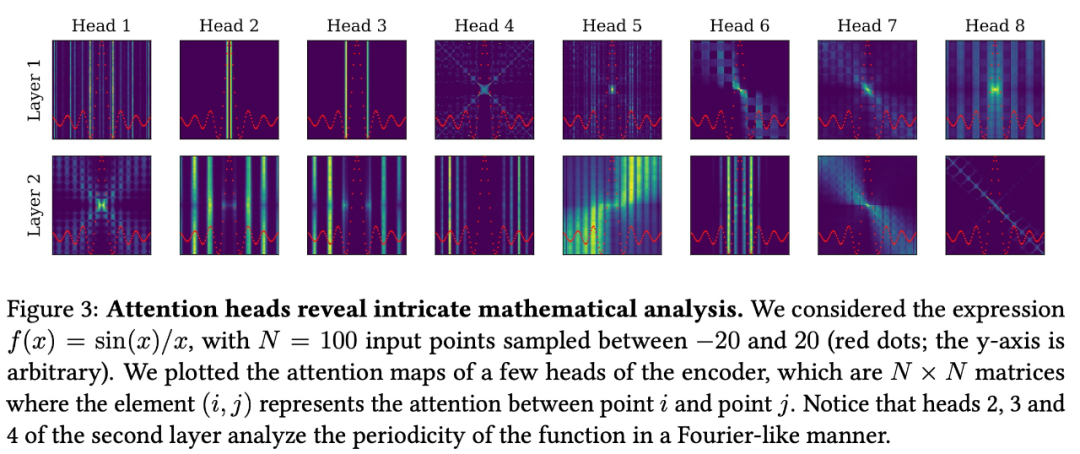
该研究提出了一个嵌入器( embedder )来将每个输入点映射成单一嵌入。嵌入器将空输入维度填充(pad)到 D_max,然后将 3(D_max+1)d_emb 维向量馈入具有 ReLU 激活的 2 层全连接前馈网络 (FFN) 中,该网络向下投影到 d_emb 维度,得到的 d_emb 维的 N 个嵌入被馈送到 Transformer。
该研究使用一个序列到序列的 Transformer 架构,它有 16 个 attention head,嵌入维度为 512,总共包含 86M 个参数。像《 ‘Linear algebra with transformers 》研究中一样,研究者观察到解决这个问题的最佳架构是不对称的,解码器更深:在编码器中使用 4 层,在解码器中使用 16 层。该任务的一个显著特性是 N 个输入点的排列不变性。为了解释这种不变性,研究者从编码器中删除了位置嵌入。
如下图 3 所示,编码器捕获所考虑函数的最显著特征,例如临界点和周期性,并将专注于局部细节的短程 head 与捕获函数全局的长程 head 混合在一起。
推荐:
来自 Mata AI、法国索邦大学、巴黎高师的研究者成功让 Transformer 直接预测出完整的数学表达式。
论文 4:EDPLVO: Efficient Direct Point-Line Visual Odometry
摘要:
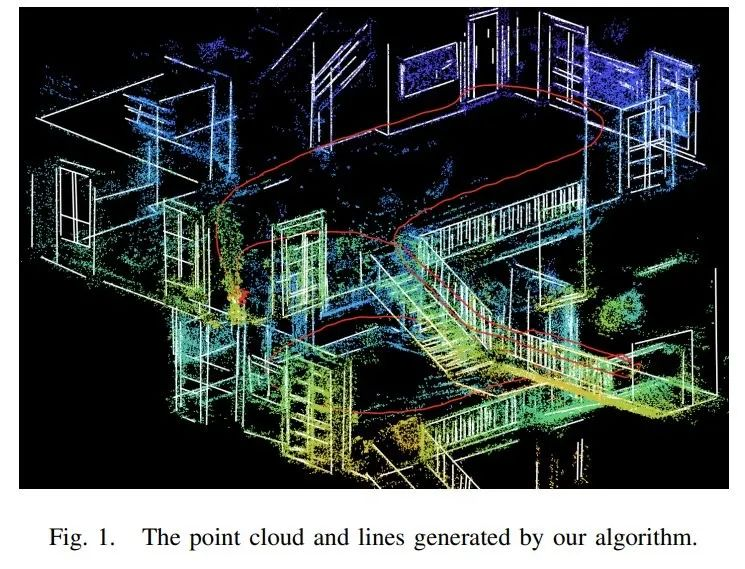
国际机器人技术与自动化会议 ICRA 2022 于 5 月 23 日至 5 月 27 日在美举办,这是 Robotics(机器人学)领域最顶级的国际会议之一。美团无人机团队一篇关于视觉里程计的研究获得了大会导航领域的年度最佳论文(Outstanding Navigation Paper),这也是今年唯一一篇第一作者和第一单位均来自中国境内科技公司和高校的获奖论文。
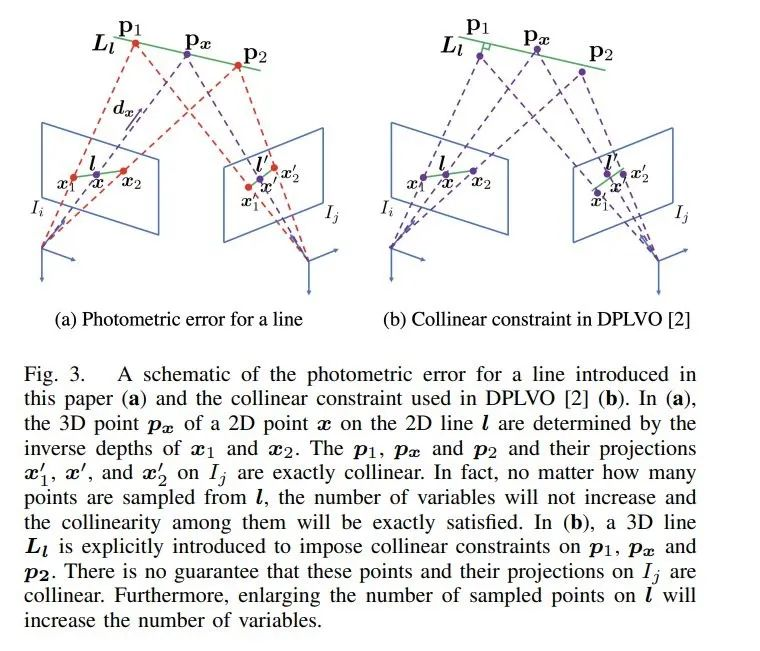
在这篇论文中,作者提出了一种使用点和线的高效的直接视觉里程计(visual odometry,VO)算法—— EDPLVO 。他们证明了,2D 线上的 3D 像素点由 2D 线端点的逆深度决定,这使得将光度误差扩展到线变得可行。与该团队之前的算法 DPLVO 相比,新算法大大减少了优化中的变量数量,而且充分利用了共线性。在此基础上,他们还引入了一个两步优化方法来加快优化速度,并证明了算法的收敛性。
实验结果表明,该算法的性能优于目前最先进的直接 VO 算法。这项技术将在以无人机、自动配送车为代表的机器人自主导航以及 AR/VR 等领域进行广泛应用。该研究提出了一种新的算法——EDPLVO。
他们将光度误差扩展到了线。原来的光度误差只针对点定义,很难应用到线。与 DPLVO 中简单地将共线约束引入成本函数不同,他们提出了一种参数化 3D 共线点的新方法,从而使得将光度误差扩展到线变得可行。具体来说,他们证明了 2D 线上任意点的 3D 点由 2D 线两个端点的逆深度决定。该属性可以显著减少变量的数量。同时,该方法在优化过程中严格满足共线约束,这提高了准确率。
他们引入了一个两步骤方法来限制由于在优化中引入长期线关联而导致的计算复杂度。在每次迭代中,他们首先使用固定的逆深度和关键帧姿态来拟合 3D 线。然后,他们使用新的线参数来调节逆深度和关键帧姿态的优化结果。由此产生的两个优化问题很容易解决。研究者证明了该方法总是可以收敛的。
推荐:
ICRA 2022 最佳论文出炉:美团无人机团队获唯一最佳导航论文奖。
论文 5:A Ceramic-Electrolyte Glucose Fuel Cell for Implantable Electronics
摘要:
近日,MIT 材料科学与工程系(DMSE)博士、Amgen 公司现运营经理 Philipp Simons 与其同事开发出了一种新型的葡萄糖燃料电池,可以直接将葡萄糖转换为电流。相关论文《A Ceramic-Electrolyte Glucose Fuel Cell for Implantable Electronics》在期刊 Advanced Materials 上发表。
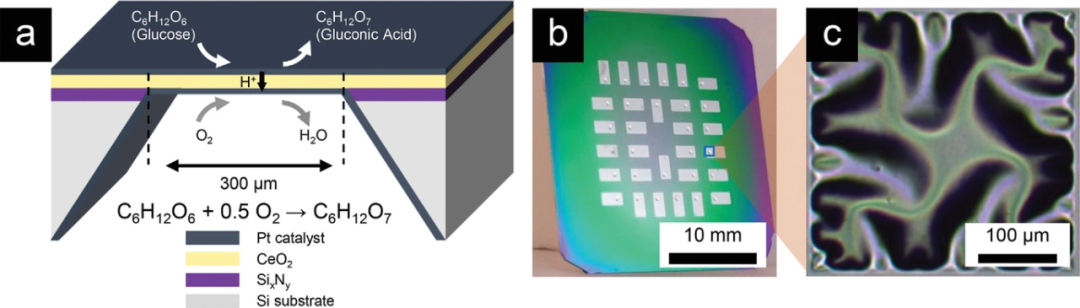
该设备体积小于其他研究提出的葡萄糖燃料电池,仅 400 纳米厚,大约为人头发直径的 1/100。含糖(sugary)电源每平方厘米可以产生大约 43 微瓦特电流,实现了迄今为止环境条件下所有葡萄糖燃料电池所能产生的最高功率密度。
新的葡萄糖燃料电池具有很强的耐受力,能够承受最高 600 摄氏度的温度。如果集成到医学植入物中,该燃料电池可以在所有植入式设备所需的高温灭菌过程保持稳定。设备的核心由陶瓷制成,这种材料即使在高温和微型氧化皮下也能保持自身电化学属性。
如下从左到右分别为葡萄糖燃料电池、芯片和单个设备的示意图。其中,a 为基于多孔 Pt 阳极 / 二氧化铈电解质 / 密集 Pt 阴极的独立式膜的陶瓷葡萄糖燃料电池的构造;b 为包含 30 个葡萄糖燃料电池设备的燃料电池芯片示意图;c 为单个独立式铈膜的光学显微镜图像。
推荐:
耐 600 度高温,MIT 用陶瓷制成葡萄糖燃料电池,为身体植入设备供电。
论文 6:An Evolutionary Approach to Dynamic Introduction of Tasks in Large-scale Multitask Learning Systems
摘要:
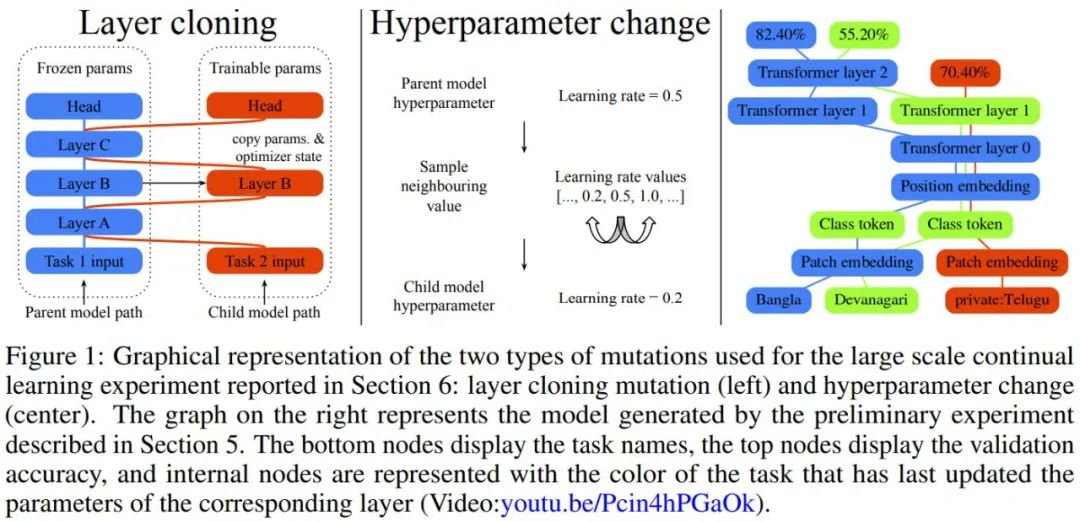
在该论文中,Jeff Dean 等人提出了一种进化算法,可以生成大规模的多任务模型,同时也支持新任务的动态和连续添加,生成的多任务模型是稀疏激活的,并集成了基于任务的路由,该路由保证了有限的计算成本,并且随着模型的扩展,每个任务添加的参数更少。
作者表示,其提出的新方法依赖于知识划分技术,实现了对灾难性遗忘和其他常见缺陷(如梯度干扰和负迁移)的免疫。实验表明,新方法可以联合解决并在 69 个图像分类任务上取得有竞争力的结果,例如对仅在公共数据上训练的模型,在 CIFAR-10 上实现了新的业界最高识别准确度 99.43%。
作者提出的 µ2Net 模型可以预训练或随机初始化。一次搜索出的单个任务上的最佳模型称为活动任务。在任务的活跃阶段,在活跃任务上训练的模型群体会不断进化——随机突变然后测试评分,保留高分的,淘汰低分的。一个活跃阶段由多代组成,其中并行采样和训练多批子模型。在任务活动阶段结束时,仅保留其最佳评分模型作为多任务系统的一部分。一个任务可以被多次激活。
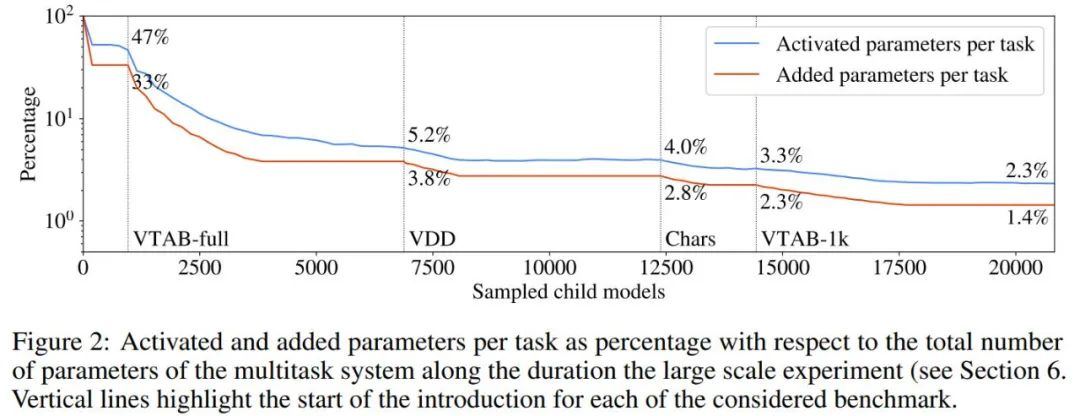
作者表示 µ2Net 可以在大型任务集上实现最先进的质量,并能够将新任务动态地引入正在运行的系统中。学习的任务越多,系统中嵌入的知识就越多。同时,随着系统的增长,参数激活的稀疏性使每个任务的计算量和内存使用量保持不变。通过实验,每个任务的平均增加参数量减少了 38%,由此产生的多任务系统仅激活了每个任务总参数的 2.3%。
论文 7:Bridging Video-text Retrieval with Multiple Choice Questions
摘要:
用于文本视频检索的多模态预训练工作主要采用两类方法:“双流” 法训练两个单独的编码器来约束视频级别和语句级别的特征,忽略了各自模态的局部特征和模态间的交互;“单流” 法把视频和文本联结作为联合编码器的输入来进行模态间的融合,导致下游检索非常低效。
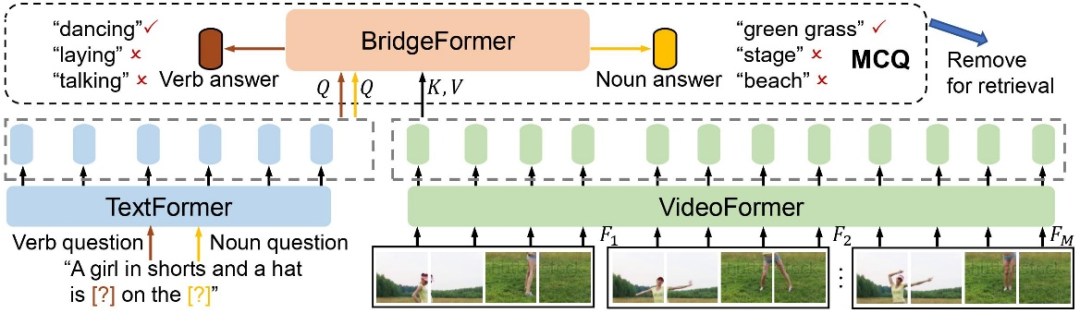
本文提出一个全新的带有参数化模块的借口任务(pretext task),叫做 “多项选择题”(MCQ),通过训练 BridgeFormer 根据视频内容回答文本构成的选择题,来实现细粒度的视频和文本交互,并在下游时移除辅助的 BridgeFormer,以保证高效的检索效率。
如下图所示,该研究的方法包含一个视频编码器 VideoFormer,用来从原始的视频帧提取视频特征;一个文本编码器 TextFormer,用来从自然语言提取文本特征。该研究通过抹去文本描述里的名词短语或动词短语,来分别构造名词问题和动词问题。以对比学习的形式,训练 BridgeFormer 通过求助 VideoFormer 提取到的局部视频特征,从多个选项里挑选出正确的答案。这里,多个选项由一个训练批次里所有被抹去的短语构成。
这一辅助的预训练目标会促使 VideoFormer 提取视频里准确的空间内容,使得 BridgeFormer 能够回答出名词问题,并捕获到视频里物体的时序移动,使得 BridgeFormer 能够回答出动词问题。这样的训练机制使得 VideoFormer 更能感知视频里的局部物体和时序动态。视频和文本局部特征的关联也通过问题和回答这样的形式得到了有效的建立。由于 BridgeFormer 联结了视频和文本的每一层特征,对 BridgeFormer 的约束就会进而优化视频和文本的特征。因此辅助的 BridgeFormer 只用于预训练,在下游检索时可以被移除,从而保留高效的双编码器结构。
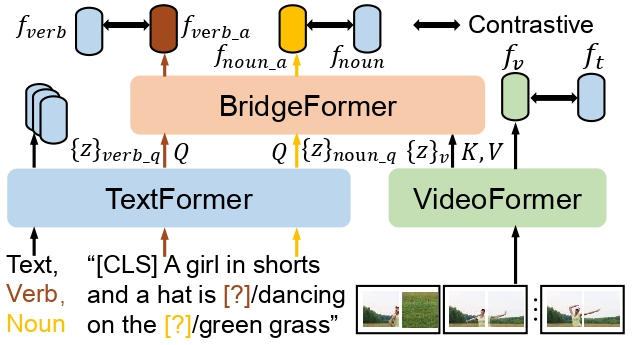
如下图所示,该研究预训练流程包含三个部分,来分别优化三个统一的对比学习(contrastive learning)形式的预训练目标:
该研究的模型包含一个视频编码器 VideoFormer,一个文本编码器 TextFormer,和一个辅助的编码器 BridgeFormer。每一个编码器由一系列 transformer 模块构成。TextFormer 输出的每一层问题文本特征被视为 query,VideoFormer 输出的每一层视频特征被视为 key 和 value,被送入 BridgeFormer 相应层来执行跨模态的注意力机制,以获得回答特征。
推荐:
视频文本预训练新 SOTA!港大、腾讯 ARC Lab 推出基于多项选择题的借口任务。
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
本周 10 篇 NLP 精选论文是:
1. A Multi-level Supervised Contrastive Learning Framework for Low-Resource Natural Language Inference. (from Philip S. Yu)
2. VD-PCR: Improving Visual Dialog with Pronoun Coreference Resolution. (from Hongming Zhang, Changshui Zhang)
3. CPED: A Large-Scale Chinese Personalized and Emotional Dialogue Dataset for Conversational AI. (from Minlie Huang)
4. Few-shot Subgoal Planning with Language Models. (from Honglak Lee)
5. Differentially Private Decoding in Large Language Models. (from Richard Zemel)
6. A Mixture-of-Expert Approach to RL-based Dialogue Management. (from Craig Boutilier)
7. CEBaB: Estimating the Causal Effects of Real-World Concepts on NLP Model Behavior. (from Christopher Potts)
8. Controllable Text Generation with Neurally-Decomposed Oracle. (from Kai-Wei Chang)
9. Understanding How People Rate Their Conversations. (from Dilek Hakkani-Tur)
10. An Informational Space Based Semantic Analysis for Scientific Texts. (from Alexander N. Gorban)
本周 10 篇 CV 精选论文是:
1. Voxel Field Fusion for 3D Object Detection. (from Jian Sun, Jiaya Jia)
2. Unifying Voxel-based Representation with Transformer for 3D Object Detection. (from Jian Sun, Jiaya Jia)
3. A Closer Look at Self-supervised Lightweight Vision Transformers. (from Jian Sun, Weiming Hu)
4. Unveiling The Mask of Position-Information Pattern Through the Mist of Image Features. (from Ming-Hsuan Yang)
5. Cascaded Video Generation for Videos In-the-Wild. (from Aaron Courville)
6. Modeling Image Composition for Complex Scene Generation. (from Jie Yang, Dacheng Tao)
7. Visual Superordinate Abstraction for Robust Concept Learning. (from Dacheng Tao)
8. Multi-Task Learning with Multi-query Transformer for Dense Prediction. (from Dacheng Tao)
9. Glo-In-One: Holistic Glomerular Detection, Segmentation, and Lesion Characterization with Large-scale Web Image Mining. (from Agnes B. Fogo)
10. Siamese Image Modeling for Self-Supervised Vision Representation Learning. (from Yu Qiao, Xiaogang Wang)
本周 10 篇 ML 精选论文是:
1. Provably Sample-Efficient RL with Side Information about Latent Dynamics. (from Robert E. Schapire)
2. Learning to Control Linear Systems can be Hard. (from Manfred Morari, George J. Pappas)
3. So3krates -- Self-attention for higher-order geometric interactions on arbitrary length-scales. (from Klaus-Robert Müller)
4. Graph-level Neural Networks: Current Progress and Future Directions. (from Jian Yang, Quan Z. Sheng, Charu Aggarwal)
5. Dataset Distillation using Neural Feature Regression. (from Jimmy Ba)
6. You Can't Count on Luck: Why Decision Transformers Fail in Stochastic Environments. (from Jimmy Ba)
7. Adaptive Random Forests for Energy-Efficient Inference on Microcontrollers. (from Luca Benini)
8. Multi-Complexity-Loss DNAS for Energy-Efficient and Memory-Constrained Deep Neural Networks. (from Luca Benini)
9. Open Environment Machine Learning. (from Zhi-Hua Zhou)
10. Parameter-Efficient and Student-Friendly Knowledge Distillation. (from Dacheng Tao)
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com