图神经网络也能用作CV骨干模型,华为诺亚ViG架构媲美CNN、Transformer
机器之心编辑部
华为诺亚实验室的研究员发现图神经网络(GNN)也能做视觉骨干网络。将图像表示为图结构,通过简洁高效的适配,提出一种新型视觉网络架构 ViG,表现优于传统的卷积网络和 Transformer。在 ImageNet 图像识别任务,ViG 在相似计算量情况下 Top-1 正确率达 82.1%,高于 ResNet 和 Swin Transformer。
-
论文链接:https://arxiv.org/abs/2206.00272 -
PyTorch 代码:https://github.com/huawei-noah/CV-Backbones -
MindSpore 代码:https://gitee.com/mindspore/models/tree/master/research/cv/ViG

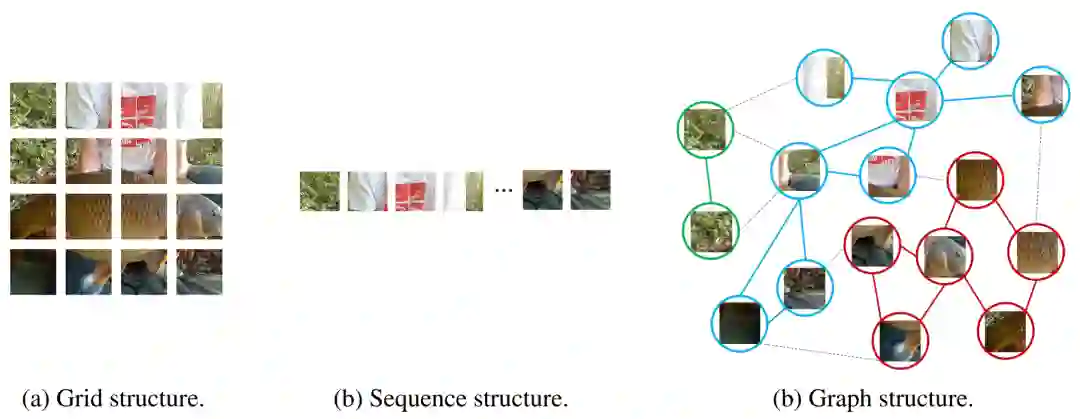
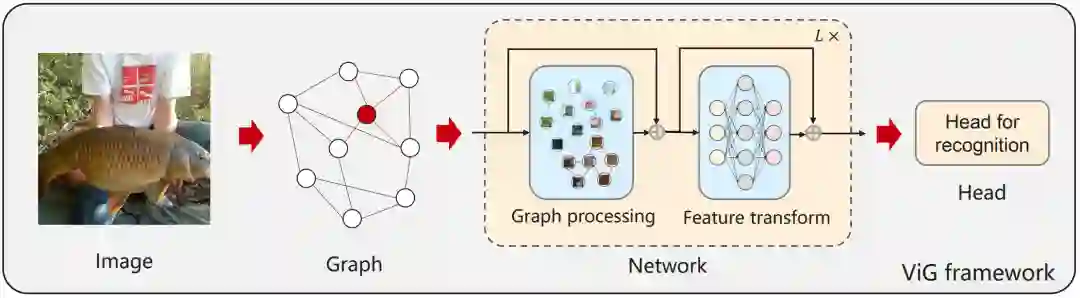
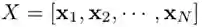 。这里每个图像块特征视作一个节点,也就是
。这里每个图像块特征视作一个节点,也就是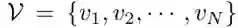 ,对于每个节点,作者找到它的 K 近邻
,对于每个节点,作者找到它的 K 近邻 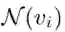 ,然后在两者之间连接一条边,从而构建出一个完整的图结构
,然后在两者之间连接一条边,从而构建出一个完整的图结构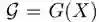 。
。
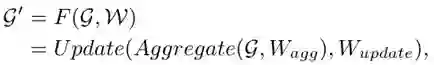
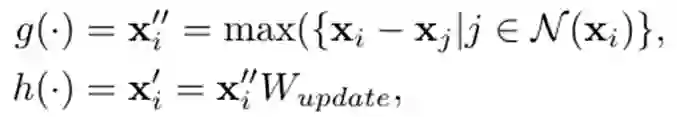


登录查看更多
相关内容
Arxiv
12+阅读 · 2021年5月30日

相关VIP内容
相关资讯
相关论文
Arxiv
12+阅读 · 2021年5月30日