推荐!【DARPA终身学习机器(L2M)】《自主系统中用于感知和行动的终身学习》美空军、宾大2022最新234页技术报告
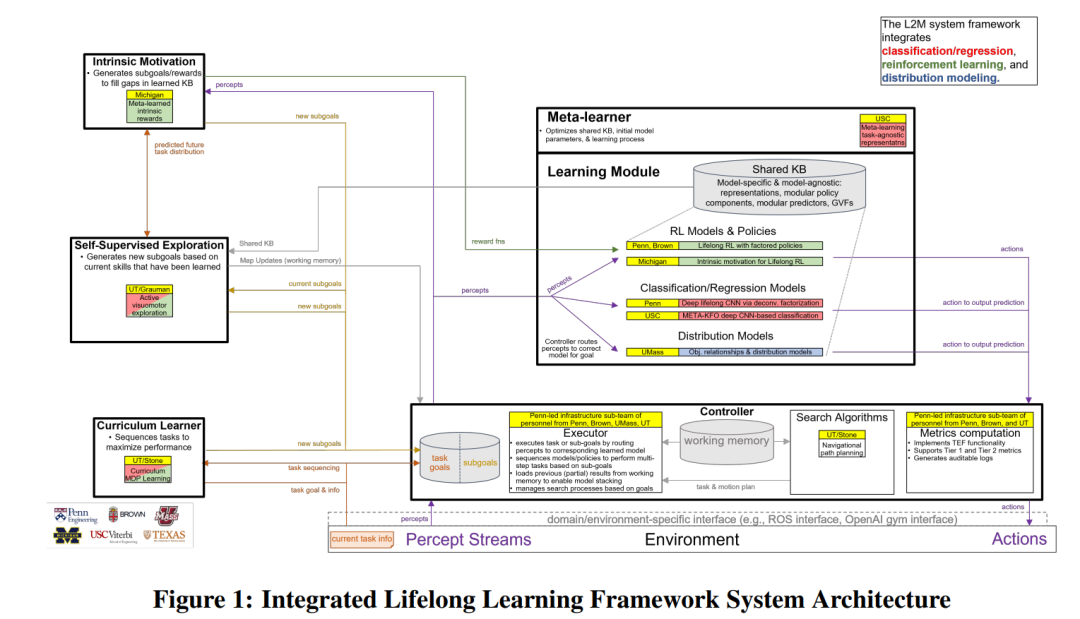
引言
2.1 本报告的目的
2.2 研究方法概述
2.3 本报告组织结构
2.4 主要贡献
2.4.1 集成系统和部件
2.4.2 研究方法



便捷下载,请关注专知人工智能公众号(点击上方关注)
点击“发消息” 回复 “LLL” 就可以获取《推荐!【DARPA终身学习机器(L2M)】《自主系统中用于感知和行动的终身学习》美空军、宾大2022最新234页技术报告》专知下载链接



登录查看更多
相关内容

专知会员服务
136+阅读 · 2022年11月23日
专知会员服务
32+阅读 · 2022年10月21日
Arxiv
0+阅读 · 2023年2月1日

相关VIP内容
专知会员服务
136+阅读 · 2022年11月23日
专知会员服务
32+阅读 · 2022年10月21日
相关资讯