
摘要
现代战争的特点是复杂性越来越高,敌手聪明且技术优良。为了解决现代战争的一些复杂性,基于机器学习(ML)的技术最近为战场上的自动化任务提供了合适的手段。然而,配备了ML技术的聪明敌人不仅在战场上参与公平竞争,而且还利用欺骗和隐蔽攻击等策略,制造恶意方法来破坏ML算法,获得不公平的优势。为了应对这些威胁,自动化战场系统上使用的ML技术必须能够强大地抵御敌方的攻击。
我们在一种称为“示范学习”(LfD)的强化学习算法的背景下,分析了竞争场景中的对抗学习问题。在LfD中,学习智能体观察由专家完成的操作演示,以学习快速有效地执行任务。LfD已成功应用于军事行动,如使用机器人团队进行自主搜索和侦察,或自主抓取拆除简易爆炸装置。然而,恶意的敌人可以通过植入敌对的专家来利用LfD,这些专家要么给出不正确的演示,要么修改合法的演示,从而使学习智能体在任务中失败。为了解决这个问题,我们首先分析了在LfD框架内对抗专家可以使用的不同的演示修改策略,根据对手的修改成本和修改学习代理对任务性能的影响。然后,我们提出了一个新的概念,利用对手和学习智能体之间的博弈,学习智能体可以使用LfD从潜在的对手专家演示中战略性地学习,而不显著降低其任务性能。在AI-Gym环境中,我们对提出的鲁棒学习技术进行了评估,该技术通过对雅达利类游戏“LunarLander”中的专家演示进行对抗性修改。
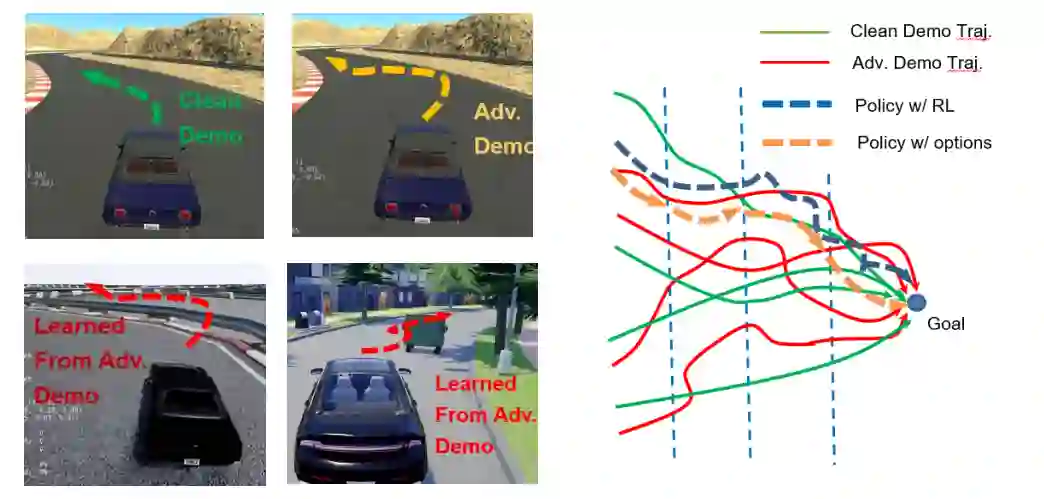
图1所示。(左)使用LfD学习自动驾驶设置时敌对轨迹对策略的影响。(右)在我们提出的方法中,干净(绿色)和对抗(红色)轨迹首先是等分的。然后,在使用选项(金虚线)接受或拒绝轨迹部分后,对每个分区学习策略,或对未分区的轨迹使用传统的强化学习(蓝虚线)。
对抗性专家演示框架
我们考虑这样一个场景,学习智能体必须通过从专家给出的任务演示(LfD)中进行强化学习来在环境中执行任务。一些专家可能是敌对的,并修改轨迹演示的意图,使学习智能体不能正确执行任务,而遵循修改的演示。在本文的其余部分中,为了便于阅读,我们将对抗性专家称为专家。LfD框架采用马尔可夫决策过程(MDP)[12]进行形式化。LfD算法的输出是一个策略,该策略为执行任务提供状态到动作映射。RL通过一个叫做训练的过程学习策略,在这个过程中,它探索环境,观察在探索过程中收到的状态-行为-奖励配对,最后选择一系列导致更高期望奖励的状态-行为-奖励配对作为它的策略。
专家们的演示以被称为轨迹的状态-行动-奖励元组序列的形式给出。专家轨迹可能是良性的,也可能是敌对的。良性和敌对的专家轨迹分别展示了完成任务的正确和不正确的方式,并帮助或阻碍了学习智能体学习执行任务。专家演示被整合到智能体的学习中,使用名为DAGGER[1]的LfD算法执行任务。DAGGER使用来自专家演示轨迹的监督学习来学习策略,但添加了一个权重参数β,该参数表示学习主体在将轨迹纳入其学习策略时的权重或信任度。

算法1。学习器用来接受或拒绝轨迹演示的算法。

算法2。由专家用来修改干净轨迹的算法。




