

在DARPA终身学习机器(L2M)计划下,Teledyne着手研究、实施和展示算法方法,以解决两个关键问题。首先,使智能体能够自我监督,以便在没有外部干预的情况下适应和学习复杂环境。为了解决这个问题,Teledyne开发并验证了不确定性跟踪和调制的作用,使智能体能够监测自己的性能,并在适当的条件下自信地进行调整。这是一个重大的突破,因为它展示了具身智能体的自我监督学习和任务表现。第二个问题是实现强大的知识表示,尽管不断地学习和适应,但仍能保持准确,并能适应学习多种任务的复杂性,对知识的粒度和组成可能有不同的要求。Teledyne开发并实施了一个分层学习系统,能够将任务信息分解到多个层次,以最大限度地提高鲁棒性和重复使用。这是一个重大突破,因为它使一类新的学习系统能够保持一致的知识库,并对其进行更新以适应多个任务,而不要求它们共享一个统一的表述。由此产生的算法被证明在最先进的机器学习系统中具有提升性能的作用,因此可以被纳入许多现今的人工智能解决方案中,使其具备终身的能力。一个关键的建议是寻找机会将这些能力过渡到现有的人工智能系统中,从而促进它们向下一波人工智能过渡。另一个建议是将这些成就视为阐明终身学习机制的第一步,并参与持续研究,以更充分地了解如何在高度复杂的环境和条件下实现学习。 这些可能会迫使我们更仔细地研究建立、维护和利用分层知识表示的更完整的解决方案。
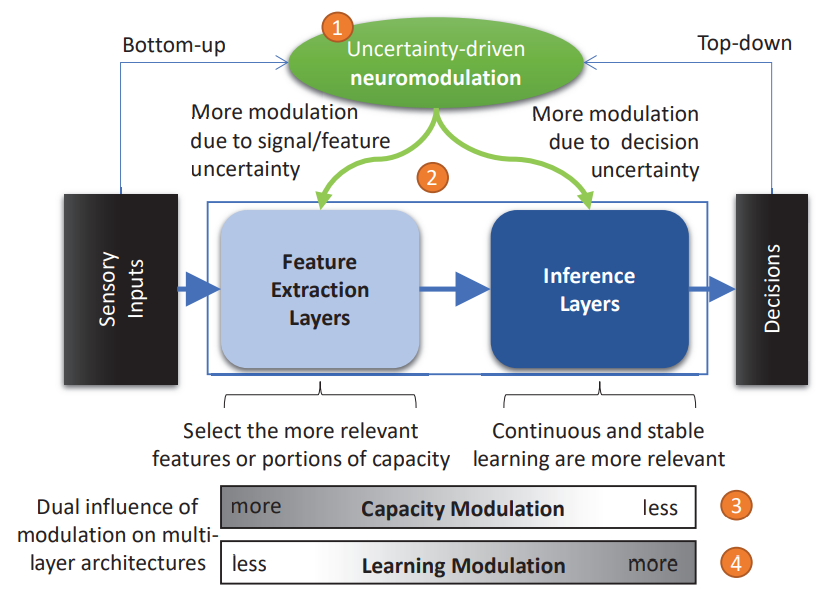
图 1. 分层机器学习系统中选择可塑性架构
报告总结
1.1 项目计划概述
在DARPA终身学习机(L2M)计划下,Teledyne进行了两个阶段的努力,开发能够选择性可塑性的机器学习系统。我们的努力解决了终身学习系统所面临的两个关键挑战:(1)对其参数进行持续而稳定的学习,以及(2)如何实现最佳能力分配,以便在任务和条件发生变化时获得有效的学习和性能。我们的核心前提是,大脑通过神经调节来解决这两个问题:持续调节神经活动和可塑性的化学信号。具体来说,我们研究了神经调节剂乙酰胆碱(ACh)调节长期突触可塑性和短期突触活动的机制,特别是在进行物体识别和鉴定的视觉通路(腹侧)。我们的目标是ACh作为编码信号处理和推理中不确定性水平的反馈信号的作用;我们探讨了这一信号如何调节低层次感觉特征的计算和选择,同时也推动了高层次推理的学习。
这些调节原则构成了我们新颖的、可塑结点网络(PNN)架构的核心。我们的PNN有一个层次结构,反映了大脑腹侧通路的两阶段组织,这也是其他感觉通路所共有的,如听觉和视觉定位(背侧)通路。图1提供了分层机器学习系统中选择性可塑性的架构的高层次概述,其中异质层被引入以实现连续的动态,以支持早期层的最佳特征提取和容量分配,同时在后期层实现稳定和连续的学习。以下括号中的数字是指图1中的橙色数字。调控是由不确定性的措施驱动的(1)。通过分析信号(自下而上)和任务要求/奖励(自上而下)得出的不确定性被用来(2)影响早期层的特征提取/选择和后期层的推理。早期各层调制的结果是快速招募网络能力的特定部分(3),而在后期各层,学习被更强烈地调制,以确保稳定性,同时为新的或更新的任务保持适当的可塑性(4):网络的早期各层进行特征提取(反映枕叶皮层),而后期各层计算推断(匹配前额叶和颞叶皮层过程)。一个类似ACH的信号(测量不确定性)动态地调节着网络的计算和学习。我们的网络是异质的:不同层次和类型的节点对调制信号的反应不同。
1.2 普遍方法
终身学习需要不断地适应;无论多少训练都不能使一个网络,无论是生物还是人工的,为它在其一生中可能收到的所有输入做好准备。特别是,持续的学习需要有能力改变网络的参数而不忘记先前的信息(即稳定的学习,也被称为稳定性-可塑性困境[1])。此外,终身学习系统还面临着第二个困境:持续编码新信息的能力需要大量的计算资源,但由于自由参数的数量巨大,非常大的网络是难以优化的。图2说明了深度学习架构情况下的扩展限制。正在进行的研究[2]表明,无论用多少数据来训练深度学习网络,都无法扩展到任意大小。特别是,我们在DARPA的TRACE项目下进行的内部实验表明,一旦一个深度网络超过了最佳规模(图2中的[a]),其学习能力就会随着规模的扩大而急剧下降(图2中的[b])。这意味着,仅仅建立更大的深度网络并向其提供更多的数据,并不足以实现人类水平的学习。相比之下,我们的调制网络只招募其节点的一小部分来优化容量(a),同时携带大的整体容量(b),使其能够克服这个扩展限制。相比之下,终身学习系统必须以更智能的方式管理其计算资源,以实现最佳的容量分配和缓解性能下降。
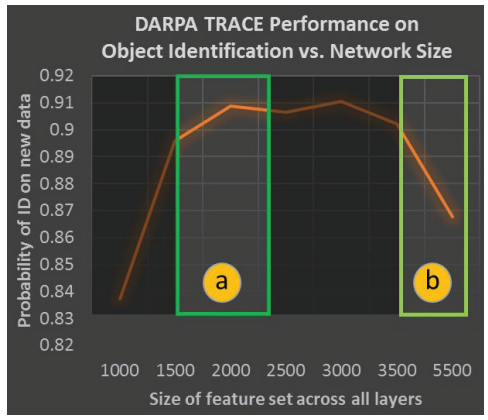
图 2. 深度学习扩展限制
1.2.1 理论工作
我们的基本前提是,大脑通过神经调节来实现这两种能力:利用化学信号不断调节突触活动和可塑性。在神经系统中的许多神经调节剂中,乙酰胆碱是哺乳动物大脑中研究最广泛的一种;它被认为与调节几种高水平的认知功能有关,包括注意力、学习和记忆。更重要的是,ACh调节长期突触可塑性和短期神经活动水平,特别是在腹侧视觉通路(进行物体识别和鉴定)[2]。乙酰胆碱已被证明可以编码不确定性,特别是预期的不确定性[3](以及相关的意外奖励信号[4]),这是触发和调节学习的一个关键反馈信号。特别是在腹腔通路中,乙酰胆碱调节着低层次感觉特征的计算,并驱动着更高层次推理的学习。
作为我们努力的一部分,我们开发了一个分层的、异质的、可塑性结点网络(PNN)算法,称为不确定性调节学习(UML),其中基于神经调节的计算特性使网络的能力得到优化,以允许适应性和稳定性学习(图3)。UML是根据大脑皮层的分层感觉信号分解和推理机制、反馈注意以及对不匹配的期望进行的神经调控来建模的。在UML中,一个类似ACh的信号(由测量的不确定性触发)动态地调节着计算和学习。UML在机器学习方面实现了几个突破性的能力,具体而言:
-
稳定的学习,允许最大限度的更新,而不干扰现有的学习行为(即解决稳定-可塑性的困境)。
- 与自上而下的反馈相结合,使输入和任务的连续和少量的学习与以前学到的信息完全不同
-
最佳的能力分配,只选择和加强那些最大限度地提高信息含量和与当前任务相关的特征。
-
当网络被配置为分层学习时,导致多种计算动机的共存(即UML可以在不同的任务或行为之间复用)。
-
以及每次有选择地招募网络的不同子集,允许它扩展到任意数量的节点(即几乎没有学习新信息的能力)。
-
UML代表了本地异质结构、反馈信号和神经调节作用的一个引人注目的新计算模型。
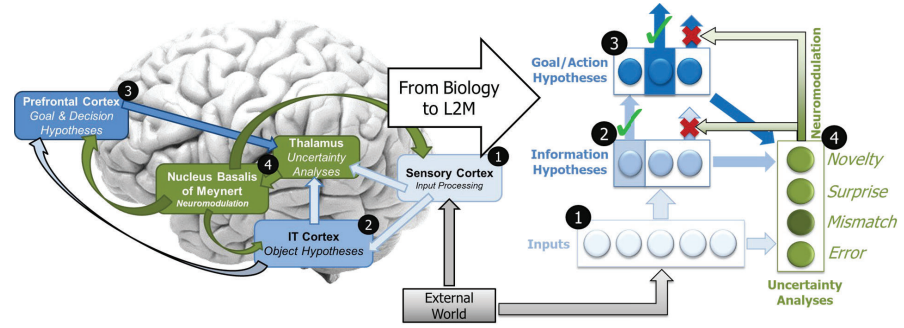
图 3. Teledyne 在 L2M 阶段 1 期间开发的 UML 算法
1.2.2 实验和示范工作
我们的工作展示了算法和一个具有学习机制的集成系统,能够在复杂的学习任务中进行终身学习。此外,我们证明了我们的UML算法能够赋予其他机器学习算法以适应能力,在没有灾难性遗忘的情况下进行学习,并在非正常情况下恢复性能。这些结果的总结将在第1.3节介绍。
在该计划的第二阶段,Teledyne领导了一个系统组(SG),目标是整合一整套终身学习能力。为实现这一目标,Teledyne定义了一套最低限度的相关能力,并与我们的不确定性调制的持续学习范式保持一致(图4,也见第2.2.1节)。该计划第一阶段的两名L2M执行者被邀请加入我们的SG,他们是加州大学欧文分校,与加州大学圣地亚哥分校(UCI/UCSD)和密苏里科技大学(S&T)的研究人员合作。在整个第一阶段,Teledyne开发并演示了感官信号处理算法,该算法采用自下而上的信号分解架构来推断与目标和决策有关的假设(图4中的橙色和蓝色块)。此外,Teledyne开始展示使用注意力机制来调节学习和适应。S&T被招募来利用他们在这个算法系列中的经验,共同实现一个受大脑自上而下注意力机制启发的系统组件(图4中绿色/黄色块)。在与UCI/UCSD的合作中,我们着手研究睡眠启发算法在任务执行后优化记忆和跨任务巩固记忆(即知识)的作用(图4中分别为洋红色和青色块)。
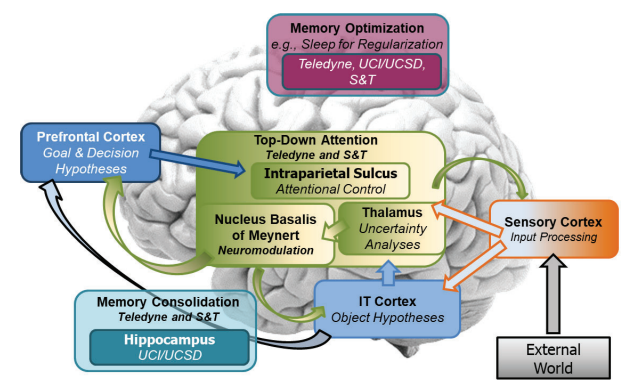
图 4. 基于 SG 成员开发的类脑机制集成的关键 L2M 功能
1.3 成果概述
我们提出的方法的关键前提是,智能生物体测量和识别其环境、输入、约束或目标的关键变化,以使它们能够适应和学习而不需要外部指导(如教师、监督等)。正是通过这种自我监督的监测和评估,一个终身学习的智能体可以在复杂和变化的条件下具备可靠的功能。
通过我们的研究和实验工作,我们确定了在生物智能系统中,测量和跟踪不确定性是触发适应和学习的关键机制。我们的L2M智能体被证明可以适应他们所学的技能或将新的技能纳入他们的剧目,而不会出现灾难性的遗忘。我们还证明了智能体有能力利用以前的技能来提高学习效率(前向和后向转移),在存在干扰任务或条件变化的情况下快速恢复性能,利用样本来适应或获得技能,其效率与单一任务专家相同或更好(见4.1-4.4节)。
最后,Teledyne通过在整个项目第二阶段进行的一系列里程碑式的实验,证明了其综合系统的有效性。这些结果将在第4.5节中介绍,并强调了在计划定义的场景中L2M指标的性能。这些实验有助于在所有L2M SG团队之间建立稳定的节奏和协调的结果,并记录性能方面的进展。此外,我们还利用这些实验来确定我们的系统和/或算法的成功和缺点。对后者的分析被用来优化我们的工作,并适当地关注系统和算法的发展。结果是我们的系统在四个里程碑事件的过程中不断改进,从第一次事件中只达到一个指标,到第四次事件中达到所有五个指标。这些结果也在第5.0节中进行了总结。
1.4 主要结论与建议
我们在整个项目中的工作完成了其主要目标:
-
从神经调节的生物机制中得到启发,得出一个有效的算法
-
实现一种对现有机器学习系统具有广泛适用性的算法
-
使得智能体能够自我监督,不断适应和学习
-
整合一个表现出注意力、基于不确定性的调节、分层学习和睡眠启发的记忆优化机制的系统,以展示终身学习能力
我们工作的一个重要成就是开发了UML,一个新颖的终身学习算法,能够自我监督以适应新的条件,从少数样本中学习,并得出稳健的分层知识表示。最近一个令人振奋的认识是,我们着手研究并在最初提案中提出的关键能力(见表1)不仅完全实现,而且在整个计划的所有实验和演示中得到了彻底的证明。
表 1. Teledyne 方法的特点和优势
| 特点 | 优势 |
|---|---|
| 不确定性调控学习:我们认为,神经调控可以上调对解决两个或多个类别之间的区别至关重要的神经元的学习。 | 证明新任务的学习表示不会覆盖以前学习的任务。 |
| 不确定性调控容量分配:我们建议研究神经调控在上调网络部分的激活和学习中的作用,这些部分可以最佳地解决特定任务并抑制那些无助于减少不确定性的部分。 | 构建具有非常大容量的网络来支持终身学习,同时不会因为只激活网络中最能支持任务性能的部分而导致准确性下降。 |
| 不确定性触发新学习:通过跟踪预期,新算法可以随着时间的推移调整和改进其性能,尤其是在引入新任务或条件时。 | 展示了当响应确定性低于所需阈值时如何触发学习,从而导致系统能够自主检测需要学习的新任务或条件。 |
| 不确定性调控特征提取:跨特征层的信号不确定性测量驱动早期层(特征提取器)中传递函数的调控。 | 实施的算法能够适应特征提取处理以补偿任务、条件或信号属性的变化。 |
在第18个月(M18)的评估中,Teledyne SG显示的结果表明,我们的终身学习者在五个项目指标中达到或超过了终身学习的门槛,在五个指标中的两个指标超过了目标。这在第4.5.1节表11中显示,浅绿色表示某项指标超过了终身学习门槛,深绿色表示某项指标超过了DARPA计划目标。
我们从努力中得到的一个重要启示是,不确定性已经被证明是一个有效的措施,它支持在线学习和创建强大的知识表征,而不需要监督或强化信号。我们还确定,我们开发的L2组件可以有效地集成到现有的ML系统中,以支持提高性能(例如,鲁棒性、适应性等)。因此,存在大量的过渡机会(例子在第2.4节中讨论)。Teledyne将继续通过政府资助的工作、商业努力和内部资助的研究活动来寻求此类机会。Teledyne 也欢迎任何政府机构或个人要求进行讨论,以促进对过渡机会的深入了解或识别。
我们的UML算法被证明是一个有效的组件(第2.3节),不仅适用于一个综合的L2系统,而且可以作为现有机器学习系统的插件。其中包括为决策支持而设计的端到端系统,UML可以监测超出常规的条件或标记需要额外样本或学习的条件。UML还被证明可以支持像基于强化学习的智能体那样复杂的系统在新条件下的性能恢复。由于其轻量级的处理要求,UML可以在一个商品处理器(CPU)上以2000Hz的速度执行,因此适合在许多平台上部署。







