推荐!《基于多智能体学习的任务分配动态邻域优化》2022最新41页综述论文,伦敦国王学院
在大规模系统中,当集中式技术被用于任务分配时,存在着基本的挑战。交互的数量受到资源限制,如计算、存储和网络通信。我们可以通过将系统实现为分布式任务分配系统,在许多智能体之间共享任务来提高可扩展性。然而,这也增加了通信和同步的资源成本,并且难以扩展。
在本文中,我们提出了四种算法来解决这些问题。这些算法的组合使每个智能体通过强化学习改善他们的任务分配策略,同时根据他们过去的经验,改变他们对系统的探索程度,相信他们当前的策略是最优化的。我们专注于分布式智能体系统,其中智能体的行为受到资源使用限制的制约,限制了智能体的本地知识,而不是全系统的知识。我们在一个模拟环境中评估这些算法,在这个环境中,智能体被赋予一个由多个子任务组成的任务,必须分配给具有不同能力的其他智能体,然后执行这些任务。我们还模拟了现实生活中的系统效应,如网络不稳定。我们的解决方案显示,在所考虑的系统配置中,任务分配问题的解决率为理论最优的6.7%。当系统连接受到影响时,它比无知识保留方法提供了5倍的性能恢复,并对多达100个智能体的系统进行了测试,对算法性能的影响小于9%。

引言
在一个分布式任务分配系统(DTAS)中,许多独立的智能体之间存在着相互作用。这些系统越来越多地出现在广泛的现实世界应用中,如无线传感器网络(WSN)[5, 7, 36, 50]、机器人[12, 46]和分布式计算[38, 48]。这些应用的复杂性和范围不断扩大,带来了许多挑战,如应对变化、处理故障和优化等。系统性能也必须随着智能体数量的增长而扩展,能够在计算或存储资源的限制下执行任务。下面总结的挑战在许多不同的学科领域都有,这意味着相关的和实用的解决方案变得更加普遍适用。
任务分配,如何在系统中的智能体中最好地分配任务。一个智能体可能有一个目标,其中包括一个综合任务,需要其他智能体完成一些子任务[70]。
资源管理,分配和优化资源的使用,以完成一项任务。例如,在物理环境中执行一项功能时管理能源的使用[29, 60, 96]。
动态网络、智能体发现和通信适应性。智能体必须能够在连接丢失和创建时相互沟通[6]。
自组织,自主形成结构以完成一个目标。具有刚性结构的解决方案通常不适用于具有许多未知因素的动态系统,因为设计会过于复杂。为了提高智能体在这些情况下的适应性,可以使用自组织的解决方案。[1, 26, 27, 34, 47]。
正式设计的智能体可以在一个被充分理解的系统下执行设定的任务。然而,设计能够预测大规模、真实世界操作环境中可能发生的各种故障或变化的算法通常是不可行的。此外,随着系统变得更加复杂,智能体的状态行动空间大小也呈指数级增长。这个空间代表了它们可能处于的状态组合的集合,以及它们在这些状态下可能采取的行动。在部署智能体之前就知道这个空间往往是不现实的,就像了解哪些算法会有最佳表现一样。引入一个持续更新的关于环境和其他智能体的信息的集中源,可以增加智能体对其状态行动空间的了解,允许更好的优化。像这样的方法,如使用协调智能体,专门协调系统中的其他智能体,在分布式软件架构[39, 41, 49, 66]和机器人学[4, 20]中被使用。然而,在通过集群和共识技术扩展这种方法以增加容错性时,产生了一个脆弱的中心点。由于其他智能体的互动和通信是通过这些中心化的智能体进行的,拥堵和带宽饱和问题也会增加。
具有学习增强功能的分布式智能体系统,如多智能体强化学习(MARL),可以提供相同的功能,但分布在各智能体之间,消除协调的焦点,缓解拥堵问题,同时仍然提供知识共享和行动协调,使智能体能够优化状态-行动空间。虽然随着互动智能体数量的增加,我们看到系统内的通信量呈指数级增长,最终使带宽饱和并耗尽计算资源。还有一个稳定性的期望,即智能体优化的解决方案保持相对稳定,随着时间的推移,对状态行动空间的探索需求逐渐减少。在动态系统中,这一点往往不成立。MARL技术也没有考虑到采取不同类型的行动所涉及的固有风险,这导致了在机器人领域的灾难性影响,如一些行动可能有严重的物理损坏风险,或在金融系统中可能会产生巨大的损失[33, 40, 57, 87]。
整个问题可以概括为如何在动态多智能体系统中提供有效的任务分配,同时随着任务数量的增加和智能体可用性的改变,确保可扩展性。所提出的解决方案结合使用了一些算法,允许智能体确定其他已知智能体执行任务的能力,分配这些任务,并根据其当前的知识和探索智能体能力空间的需要执行其他行动。所介绍的算法有:
具有风险影响意识的智能体任务分配(ATA-RIA)算法允许每个智能体选择系统中其他智能体的一个子集,其依据是它预测这些智能体将在多大程度上帮助完成其整体综合任务的子任务。他们可以学习这些智能体的最佳任务分配策略,但也可以改变哪些智能体组成的小组来提高性能。
行动-风险概率的奖励趋势(RT-ARP)算法使智能体有能力根据一段时间内获得的奖励趋势来改变他们的探索策略。使用这种算法,智能体可以根据他们的历史表现,增加他们采取有可能对其任务分配策略进行较大改变的行动的可能性。
状态-动作空间知识-保留(SAS-KR)算法智能地管理智能体用来维护他们所学到的关于状态-动作空间的信息和他们的行动效果的资源。
邻居更新(N-Prune)算法有选择地将智能体从一个智能体考虑的任务分配组中删除,以限制资源的使用。这种选择不仅基于一个智能体预测其他智能体对其综合任务的贡献有多大,而且还基于它对这种预测的不确定性有多大,因此与ATA-RIA算法的行为相得益彰。
我们通过评估这些算法在一系列模拟的多智能体系统中的表现来测试其有效性。
提纲
第2节涵盖了MARL和多智能体系统领域的相关研究。第3节对问题领域和动机进行了深入分析,第4节和第5节对提出的解决方案和算法的定义进行了探讨。我们在第6节中介绍了在系统模拟中对算法性能的评估。最后,我们在第8节中讨论了结论和未来的研究。
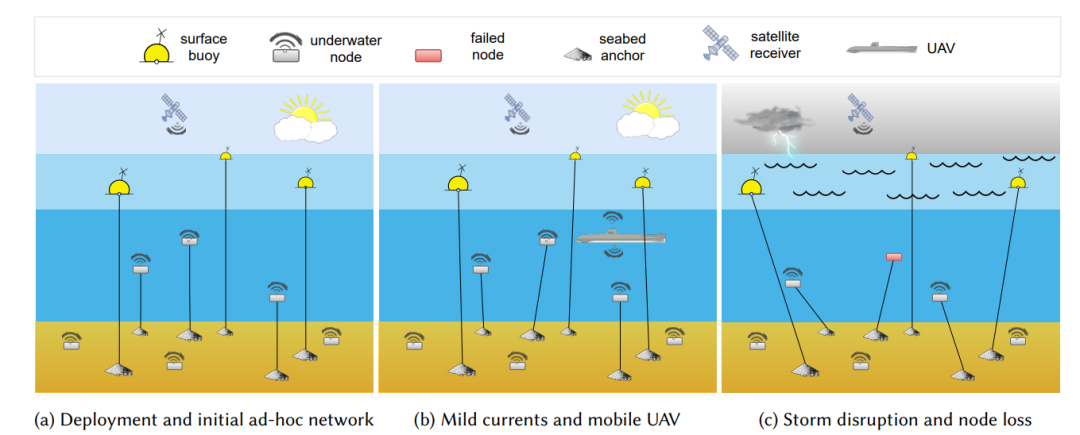
图 8. 一个常见级别 WSN 系统示意图。在图 8a 中,部署了节点并学习了初始任务优化。在图 8b 中,ATA-RIA 调整节点的动作以考虑由于电流和通过无人机的运动。在图 8c 中,节点被高度中断,一些节点出现故障。SAS-KR 和 RT-ARP 算法可根据过去的知识和环境稳定时的探索优先级快速重新建立最佳配置。
便捷下载,请关注专知人工智能公众号(点击上方关注)
点击“发消息” 回复 “DTAS” 就可以获取《推荐!《基于多智能体学习的任务分配动态邻域优化》2022最新41页综述论文,伦敦国王学院》专知下载链接



