推荐!【自适应学习、知识表示】《通过主动神经调节进行自适应学习 (ALAN)》美国空军研究实验室2022最新84页项目报告
报告总结
1.1 项目计划概述
1.2 普遍方法
1.2.1 理论工作
-
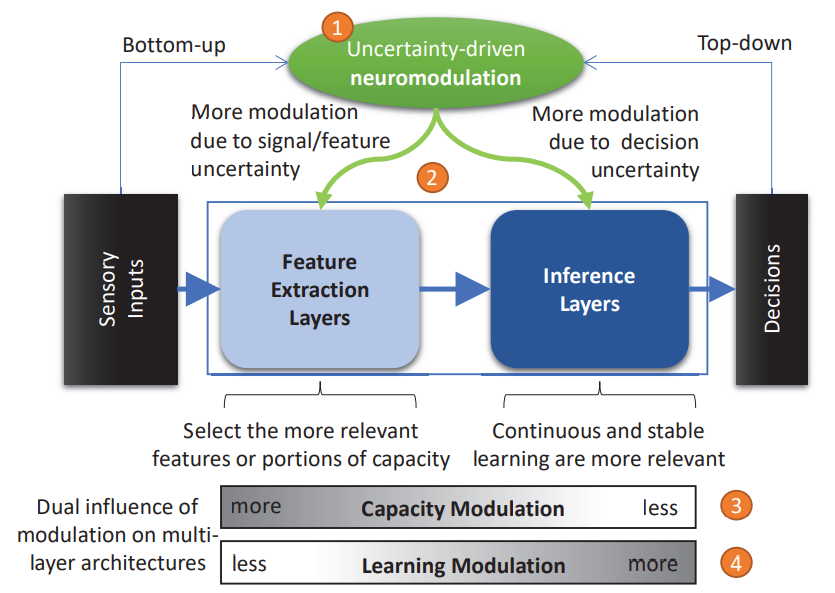
稳定的学习,允许最大限度的更新,而不干扰现有的学习行为(即解决稳定-可塑性的困境)。 -
与自上而下的反馈相结合,使输入和任务的连续和少量的学习与以前学到的信息完全不同 -
最佳的能力分配,只选择和加强那些最大限度地提高信息含量和与当前任务相关的特征。 -
当网络被配置为分层学习时,导致多种计算动机的共存(即UML可以在不同的任务或行为之间复用)。 -
以及每次有选择地招募网络的不同子集,允许它扩展到任意数量的节点(即几乎没有学习新信息的能力)。
1.2.2 实验和示范工作
1.3 成果概述
1.4 主要结论与建议
-
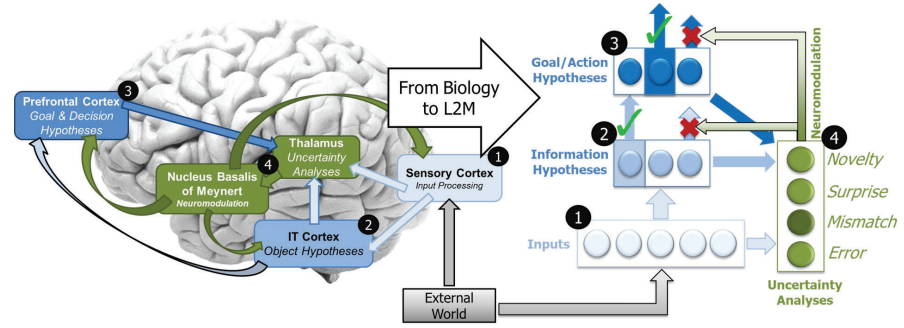
从神经调节的生物机制中得到启发,得出一个有效的算法 -
实现一种对现有机器学习系统具有广泛适用性的算法 -
使得智能体能够自我监督,不断适应和学习 -
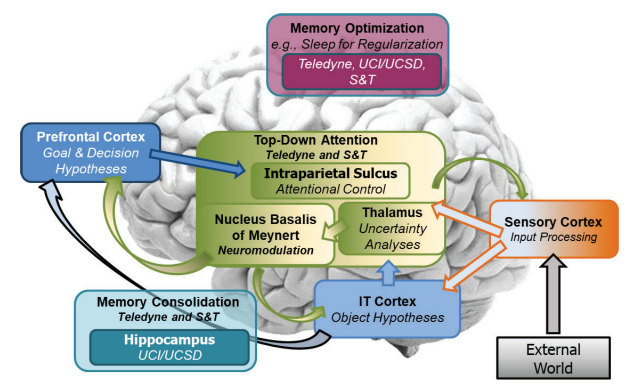
整合一个表现出注意力、基于不确定性的调节、分层学习和睡眠启发的记忆优化机制的系统,以展示终身学习能力
| 特点 | 优势 |
|---|---|
| 不确定性调控学习:我们认为,神经调控可以上调对解决两个或多个类别之间的区别至关重要的神经元的学习。 | 证明新任务的学习表示不会覆盖以前学习的任务。 |
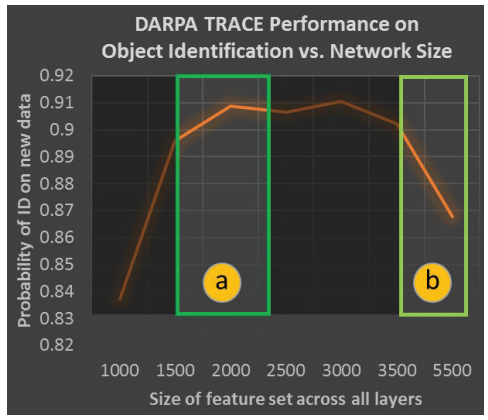
| 不确定性调控容量分配:我们建议研究神经调控在上调网络部分的激活和学习中的作用,这些部分可以最佳地解决特定任务并抑制那些无助于减少不确定性的部分。 | 构建具有非常大容量的网络来支持终身学习,同时不会因为只激活网络中最能支持任务性能的部分而导致准确性下降。 |
| 不确定性触发新学习:通过跟踪预期,新算法可以随着时间的推移调整和改进其性能,尤其是在引入新任务或条件时。 | 展示了当响应确定性低于所需阈值时如何触发学习,从而导致系统能够自主检测需要学习的新任务或条件。 |
| 不确定性调控特征提取:跨特征层的信号不确定性测量驱动早期层(特征提取器)中传递函数的调控。 | 实施的算法能够适应特征提取处理以补偿任务、条件或信号属性的变化。 |




便捷下载,请关注专知人工智能公众号(点击上方关注)
点击“发消息” 回复 “ALAN” 就可以获取《推荐!【自适应学习、知识表示】《通过主动神经调节进行自适应学习 (ALAN)》美国空军研究实验室2022最新84页项目报告》专知下载链接



登录查看更多
相关内容

专知会员服务
136+阅读 · 2022年11月23日
专知会员服务
32+阅读 · 2022年10月21日
Arxiv
0+阅读 · 2023年2月2日


相关VIP内容
专知会员服务
136+阅读 · 2022年11月23日
专知会员服务
32+阅读 · 2022年10月21日
相关资讯