

这项工作的目的是开发能够成功处理复杂动态环境中顺序决策的深度终身学习方法,重点是多Agent情报、监视和侦察(ISR)场景。我们为深度卷积神经网络开发了一个新的架构,支持通过去卷积因子化的终身学习(DF-CNN),探索了通过Distral和Sobolev训练的策略提炼的组合,并开发了一个混合控制器,将深度学习应用于ISR智能体。我们的方法在标准基准深度学习数据集、DOOM环境和ATE3模拟环境中的ISR场景中进行了评估。
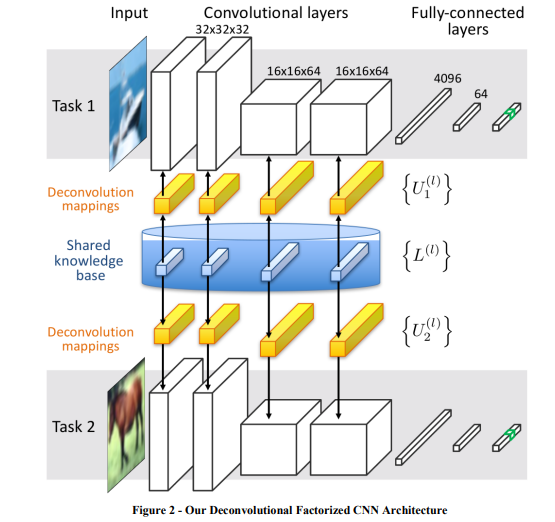
我们的主要贡献是反卷积因子卷积神经网络(DFCNN)。DF-CNN框架调整了标准卷积神经网络(CNN)框架,以实现任务之间的转移。它在每个CNN层维护一个共享知识库,并通过这个共享知识促进不同任务的CNN之间的转移。每个具体任务的CNN模型的各个过滤层都是由这个共享知识库重建的,随着网络在多个任务中的训练,这个知识库会随着时间的推移而调整。DF-CNN代表了ELLA终身学习框架对深度网络的概括。
实验表明,DF-CNN在终身中的基准识别任务上的表现优于其他方法(包括单任务学习、低层的硬参数共享和渐进式神经网络)。此外,该框架能够抵抗灾难性遗忘,同时仍然允许从未来的学习中反向转移到以前学习的模型。
对于深度强化学习,我们研究了将Sobolev训练整合到Distral多任务框架中,以努力改善转移和训练,探索了DF-CNN在深度RL中的应用,并开发了一个混合控制器,将本地学习的深度RL策略结合在一起,在ATE3仿真环境中完成ISR场景。
成为VIP会员查看完整内容
相关内容

Arxiv
0+阅读 · 2022年9月9日
Arxiv
0+阅读 · 2022年9月7日
Arxiv
0+阅读 · 2022年9月6日
Arxiv
11+阅读 · 2019年9月23日

相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年9月9日
Arxiv
0+阅读 · 2022年9月7日
Arxiv
0+阅读 · 2022年9月6日
Arxiv
11+阅读 · 2019年9月23日