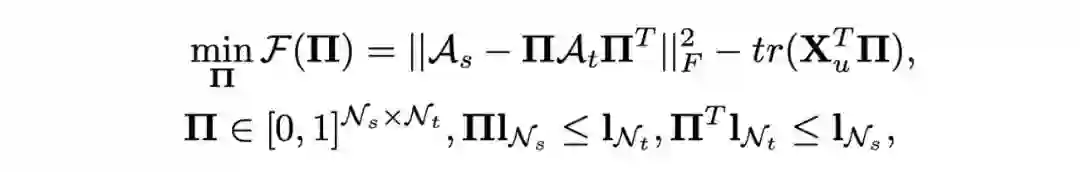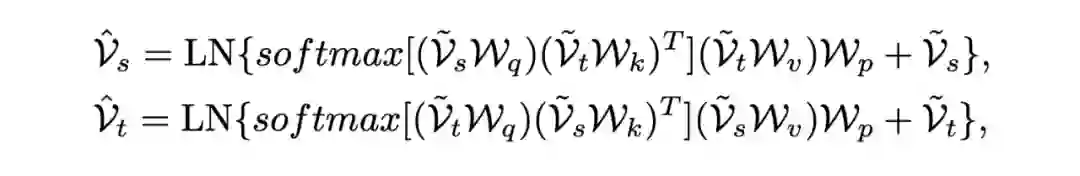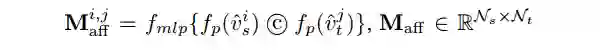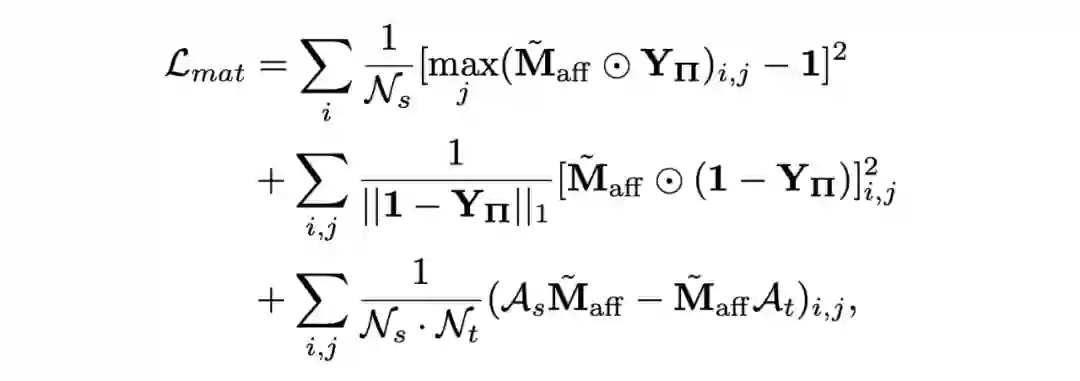SIGMA: Semantic-complete Graph Matching for Domain Adaptive Object Detection
论文链接:
https://arxiv.org/abs/2203.06398
项目链接:
https://github.com/CityU-AIM-Group/SIGMA
本文介绍我们的工作:SIGMA: Semantic-complete Graph Matching for Domain Adaptive Object Detection。其实主要有两个目的:
1)希望能分享自己在做本工作的一些思考,起到抛砖引玉的效果。2)希望能解释下本工作一些可能引起困惑的地方,帮助大家更好的了解本工作的思路。 对于一些个人理解的浅薄、错误之处,也欢迎大家指出,互相学习(本文章会继续更新)。同时,
欢迎感兴趣的伙伴加入我们的 AIM Group,我们组招多个 Postdoc 和 RA。
序言
Prototype 这个词相信大家都不陌生,作为一种面向“中心” 的“描述子”,已经被广泛应用到各种基于机器学习的视觉任务,其核心思想可以抽象为:用少量归纳的知识描述或建模 大量样本的分布特性 ,进而服务于下游任务。个人感觉,这类工作可以由四个“变量”共同决定:
1)数据层次: 这种思想可以应用于各种层次的样本,比如从一张图片的像素集,到一个 domain 的样本分布等。2)定义方式: 这种基于中心的定义方式有很多,比如样本点的均值、质心等。3)更新/学习方式: prototype 的学习与更新方式有很多,比如去年比较流行的 momentum。4)下游任务: 有了 prototype 我们怎么服务于特定的任务(比如对于跨域的对齐 prototype,X-shot 的用 prototype 索引,或者单纯为了表征学习)。通过以上四个变量的“赋值”,诞生了很多好文章。
但是,有利必有弊,这种人为的归纳建模 必定会损失一些对分布的感知能力 ,一个最直观的例子是 LeCun 在今年 ICLR
[1]
引入一个简单 variance 正则 。目前可以感受一个现象:很多任务在引入各种 fancy 的 prototype 设计后,性能虽然提升显著,但是也似乎逐渐进入了瓶颈。尤其是对于泛化相关的工作(X-shot, domain相关, semi-supervised ...),很多时候一个“宽松的(var 大一些)”分布要比 “紧凑”的分布性能更好, 而这种“宽松”往往是 prototype 很难去直接做的。这也就让我们思考能不能引用其他的建模方式 来保持更好的分布的感知能力,并足够服务于我们的任务?
背景,核心思想,以及Graph Matching科普
2.1 背景
在 Domain Adaptive Object Detection 的领域背景下(就是把 UDA 任务放到目标检测上),一类常用的做法是利用大量的 region proposal 建模 prototype,进一步根据 metric learning 实现 prototype-based 的对齐 (数据层次 = bounding box,定义方式 = 特征均值 / graph aggregation,更新方式 = online,下游任务 = 域对齐 )。通过对不同类的 prototype 建模、拉近,进而实现对齐 Class Conditional Distribution(CCD), 这个过程可以换一种表述:强化网络对跨域的两种类别中心的 affinity 感知能力。
对于这种对齐方式,其具有两个弊端:1)正如在序言中讨论的,会损失一定的分布感知能力 (这个引用文章
[2]
在补充材料里给了一个非常好的 toy example),2)这种 prototype 建模是依赖样本的,如果“猫”这个目标在某个域里没有出现,那么我们就没法估计当前 batch 的 prototype,这是本文中提到 semantic mismatch。
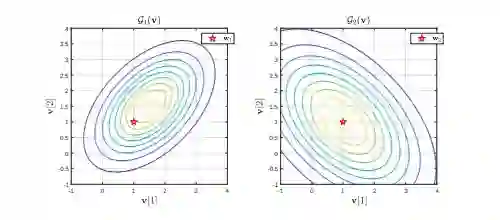
▲ 两个垂直椭圆的toy example [2] 可视化问题1)的情况
2.2 核心思想
于是,我们思考的是如何舍弃 prototype 建模方式,而是直接基于样本实现域对齐 ,同时解决上述两个弊端 ?这也就引出了我们这篇文章的核心思想:用 Graph 来建模一种新的范式。根据 “把大象装到冰箱里”的三步走原理,我们的思路如下:用 graph 取代 prototype 建模,补全类别 mismatched 的节点,进一步用 Graph Matching 实现对齐。
如果说 prototype+metric learning 是优化网络在让 domain A 的猫的 protoype 能自主匹配到 domain B 的 猫的 protoype 的能力 ,那么 GM 可以用来优化让网络对在 domain A 的 {猫头,猫尾,猫鼻子,猫嘴...} 能自主匹配到 domain B 的 {猫头,猫尾,猫鼻子,猫嘴...} ,不同之处在于,protoype 是人为设计的,而 node 可以是 dense 的 raw 的,保持最原始的分布情况 (这里举的例子中,猫的各个部位实际上是有基于 GCN 的信息交互的,而不是独立的)。
2.3 什么是Graph Matching?
简单来讲,Graph Matching 解决两个图之间的一对一匹配 问题:图 A 的节点 M 应该与图 B 的哪个节点匹配? 这种匹配关系用分配矩阵
表示,横和纵分别代表 图 A 和图 B 的节点 index,
代表图 A 的 i 节点 匹配到图 B 的 j 节点 ,否则为 0。公式表达如下:
这个公式可以简单理解为:第一项希望匹配上的两个节点在各自图的局部邻居 尽可能相似(如果图 A 的节点 M 与图 B 的节点 N 匹配上了, 那么节点 M 在图 A 的局部连接与节点 N 在图 B 的局部连接 也应该相似,Structure Affinity ),第二项是希望匹配上的两个节点本身的 embedding 是相似的,也就是 Node Affinity (optimal transport 主要做第二项)。
方法介绍
我们的方法其实就是跟随上述的三步流程按部就班地把想法实现:
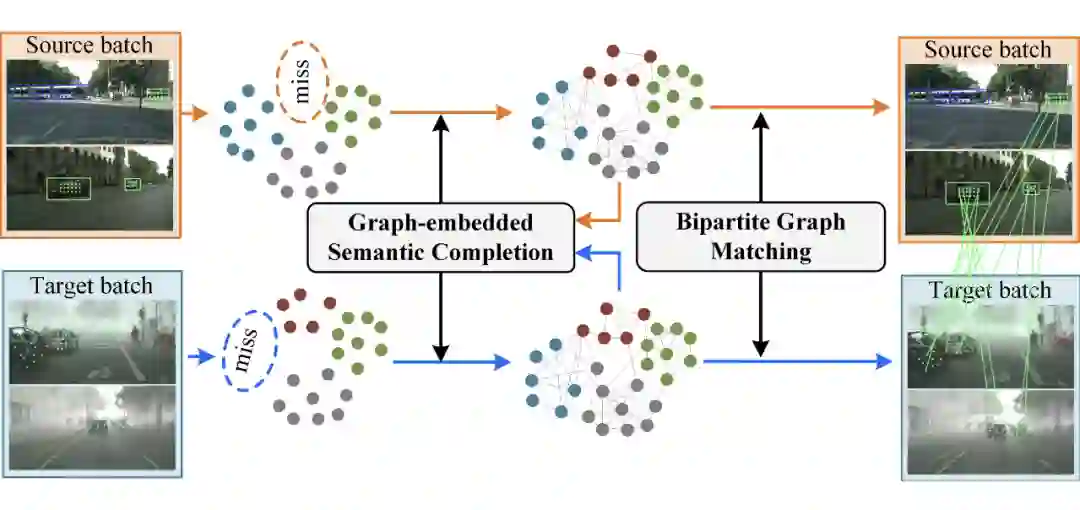
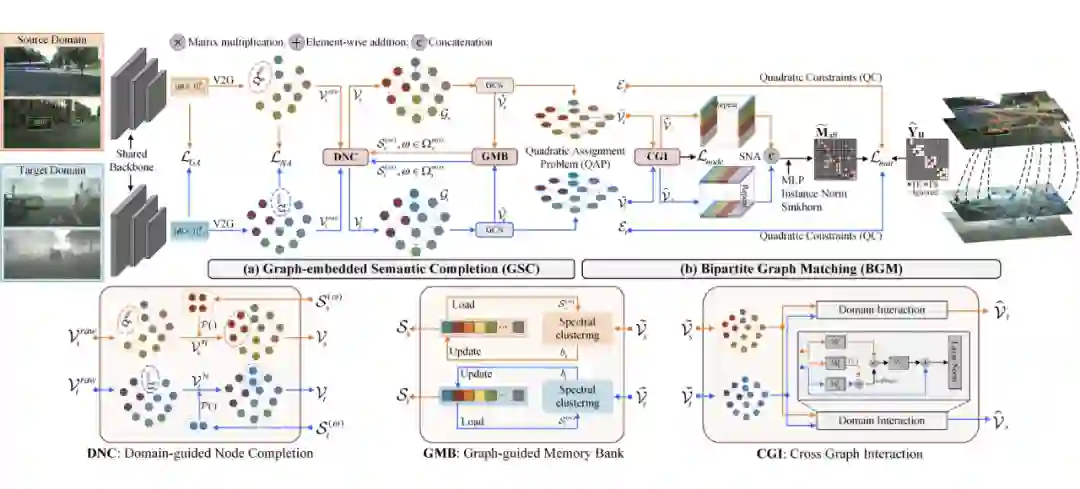
▲ SIGMA 的整体框图:主要包含 GSC和 BGM 两个部分,GSC 负责建图并补全 mismatched 的类别信息,BGM 负责匹配与 DA
3.1 节点采样
我们的核心目标是对齐,那么我们首先需要想办法得到一些样本(毕竟分布依赖于样本而产生),于是我们选择了最直接的方式:对于源域 ,我们把 ground-truth 的 bounding box 映射到特征层,直接在物体内部采一定数目的 feature point,同时,我们在物体外侧均匀采一些背景点。对于目标域 ,我们直接基于检测头得到的 prediction (考虑到 sigmoide 的激活特性,我们设置了很低的 0.5 阈值)正采样,同时用 0.05 采样一些背景点(熟悉检测的小伙伴应该知道几乎所有检测器最后都用 0.05 卡阈值)这里的实现是基于 FCOS 的 point 分配
github.com/CityU-AIM-Gr
。为了便于优化,我们尽可能控制采样节点数目在近似的数量级。之后我们过了一个映射层 ,把 feature point 映射为 node embedding ,值得注意的是 ,我们直接得到的 feature point 的数值范围是 [0,+INF)由于ReLU, 这个映射是为了扩大数值范围(-INF,+INF)。
3.2 节点补全
由于每个 batch 的数据是随机采样 的,很容易出现某个类别只在一个 domain 中出现,于是我们的做法是想办法产生一些节点来补全丢失的语义信息(文章中叫做hallucination node)。简单来讲,我们设置了一个 bank 存储每个类别的均值 (GMB),之后根据该均值以及另一个域的方差产生等数目的节点。(毕竟这种方差信息很不稳定,而且随着训练过程变化,选取对立域的方差主要是为了至少保证 语义空间 处于相似的训练阶段 )
3.3 建立图结构
其实到目前位置已经没有 image-batch 的概念了,我们得到的是两组节点集合,这两组集合有以下特别好的性质:1) 因为我们的有针对性的采样方式 ,这些节点很强的语义表达能力 ,2)类别信息是匹配的 , 3)突破了图像的 Grid 空间约束 ,也就信息的传递是说不再是 NxN 的网格形式 ,而是可以跨像素、跨 image 递。于是顺理成章地我们用一层 GCN layer 进行了长距离的语义传递。考虑到进行这次 Graph 传递后我们的语义表达得到了很大的升华,我们用新的 node embedding 去更新之前提到的 bank 。
到此为止是我们第一个贡献点:Graph-embedded Semantic Completion,建模每个域各自的模型。目前我们已经有两个建立好的图,这两个图分别建模两个域的语义分布,我们下一步是怎么利用两个图的匹配实现 DA,也就而是 Bipartite Graph Matching。
3.4 跨图交互
我们首先利用 attention 的机制先建立起两个图之间dense的信息交互,(其实这个我们是 follow 一系列 Graph Matching 的先人工作),让每个节点首先具备一定的跨域感知的能力。这里也可以看作遵循从 dense 到 sparse 的过程
[3]
:attention-based dense 以及 GM-based sparse matching。
3.5 Node Affinity 学习
这里对应 Graph Matching 的公式的第二项,主要是利用节点本身的 affinity 建立matching 矩阵,并用一层 MLP 将 affinity 编码成 GM 的分配形式,配合Sinkhorn 优化得到一个初始的分配矩阵。
3.6 Structure-aware Matching Loss
这里是文章核心的优化目标,一句话概括是:对于图 A 中的节点 M ,我们希望网络在图 B 中找到最匹配的一个同类别的节点 N,强化这些dense节点之间的 pair-wise sparse 感知能力(dense 指的是节点数目相比单个 prototype 是 dense 的,sparse 指的是 Graph Matching 给予的是一种一对一的 sparse 匹配) 。
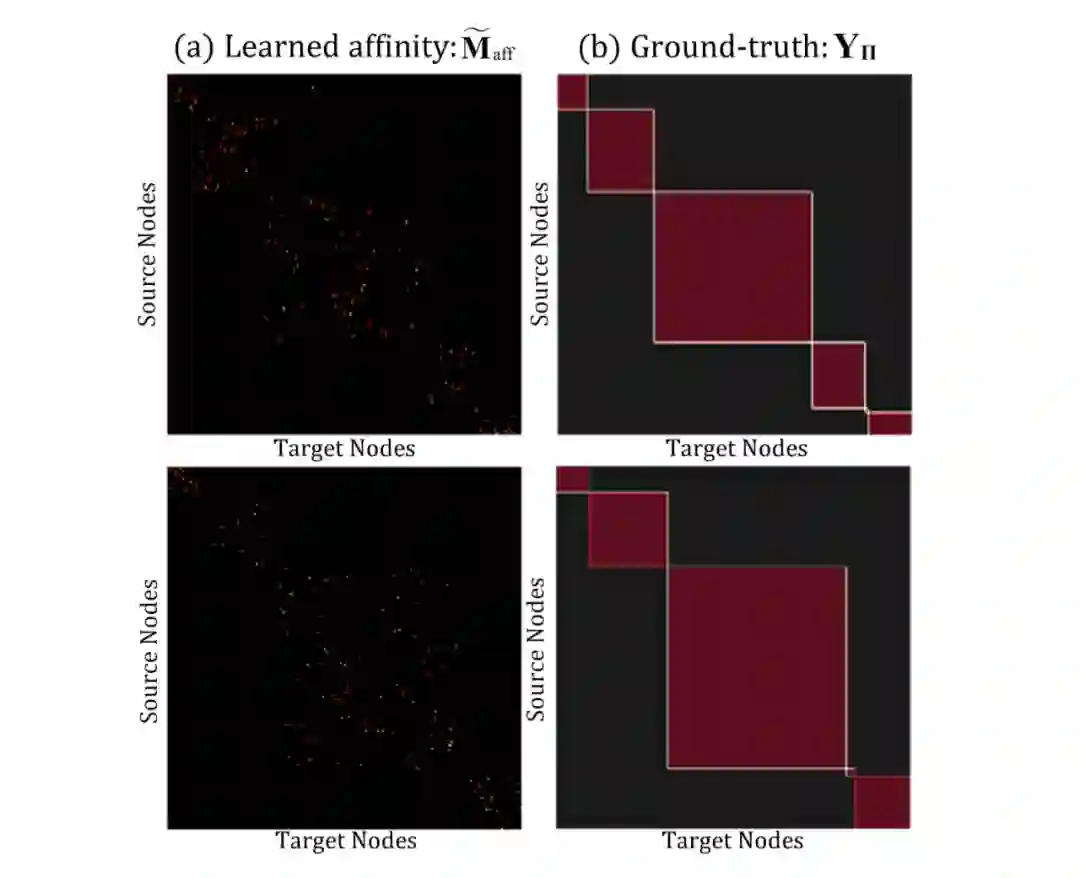
然而,最大的困难是我们其实并不知道究竟哪一个同类节点是对 DA 最合适的,我们只知道这一堆节点可能是同类的 。于是就有了下面这个 loss 的设计:这个 matching loss 包含三个项,第一项是去优化响应强度(TE) :也就是让网络最确信的同类匹配更加确信,第二项是惩罚错误的匹配(FS) 如下图所示,第三项是把 edge 信息引进来实现 Graph Matching 公式的第一项正则 。
简单来说:强化大概率正确的、最确信的匹配(TE);抑制错误的匹配(FS);对于属于可能正确的其他匹配我们直接 Ignore 。这里的优化方式其实跟 Faster RCNN 的 anchor loss 设计有点相似:对于 pos (IoU>0.7) 和 neg (IoU<0.3) 的产生各自的正负监督,对于其他的直接 ignore 。
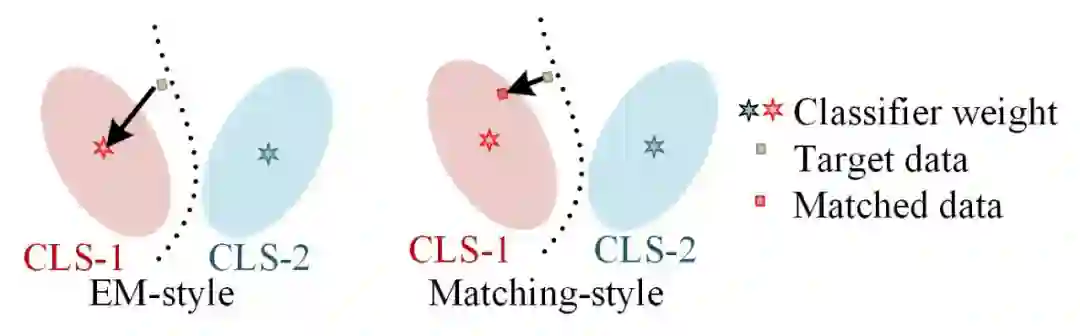
读到这里,肯定会有疑问matching loss实际上是怎么实现的对齐? 熟悉 UDA 的小伙伴应该知道,对于分类任务,Entropy Minimization(EM)是一个常见的做法,主要是在没有语义标签的情况下,利用 EM 让分类 task “对的更对,错的更错” ,而 Matching 实际上是建立了一个“是否 match 到同类别”的 proxy task, 我们的优化目标是基于这个 proxy task 的 EM,两种方式的对比如下:类别的 EM 是拉近样本与类中心的距离,Mactching 是拉近样本与匹配样本的距离(有点 contrastive learning 味道了)
可视化出来学习结果如下图所示(注意:我们在工程实现上为了方便,将节点进行了按照类别从 1 到 K 进行排序,这就导致我们的分配矩阵长成这种规规矩矩样子:
github.com/CityU-AIM-Gr
)
3.7 其他的设置
考虑到 GM 在实现 p(x|y) 的对齐,我们针对节点又加了一个 p(x) 的节点判别器(MLP-based),这个不是必须的。我们发现这条 graph 分支由于 Attention 的存在,很容易在训练后期 bias 到 noisy 样本
[4]
,也就是先到上升再下,我们最终加了这个判别器解决了这个问题,当初研究了好久想通的。。。。。
实验
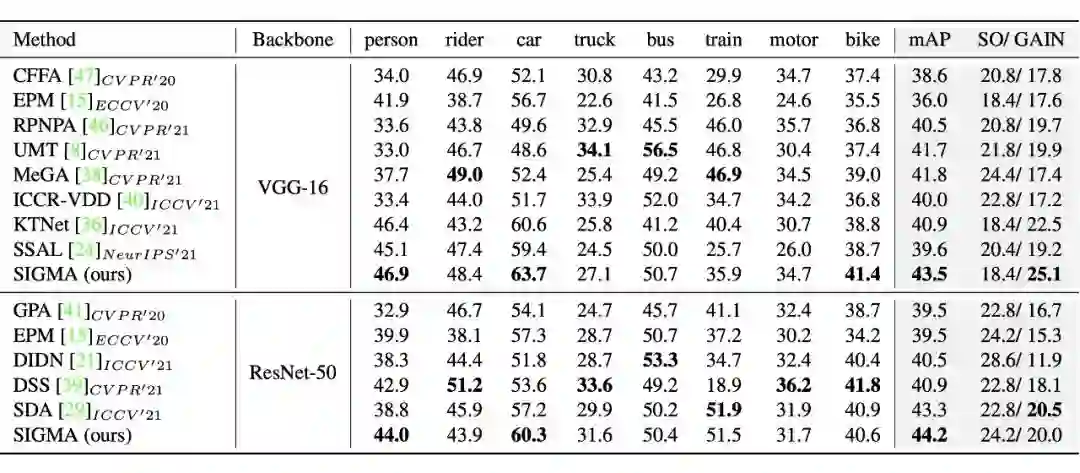
关于实验方面,我们发现新方法已经远超过我们的前身工作 SCAN(AAAI'22 ORAL)的性能 。
GitHub-CityU-AIM-Group/SCAN: [AAAI' 22 ORAL] SCAN: Cross Domain Object Detection with Semantic Conditioned Adaptation
SIGMA 汇报的性能是 warmup 双阶段训练的 ,我们后续发现完全可以端到端训练 ,而且还可以达到更高的性能 ,这个框架的潜力还大大有待发掘。另外,我们放几个比较有趣的实验结果:
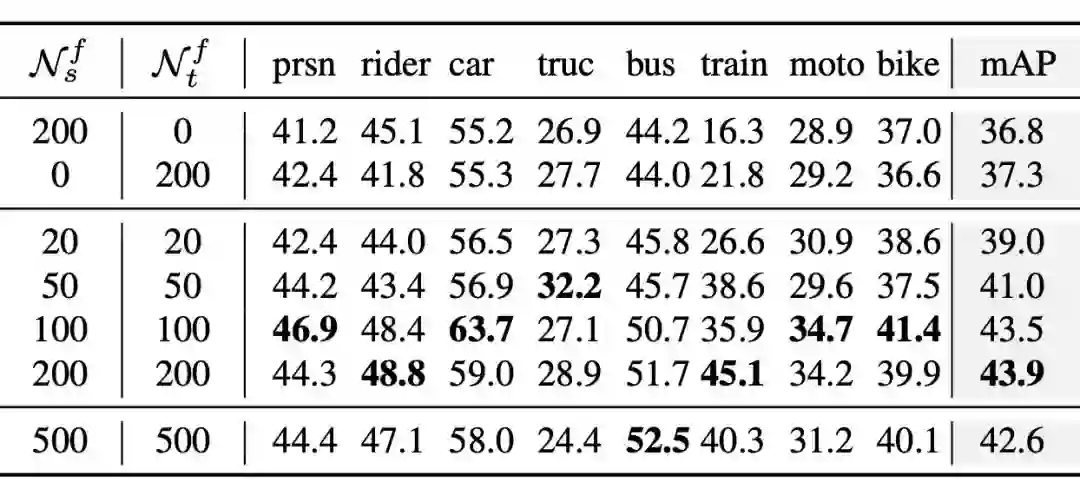
4.1 节点数目的探索
我们用更多的节点能进一步提升性 能,但是考虑到对匹配优化的计算量有指数倍需求,我们并没有用更多节点。
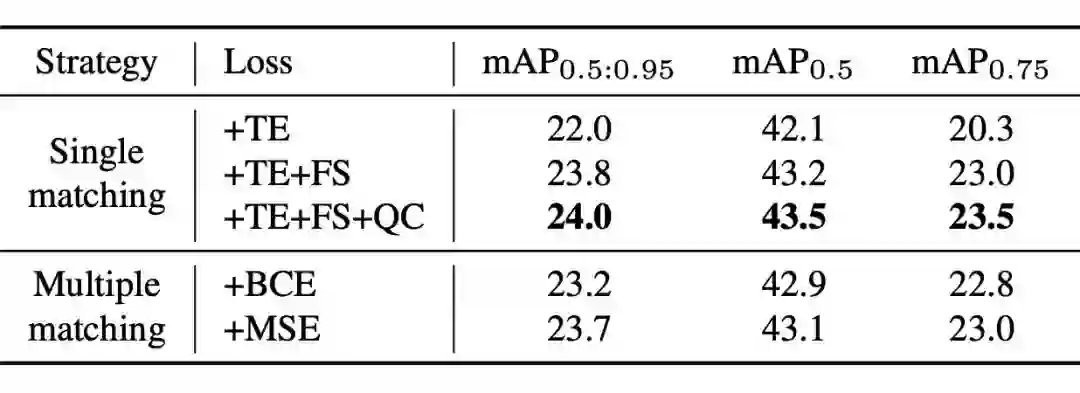
4.2 方式的探索
我们发现 one-to-one 的优化方式竟然比 many-to-one 的好一些,感觉有两个原因,一是文章中说的 Noisy 的问题 ,二是可能是 constrastive learning 和 supervised learning 之间的优化目标的角逐 。
4.3 对检测性能的直观提升
其实最直观的是对判别的提升:比如减少一些 FP 样本以及 FN 漏检 。
总结
本文提出了一种基于图匹配的 DAOD 框架。随着基于 patch 的 transformer 的潜力被不断挖掘,Graph 的潜力也逐步体现出来,
个人感觉 Graph 的优势不在于多么 fancy 的图卷积设计,而在于如何更巧妙的突破传统卷积的 local 局限(类似 transformer),同时一些 Graph 领域的积累(比如图匹配)似乎也能推动对 CV 的发展。 希望我们的 SIGMA 能够激发更多有趣的想法 ,共同推动这个领域的进步。同时,对于文章的内容也欢迎讨论。
[1] Bardes, A., Ponce, J., & LeCun, Y. (2021). Vicreg: Variance-invariance-covariance regularization for self-supervised learning.arXiv preprint arXiv:2105.04906.
[2] Cheng, J., & Vasconcelos, N. (2021). Learning deep classifiers consistent with fine-grained novelty detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(pp. 1664-1673).
[3] Min, J., & Cho, M. (2021). Convolutional hough matching networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(pp. 2940-2950).
[4] Yang, X., Zhang, H., Qi, G., & Cai, J. (2021). Causal attention for vision-language tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(pp. 9847-9857).
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读 ,也可以是学术热点剖析 、科研心得 或竞赛经验讲解 等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品 ,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬 ,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱: hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02 )快速投稿,备注:姓名-投稿
△长按添加PaperWeekly小编
🔍
现在,在「知乎」 也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」 订阅我们的专栏吧