CVPR 2019提前看:少样本学习专题
机器之心原创
作者:Augulia Chao
编辑:Hao Wang
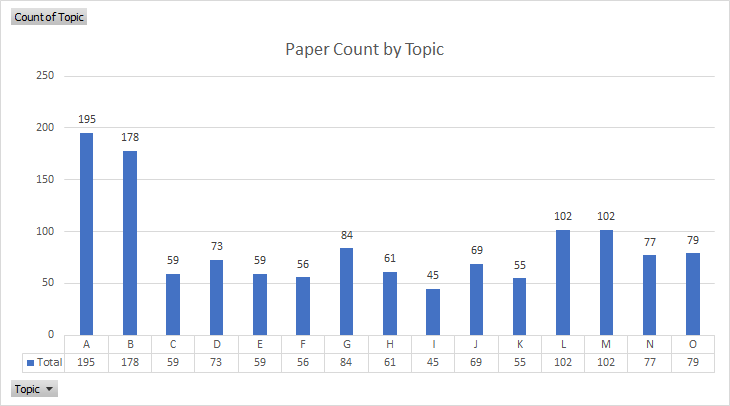
CVPR 2019 年共收到了 5165 篇有效提交论文,比去年 CVPR2018 增加了 56%,论文接收方面,本届大会共接收了 1300 论文,接收率接近 25.2%,截止本文截稿前统计共有 288 篇 Oral 论文。我们根据所有接收论文的细分方向做了一个柱状图供读者参考,可以看到深度学习,识别相关的论文仍然占有较大比例。
本文选择深度学习细分种类下的少样本学习(Few-Shot Learning)这个话题。近两年来我们注意到学界开始改变之前大数据好效果的模型训练方式,关注用少量的数据来达到较好的任务表现,目前此类方法还处在学界探索实验阶段,在业界运用还不算普及(由于业界产品对模型精确度有比较高的要求,且大多针对的都是特定业务细分场景),然而该方向『小数据学好模型』的思想对之后的机器学习研究和应用都具有非常好的前景以及应用潜力,所以笔者今年挑了四篇思路和方法都比较新颖,同时结果也具有说服力的少样本学习的文章进行了比较细致的引读和推荐,文章内容涵盖物体分类、物体检测任务,以期给关注这个方向的读者更多的启发。
由于篇幅有限,在详细介绍的四篇论文之外,我们还准备了几篇同样非常新颖的少样本学习工作做了简略的介绍,这部分文章涉及图像检索,人脸反欺诈,长尾数据分类等任务,最后我们将筛选的本届 CVPR 接受的几篇少样本学习或者相关的半监督学习文章的原文和名称都附到了文章末尾供读者参考。
分类任务上的少样本学习
1.Edge-Labeling Graph Neural Network for Few-shot Learning(classification)
paper: https://arxiv.org/abs/1905.01436
code: https://github.com/khy0809/fewshot-egnn
图网络(Graph Neural Network, GNN)由于节点与节点之间具有相关性可以实现更丰富的信息传递,在近期来涉及到的推理问题(Reasoning)或者是视觉问答(Visual Question Answering)等任务上都有不少的尝试,而少样本学习(few-shot learning)的难点通常是在于可用样本有限,所以样本之间潜在的关联性在学习过程中就变得非常重要了,通用的前传网络很难捕捉到样本之间丰富的关联信息,图网络正好可以弥补这一点:图网络在节点之间构建的丰富的连接,使得其能够利用节点之间的信息传递机制得到邻节点的信息并且进行聚合,通过一定复杂程度的图网络,就能够表达数据个体之间丰富的关联互动特征。
常见的图网络关注于节点的表示与特征嵌入,为了更充分的利用节点的关联信息,本篇论文提出了边标记图网络(Edge-Labeling Graph Neural Network,EGNN),类比于关注节点信息的 GNN,EGNN 通过迭代更新连接边的信息直接可以反映节点之间的类内相似度(intra-cluster similarity)与类间差异度(inter-cluster dissimilarity)从而获取正确的类别分配结果。另一方面,EGNN 在无需 re-train 的情况下能很好地适应不同数目的类别,并且很容易扩展到转换式推理(Transductive Inference)上面,同时在现有的 GNN 方法中,EGNN 在分类任务上实现了大幅的性能提升。
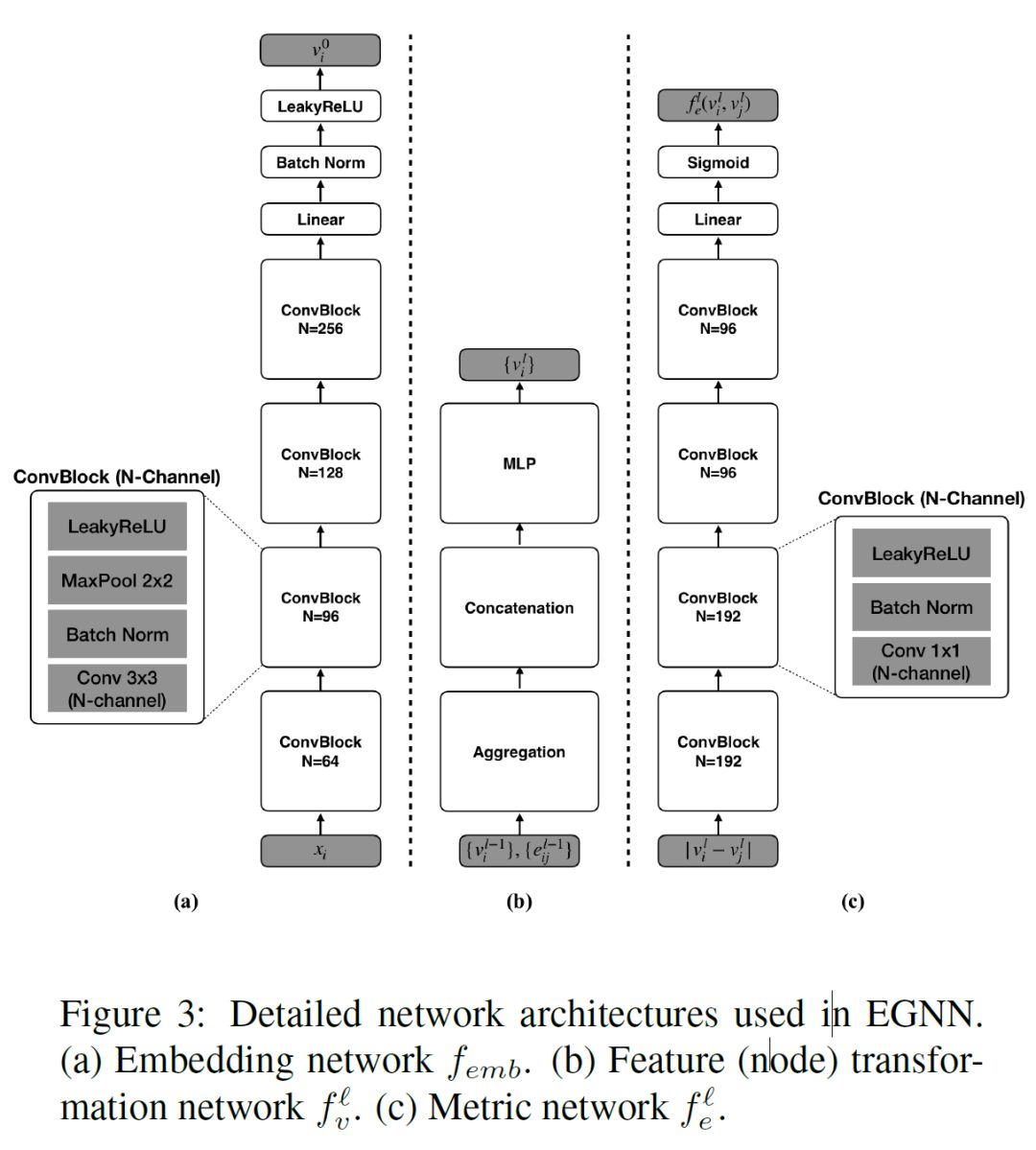
在完整观察 EGNN 结构之前,我们先理解 EGNN 里的节点与对应的连接边信息的基本更新方式:
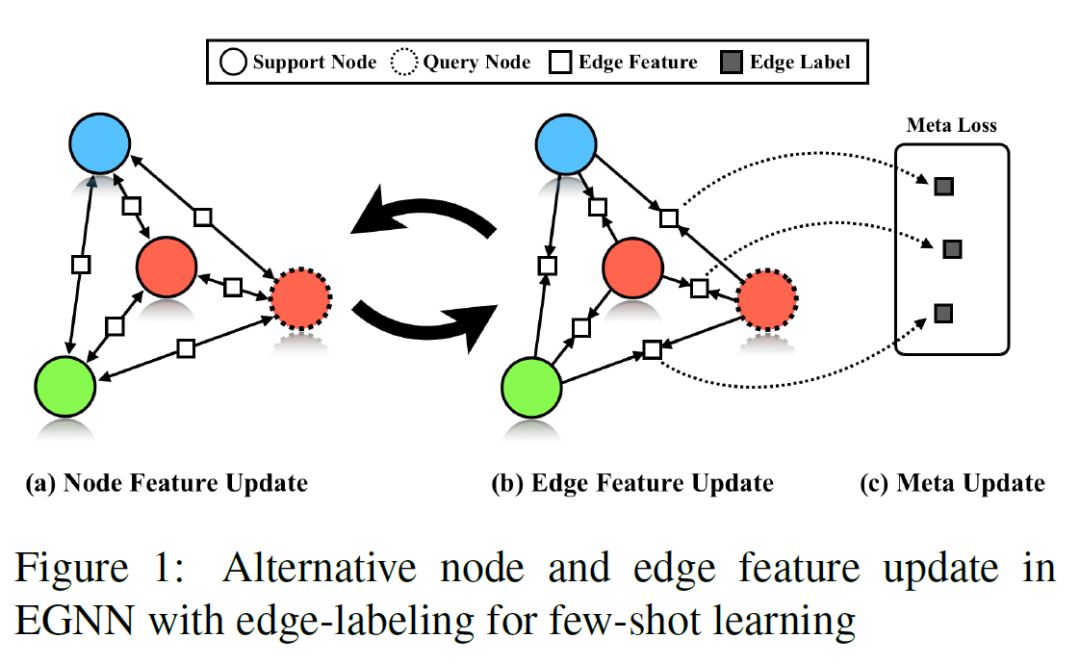
在图中首先更新节点特征,之后再更新节点之间连接边的特征,因为一组节点的特征有变化,进而也会影响到连接边上的特征,以及衡量节点之间的类内相似度(intra-cluster similarity)与类间差异度(inter-cluster dissimilarity)的参数也会对应得到更新,在边和点的特征都得到更新之后,计算边损失(Edge Loss),用 episodic training 的训练策略来更新 EGNN 的权重。
接下来我们会从少样本分类学习的问题定义入手,结合一个二分类的例子来阐述 EGNN 的各个模块与更新算法规则,帮助我们理解 EGNN,最后顺延扩展到论文实验中真正部署的多分类任务。少样本分类顾名思义就是通过每个类别极少或较少的训练样本来学习泛化而且鲁棒的分类器能够保持较高的准确度并且具有扩展性从而识别新的类别。由此,每个分类的任务 T(Task)都包含一个支持集 S(Support Set)与查询集 Q(Query Set),支持集是一个已包含标签的数据集,查询集则是未经标记的数据集,也正是学好的分类器进行验证的一个数据集。如果支持集 S 包含 N 个类,每个类别对应有 K 个标记数据,那么我们称此类问题为 N 路 K 样本分类问题(N-way K-shot classification problem),现在我们假设手上有两个类别的数据,支持集 S 中每个类别有两个样本,查询集 Q 有一个未标记样本(类似测试样本,我们已知标签,但是对于网络并不透露它)我们将这个问题归为 2 类 2 样本问题,参考下图 EGNN 框架图,我们一个模块一个模块来理解推导:
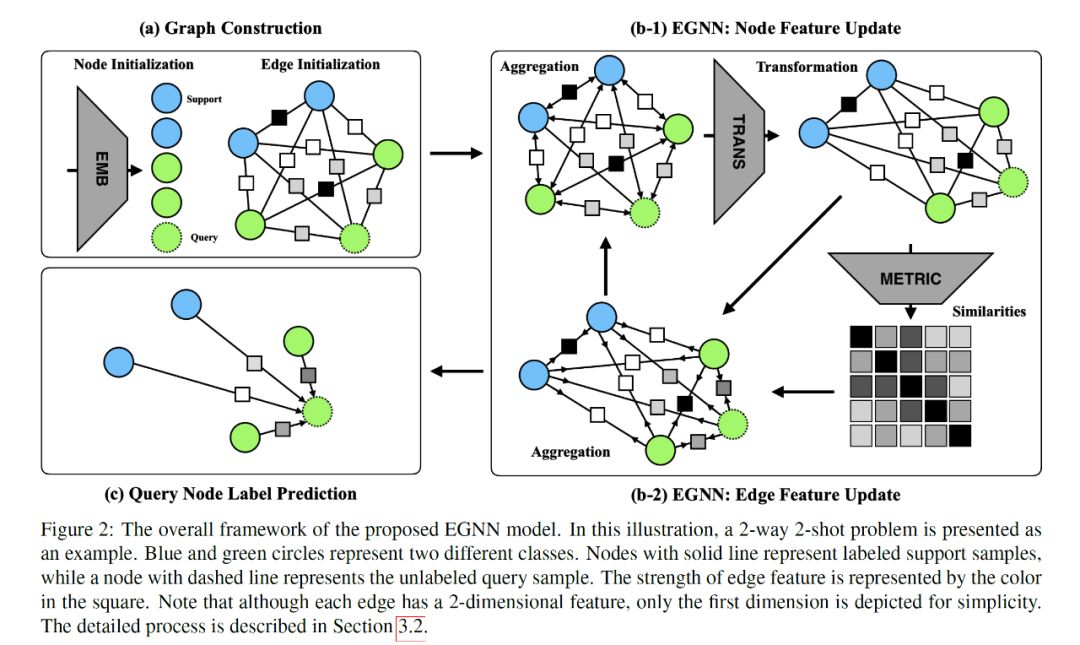
原始的两类五个样本数据都是图像,所以首先 a)我们将图像输入到卷积神经网络(Convolutional Neural Networks)中提取特征,得到数据样本的特征表示,之后根据已有特征建立邻接边并初始化,形成一张全连接图(fully-connected graph),每一条边都指代着它连接的两个节点的关系类型。图的构造用数学形式表示为 G=(V,E;T),对于每一个任务 T,一个图对应着一个节点集合 V,一个边集合 E。对于支持集的边标签我们采用节点的标签进行表示如下:
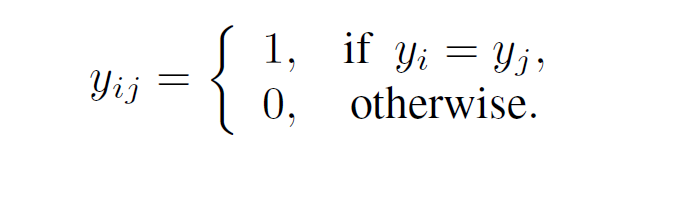
至于边的特征 e 我们一个数值范围在 [0,1] 区间内的二维向量来分别表示该条边连接的两个节点类内相似度(intra-cluster similarity)与类间差异度(inter-cluster dissimilarity),图网络同样也是多层网络,每层均可以按照类似的规则进行初始化。
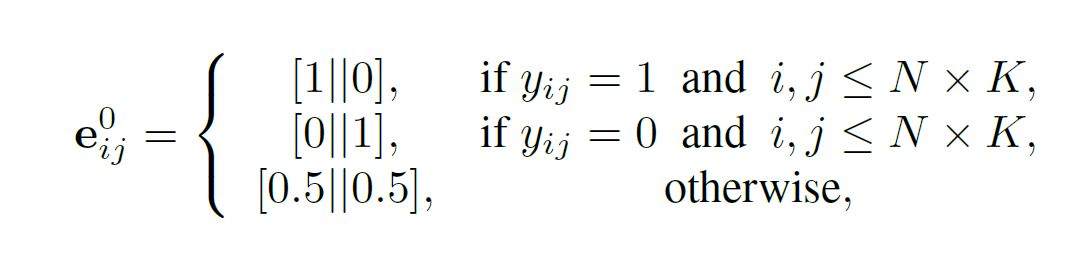
b)图初始化完成之后,我们就根据之前提到过的信息更新流程,首先更新节点特征:
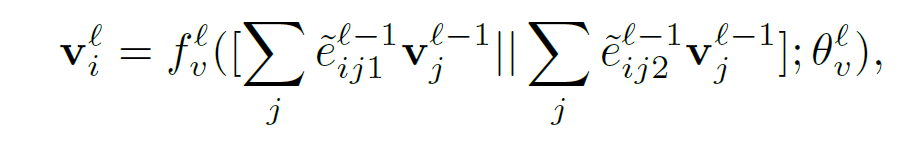
之后就是根据变换后的节点信息来更新边的特征:
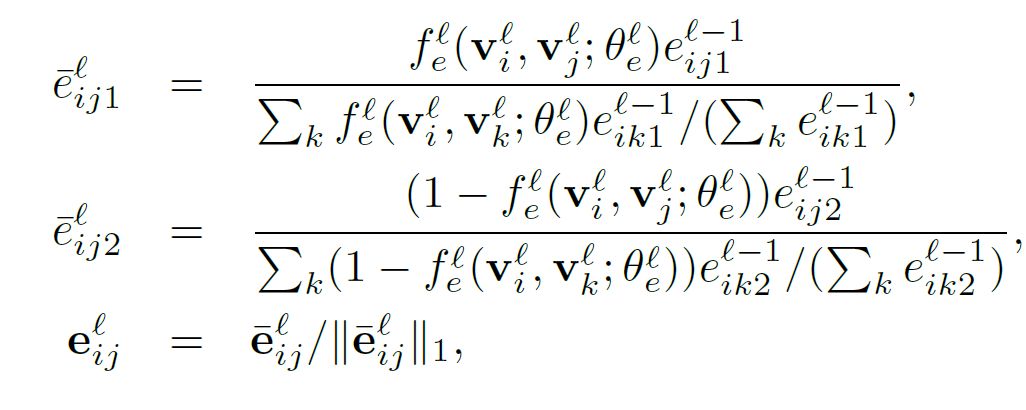
c)在数次的节点、连接边特征迭代更新之后,我们可以从最近更新的边特征上得到最终的节点类别预测,用非常直接的加权投票(weighted voting)方法,结合支持集 S 里的样本标签以及它们与查询样本连接边的预测值,我们就可以很容易的推出待查询样本的所属类别,节点的预测概率可以表达为:
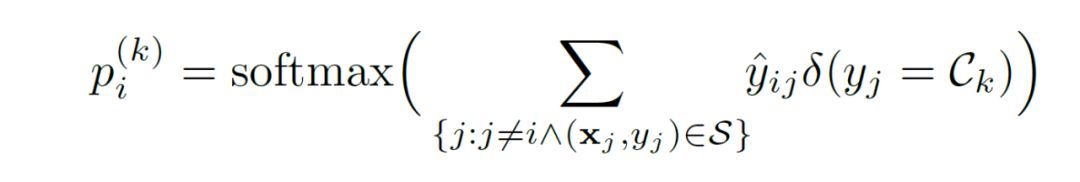
同样地,EGNN 的推理过程算法正如上述各个模块流程所述,详细的网络模块图与算法流程图如下:

具体到实验部分,EGNN 采用了 miniImageNet,tieredImageNet 两个标准数据集,图像种类数目由 100 到 608 类,图片数目也分为较少和较多,且 tieredImageNet 还具有分层级的图像种类类别结构,EGNN 尝试从数据体量大小,种类多少,任务难易程度来比较从而证实加入 EGNN 中边属性后的网络优越性,最终实验结果如下图所示,平均起来比之前提出的各类 GNN 在少样本分类任务上确实有不错的精度提升:
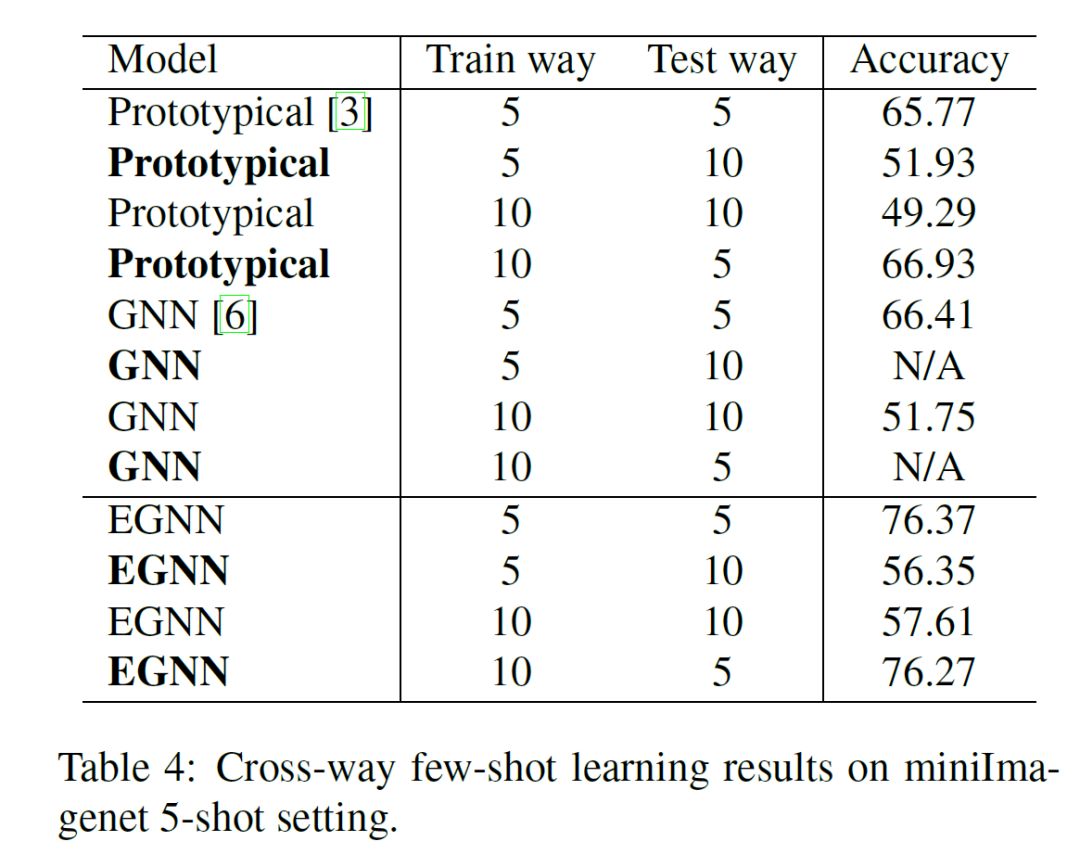
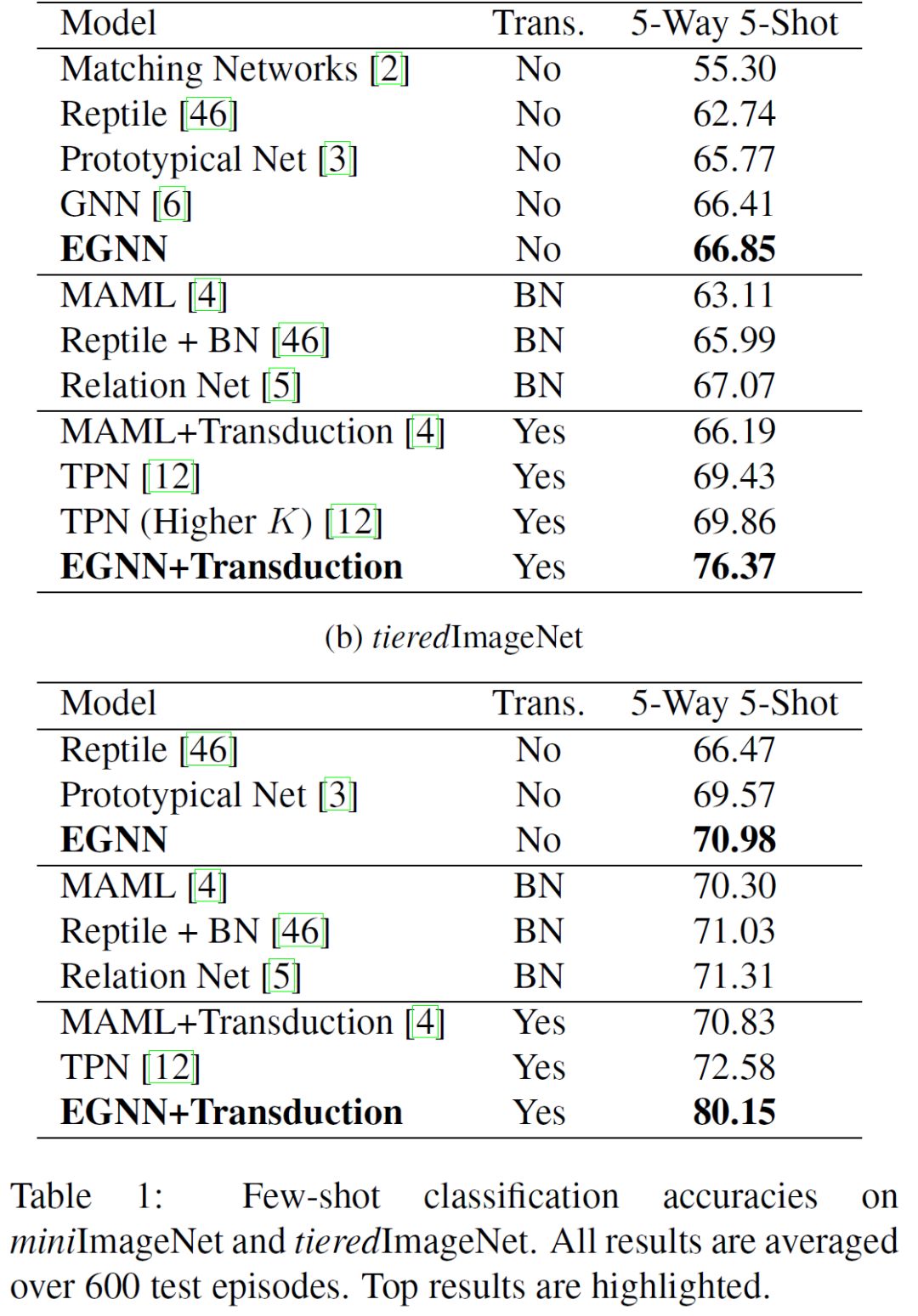
综合看下来这篇文章在构思和实现方面都非常有创新,充分利用了图结构学习节点关联的特性,实验结果也非常有说服力,是非常有亮点的一个作品,也对之后图网络相关的工作提供了更多的启发。
2. LaSO: Label-Set Operations networks for multi-label few-shot learning (classification, multi-label)
paper: https://arxiv.org/abs/1902.09811
数学中集合运算的基本概念:集合的并(Union),交(Intersection),补(Complement)三大运算对于我们都不陌生。但是今天这篇论文提出,小样本学习(few-shot learning)情况下的图像多标签分类(multi-label classification)也能够实现类似集合一样的交,并,补操作。
对于小样本学习来说,核心难点经常是可用训练样本数目不足,解决的方法也多是寻求各种形式的样本合成(Example Synthesis),当然样本合成基本都是针对于单标签的普通分类情况,LaSO(Label Set Operation networks)在此基础上,提出了一个应用于多标签小样本分类场景下的样本合成方法,将一组图片输入到 LaSO 网络里,获取两张图片各自的特征,并将他们结合起来,学习在特征空间上的并集特征(union feature),交集特征(intersection feature)以及补集特征(compelemt feature)表示,这三个学习到的特征也会对应我们在多分类上的语义标签的并,交,补操作。
举例子来说明:我们希望训练一个野外各种类动物的分类器,然而目前我们手上仅有的却都是少量的关在笼子里的动物样本图片,笼中动物显然无法很好地泛化和学习到野外动物的特征表示,所以在 LaSO 提出的场景下,我们先将一张笼中公鸡与一张笼中兔的图片配位一对输入到网络中,让 LaSO 不只是学习到兔和公鸡的特征,同时还有我们完全没有涉及的笼子的特征,而笼子的特征恰好是两张输入图片的交集(intersection),我们取出这样的交集特征,同时再次输入一只笼中老虎的照片获得笼中虎特征,此时对笼中虎特征求它与笼子特征的补集(complement),我们从一定程度上就获得了「无笼子」的野生老虎的特征了,示意图如下:

接下来我们一起看看 LaSO 的整个模型结构:
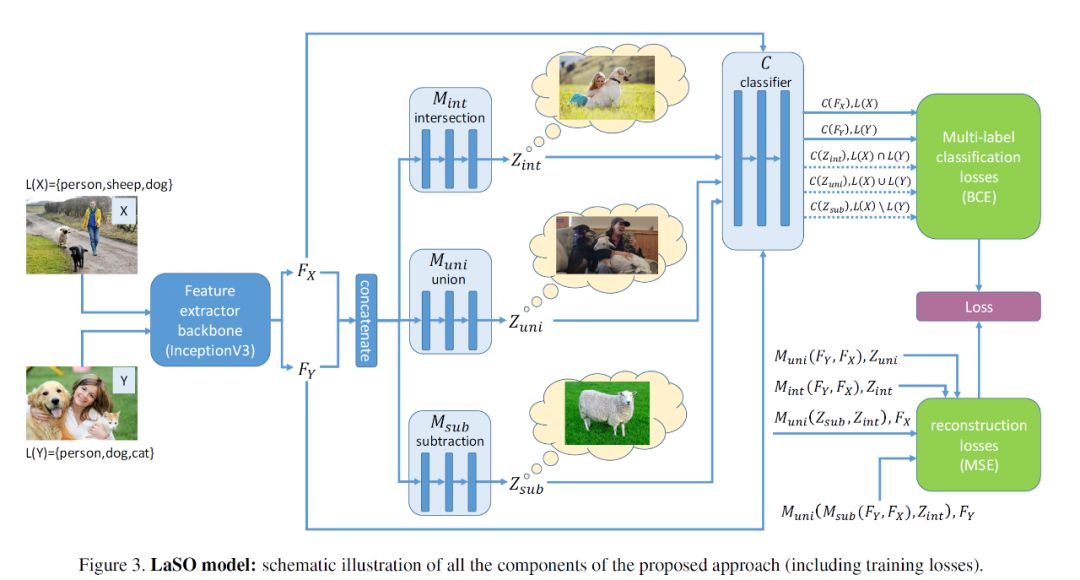
LaSO 模型接受一对图片 X,Y 为输入,分别进入骨干网络 B(文章采用 InceptionV3 以及 Resnet 作为特征提取网络)进行特征提取得到特征 Fx,Fy。在对两张图片的特征进行连接之后,根据我们希望学到的图像中个体类别的交,并,补,所以连接好的特征分别进入 LaSO 的交、并、补网络模块 Mint,Muni,Msub 中学习合成对应的特征 Zint,Zuni,Zsub,特征 Z 可以认为是对应着一张假设的图像 I,这张图像 I 中的个体类别恰好对应着输入 X,Y 的标签的并/交/补,举例说明 Zint 可以看做假设图 I 的提取特征,而图 I 的标签 L(I)正是输入 X 与 Y 的标签交集。
在这之后结合我们已经渠道的所有特征,训练一个分类器 C 并使用交叉熵损失函数(Binary Cross-Entropy Loss, BCE)来学习这个多标签分类的问题,同时之前学习合成特征 Z 的三个 LaSO 模块也采用一样的损失函数进行参数更新,具体表达式如下:
交叉熵损失函数:
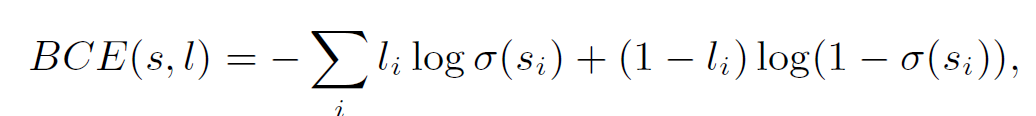
分类器 C 损失函数:
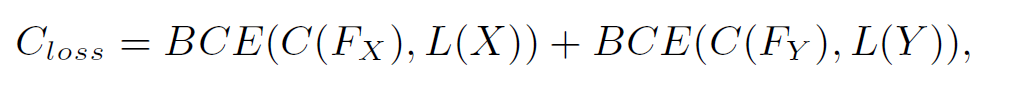
LaSO 模块损失函数:
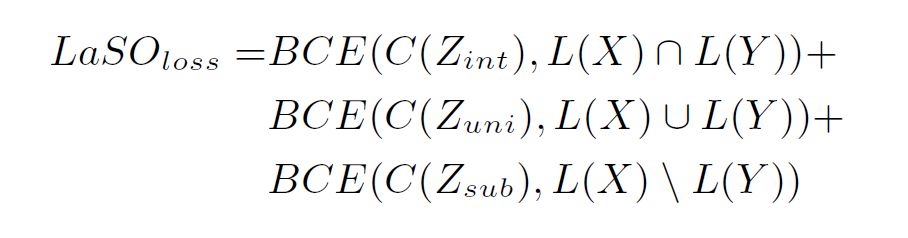
除此之外考虑到操作对称因素以及模型稳定因素,基于重构的均方误差(Mean Square Error,MSE)也作为另一部分的损失加载到模型的最后:
对称损失:
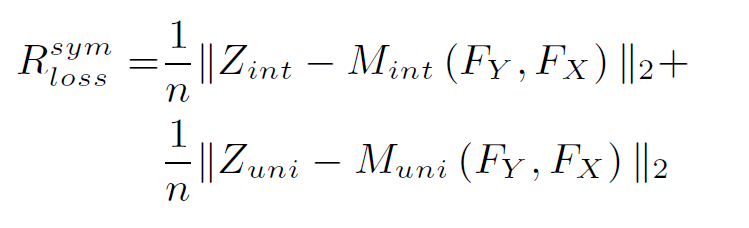
模型稳定损失:
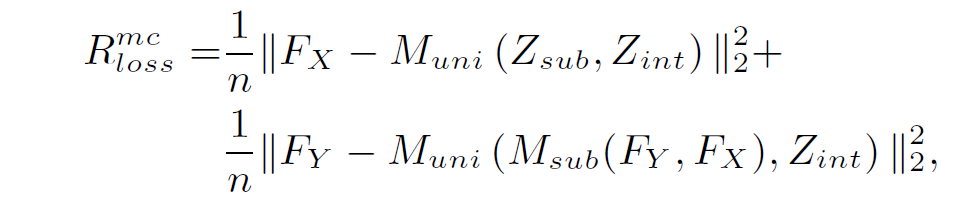
在实验过程部分,论文主要采用了 MS-COCO 2014 与 celebA 的数据集来进行实验和对比分析,将 COCO 数据集的 80 的物体类别随机分成 64 个已知类别与 16 个未知类别,并且使用平均精度(mean Average Precision,mAP)来衡量 LaSO 模块的学习能力,结果具体如下:
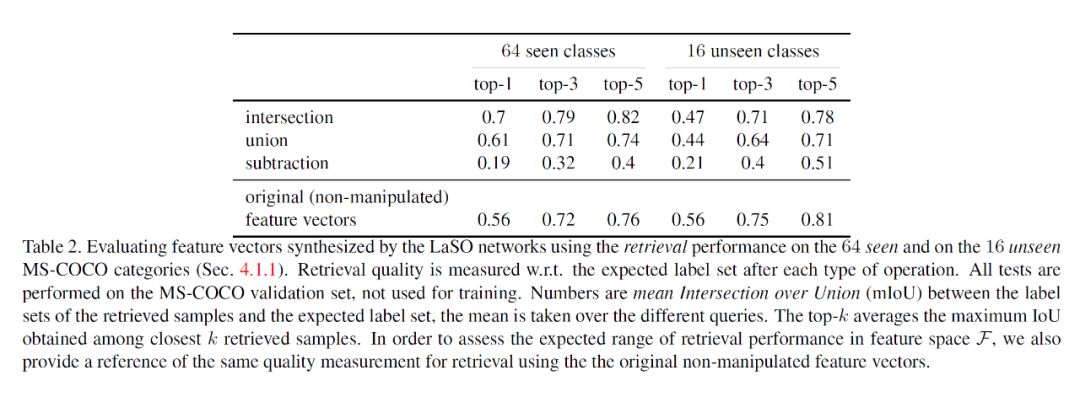
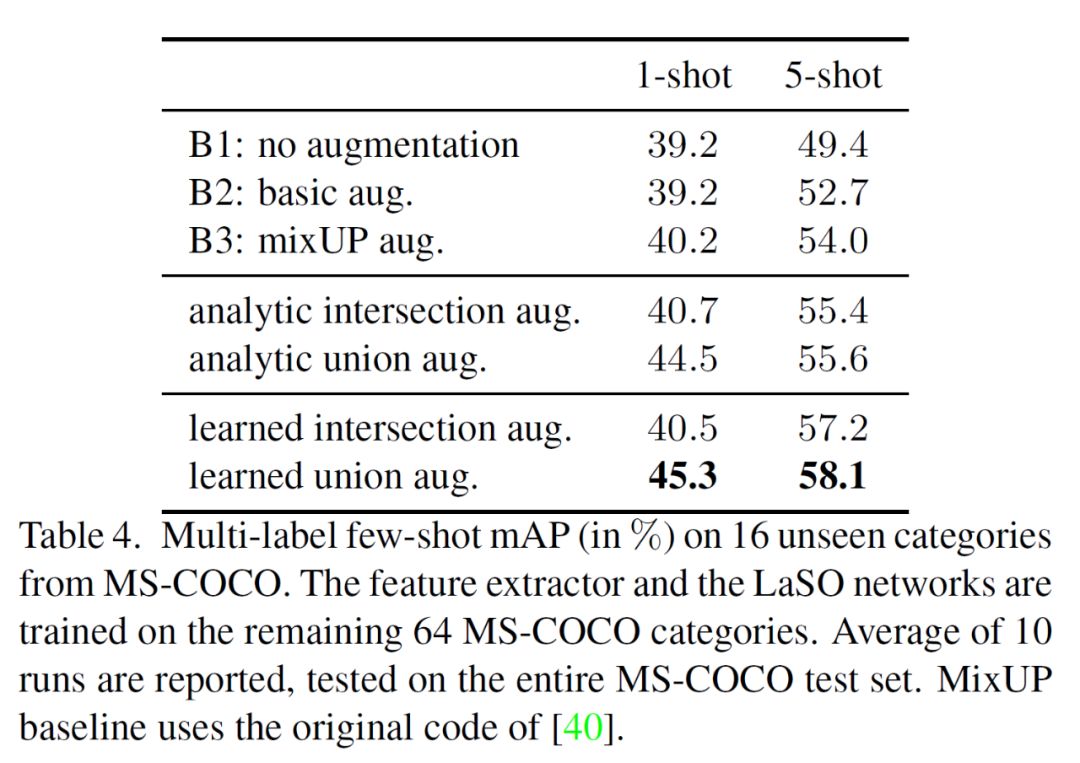
综合看来,这篇 LaSO 论文选题的角度非常有创新性,少量样本来学习多标签分类,并且使用集合中并、补、交的数学概念来操作图像标签,进行样本增广,反过来又辅助了少样本学习情况下样本缺乏的问题,提出的网络架构也非常直观易懂,虽然目前看来分类效果还有待提升,同时网络的训练目前也还是分批来进行,扩展的实验也没有那么丰富,但是它提出的新颖角度和方法,也仍然是值得关注的,相信之后也会有更多的思考和新的工作会更新,根据原文,LaSO 的代码也即将在近期公布供读者参考验证。
检测任务上的少样本学习
3.RepMet: Representative-based metric learning for classification and few-shot object detection (detection)
paper: https://arxiv.org/abs/1806.04728
深度度量学习(Deep Metric Learning,DML)顾名思义,通过衡量映射在某一空间上的样本之间的距离,来学习样本的相似度与区分度。比如在分类任务学习中,不同类别的图像样本通过神经网络抽取特征得到一个个表征之后,通过欧式距离衡量样本表征之间的相隔远近,从而推导出样本所属的类别。在这样的朴素衡量思想下,少样本分类学习即可以非常容易的继承这样的算法思路:采用一个合适的嵌入空间(embedding space)来表征样本,再套入合适的距离度量损失来衡量新入样本与各个未知类别之间的距离大小,从而得到待测样本的应属类别。
在深度度量学习的大框架启发下,本篇论文提出了一个新式的深度度量学习方法来同时应用到分类以及检测任务上:该方法以一种端到端的(end-to-end)训练过程同时学习骨干网络参数,嵌入空间,以及每一个物体类别的多模态分布(multi-modal distribution)。之后论文在几个任务和数据及上都做了实验和对比,证明这个新的深度度量学习方法在少样本的目标检测上面的有效性 并在 ImageNet-LOC 数据集上取得了目前为止最好的成绩。
接下来让我们大致看一下 RepMet 方法的思路:类似 Faster-RCNN 一类的常用检测方法,通常是一个提取 ROI(Region of Interest)的网络 RPN(Region Proposal Network),再加上一个分类提取出来的 ROI 的分类器头(cleassifier head),整体构成整个检测模型,论文依托于这个大的结构不变,将模型中的分类器头用一个子网络(subnet)进行了替换:将 ROI 通过池化后提取的嵌入特征向量作为子网络输入,子网络通过提出的深度度量学习新方法,对比嵌入特征向量(embedding features)到每一个类别的表征向量(representatives)之间的距离,学习并计算每个 ROI 的所属类别后验概率(posteriors)。所以在少样本检测的系列实验中,我们将新类别提供的少量训练样本送入骨干网络提取得到前景 ROI 并计算出它们的嵌入特征向量,用这部分嵌入特征向量替代之前从已知类别里学到的表征向量(representatives),从而得到新类别的表征,再计算后验概率。训练和测试阶段的大致流程可以参考如下的流程图:
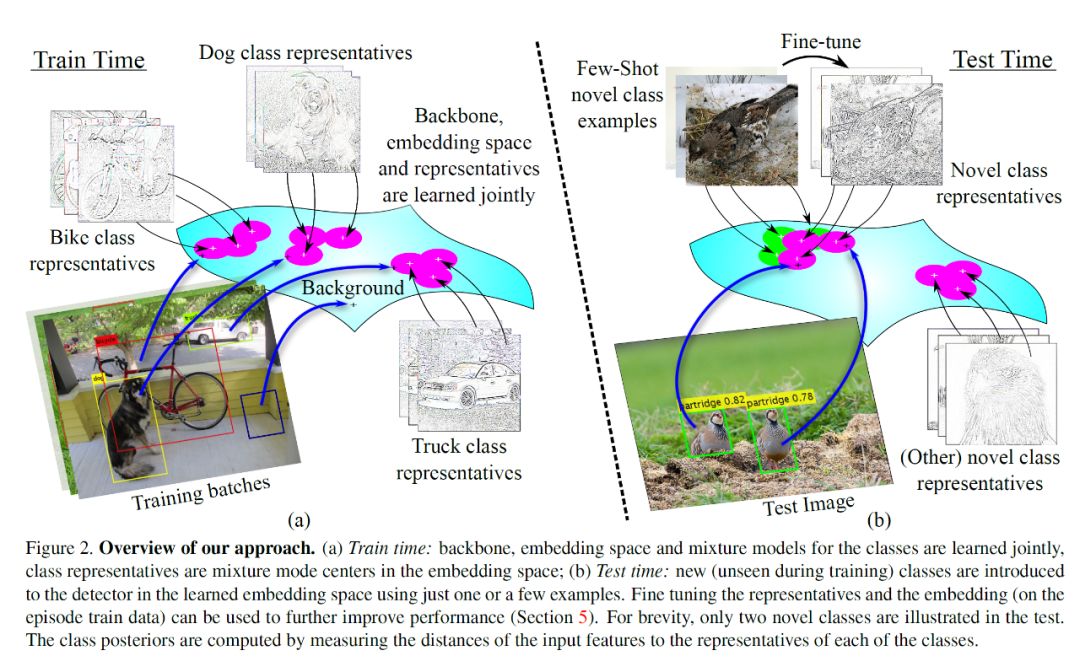
在对 RepMet 的设计思路有了大致了解之后,我们来看这整个模块的网络架构:
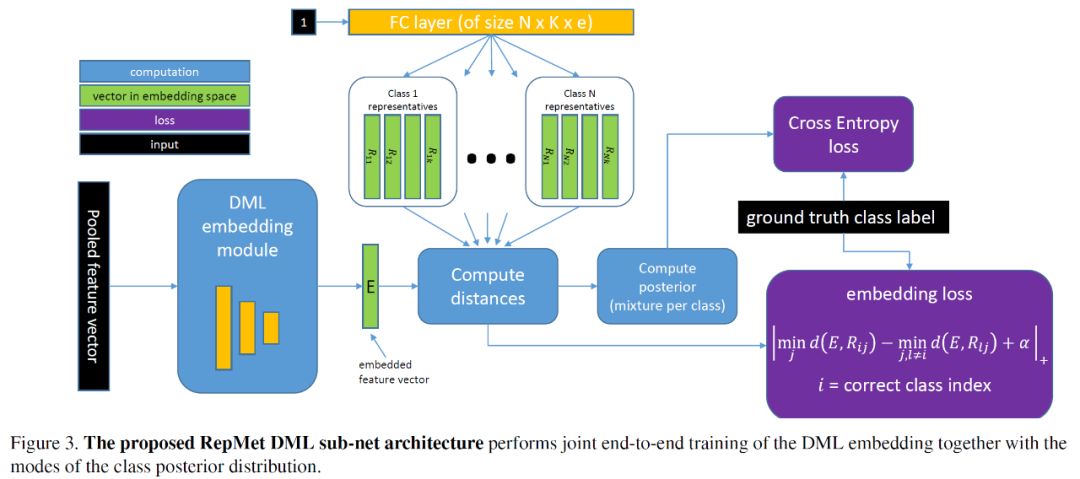
首先图像输入骨干网络并通过池化得到输入 RepMet 子网络模块的输入特征向量,输入特征进入到几个全连接层构成的 DML 嵌入模块得到对应的嵌入特征向量 E,之后便是距离衡量的模块,计算出嵌入特征 E 与多个类别的表征向量的距离,此距离也在之后用来计算所给出图像的后验概率,公式如下:
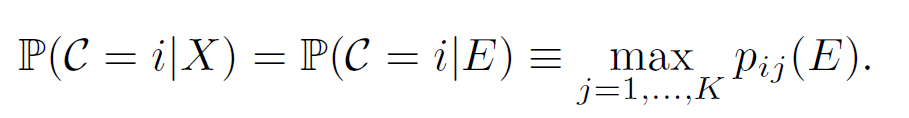
除了计算类别后验概率,论文同样计算了开放的背景类别后验概率:
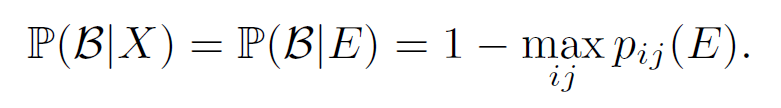
至于损失,类别损失论文就采用了基础的交叉熵损失,另一部分则是 margin 损失,保持嵌入向量 E 与表征向量之间至少有一定的距离,公式如下:
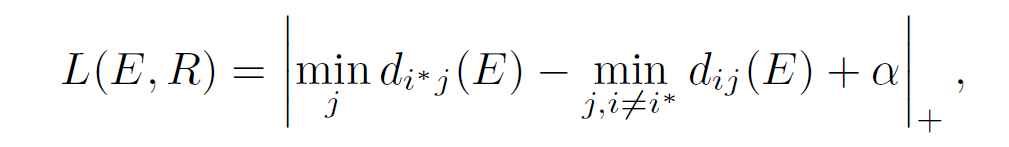
根据论文所提出的子网络以及其对应的损失函数设计,可以使得其能同时训练一个深度度量学习的嵌入表达网络与一个计算类别后验概率的多模态混合分布模型,二者加在一起就组成了替代传统检测器的分类器头(classifier head)的模块,于是同样可以组合到特征提取的骨干网络中,进行端到端的训练过程。
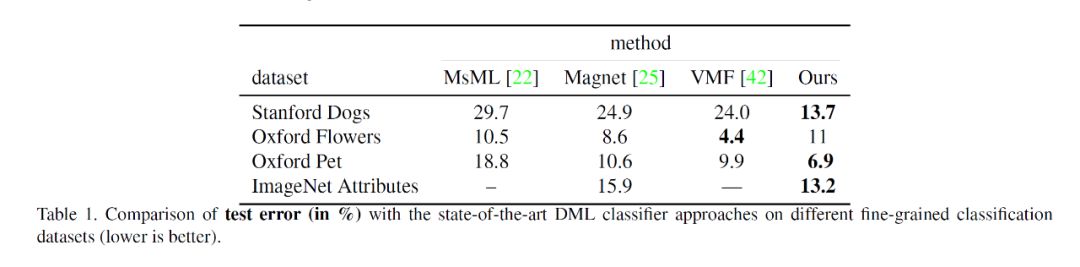
实验首先将 RepMet 整个模块作为分类器的性能在多个数据集上与其余 SOTA 方法做了对比,取得了一定的精度提升:
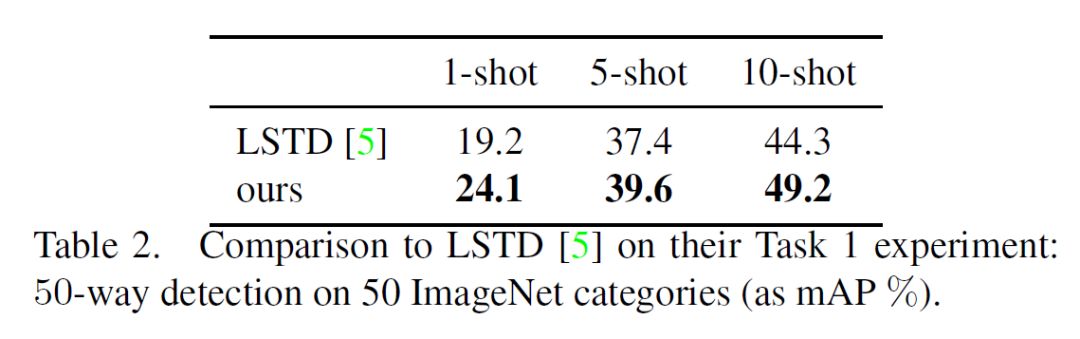
另一方面,在少样本的检测任务上,RepMet 与现有的唯一一个 LSTD 方法做了对比,取得了当前最好的少样本检测精度:
这篇论文综合看来关注了比较新颖的少样本检测问题,提出的方法简单直接,并且也取得了不错的效果,对于少样本检测任务是一个非常有趣的开端,遗憾的是文章提出的方法更侧重的还是在提取到 ROI 之后的分类器上做变动和改进,我们期待朝后会有更多的工作陆续出来并且能够对整个分类器的改进提出新思路,同时据论文内容,代码也将在不久之后公开供读者参考借鉴。
4. Few Shot Adaptive Faster R-CNN(detection)
paper: https://arxiv.org/abs/1903.09372
在实际生活中人眼可以非常轻易地在不一样的新场景下识别出类似的场景或者物体,比如晴天状况下的街道和雨天状况下同一条街道,正午的故宫和傍晚的故宫,又或者是崭新的一台越野车以及车身附着泥浆的越野车。
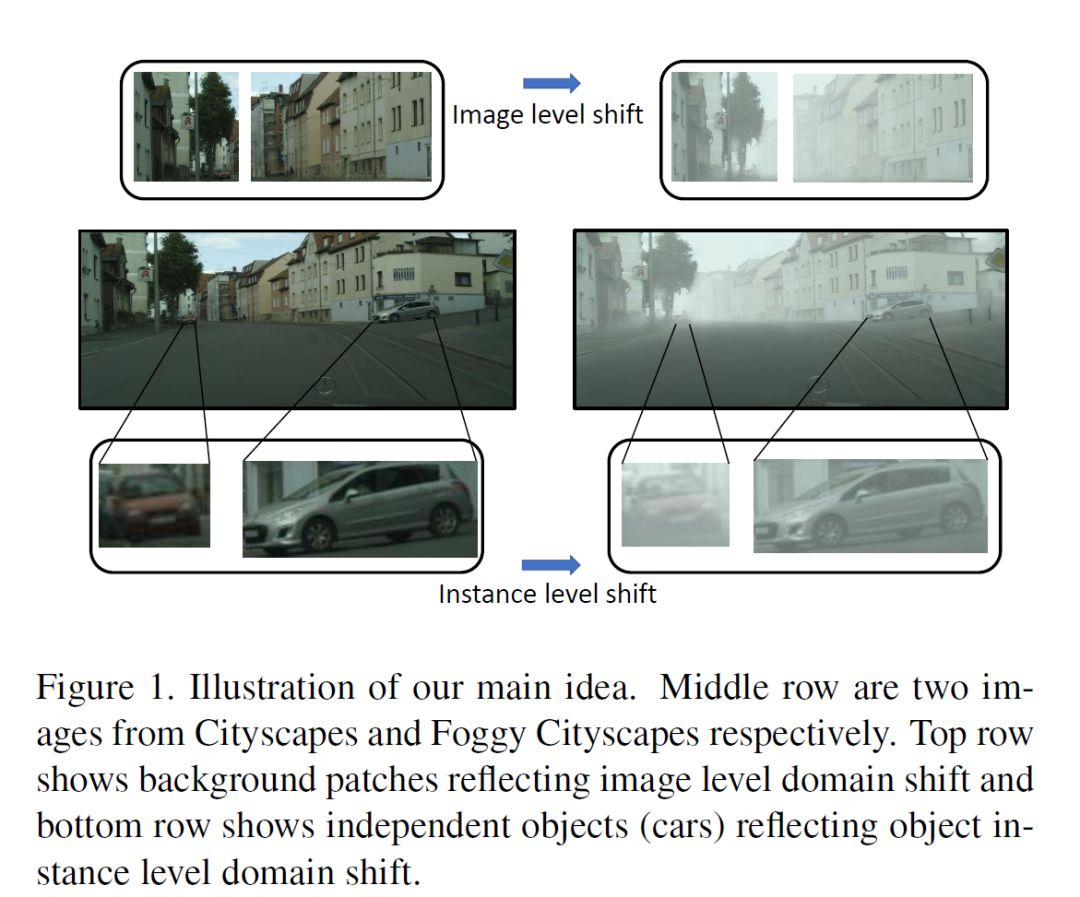
作为人类不会因为气候,光照,或者物体细小的外观变化导致最后无法识别该物体,但是神经网络就会,对于局域的场景变换(domain shift)比较敏感的检测器会因为如上的一些原因造成检测器大幅度性能下降,为了解决此类问题,现有的大部分解决方法均基于无监督的区域适应(unsupervised domain adaptation, UDA),此类方法通常要求大量的目标域数据,相对也需要较长的适应时间,目前适用的领域也大都集中于分类问题,对于检测或者更复杂的视觉问题,应用起来效果并不理想。
本篇论文着眼于以上问题,探索了仅仅依靠少量目标域标记数据来训练一个检测器完成区域适应的可能性,提出了名为 FAFRCNN(few-shot adaptive Faster R-CNN)的网络结构,这个新的框架由图像(image)与实例个体(instance)两层级的的适应模块组成,并搭配一个特征配对机制,与一个强力的正则化,配对机制的引入,使得图像层级的模块能够均衡地抽取并对齐成对的多粒度特征(multi-grain patch features),最终更好的捕捉全局的域变换(global domain shift),例如说光照,而在个体对象层级上,语义上成对匹配的个体特征能够更好地提供不同物体类别之间的区分度,消除不确定性。另一边,强化的正则引入,它能够使得适应过程训练更加稳定并且避免过度适应(over-adaption)问题的发生。
在宏观地了解了 FAFRCNN 的设计思想和初衷之后,我们来进一步地看看整个框架的网络结构:
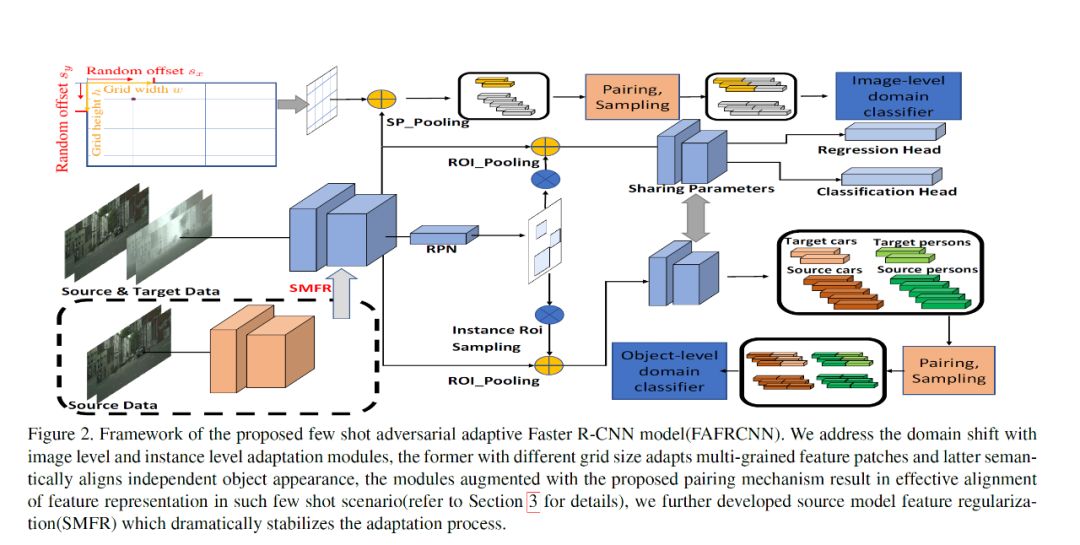
假设我们有非常充裕的原场景区域数据(source domain data)用于训练,表示为(Xs,Ys),同时还有一个非常小的目标域数据集(target domain data),表示为(Xt,Yt),其中 Xs 与 Xt 各自代表着对应数据集的输入图片,Ys 指代着完整的 bounding box 标记。使用 f 指代特征抽取器,那么输入网络后得到的特征就表示为 f(x),受之前图到图转化(image-to-image translation)的启发,文章提出使用分离池化(split pooling, SP),以不同的高宽比和缩放尺度设置窗口,均匀地从各个位置提取局部特征块。
如上述网络结构左上角所示的那样,设置不同缩放比、宽高比之下的网格窗口(grid window)宽高分别为 w, h,最终得到 9 对 w,h 的组合,对于每一对宽高来说,网格中生成的无边界矩形(non-border rectangles)在通过池化之后都会变成固定大小的特征向量,池化使得不同大小的网格都能最终统一地兼容在一个区域分类器(domain classifier)上,在特征经过不同缩放尺度的池化之后,我们得到三个池化向量 SPl(f(X)),SPm(f(X)),SPs(f(X)), 正是这些局部块的特征最终可以影响图像层级的域变换,例如光照,天气状况等。之后根据得到的特征,我们建立了对抗网络来学习区域的变换,对抗网络中的判别器尝试分清原场景域数据与目标域数据,与此同时特征生成器尝试生成真假难辨的特征来迷惑判别器。以小尺度缩放的判别器举例来说,函数的最终目的就是最小化如下的损失:
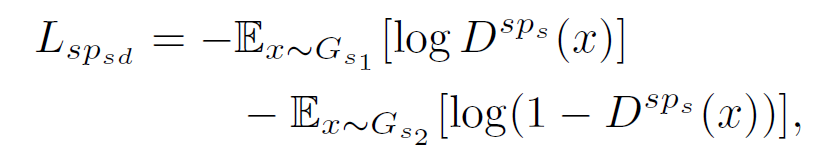
对于其他尺度的函数公式也是同样的,所以最终图像层级 (image-level) 的域变换判别器,想要达到的目的就是最小化三者的和:
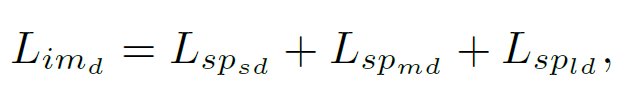
对于个体层级(instance-level)的域变换来说,也是类似的情况,判别器尝试最小化
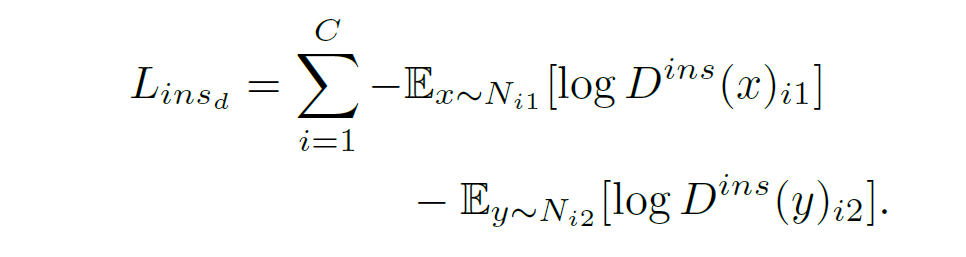
在此同时生成器尝试最小化:
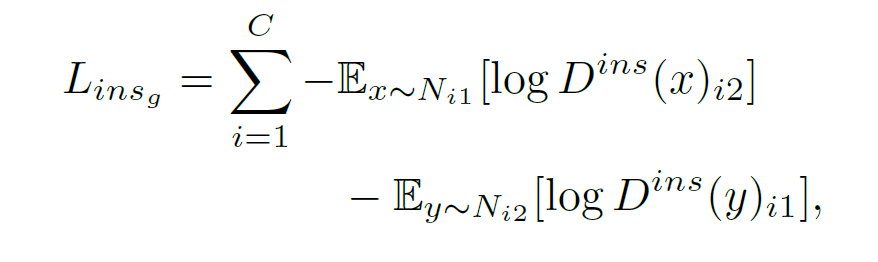
最终在四个数据集上的场景下,FAFRCNN 都取得了目前最好的成绩:
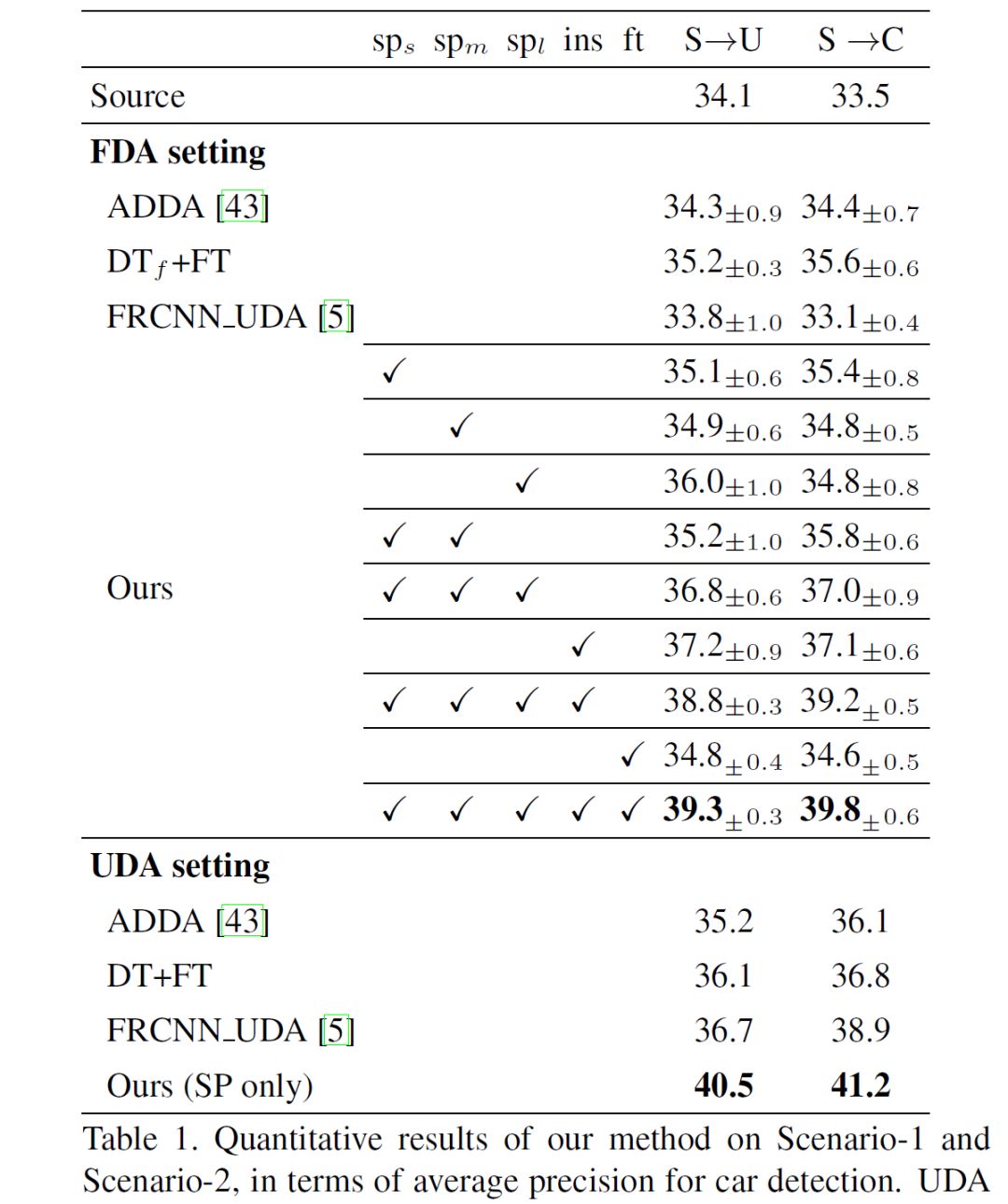
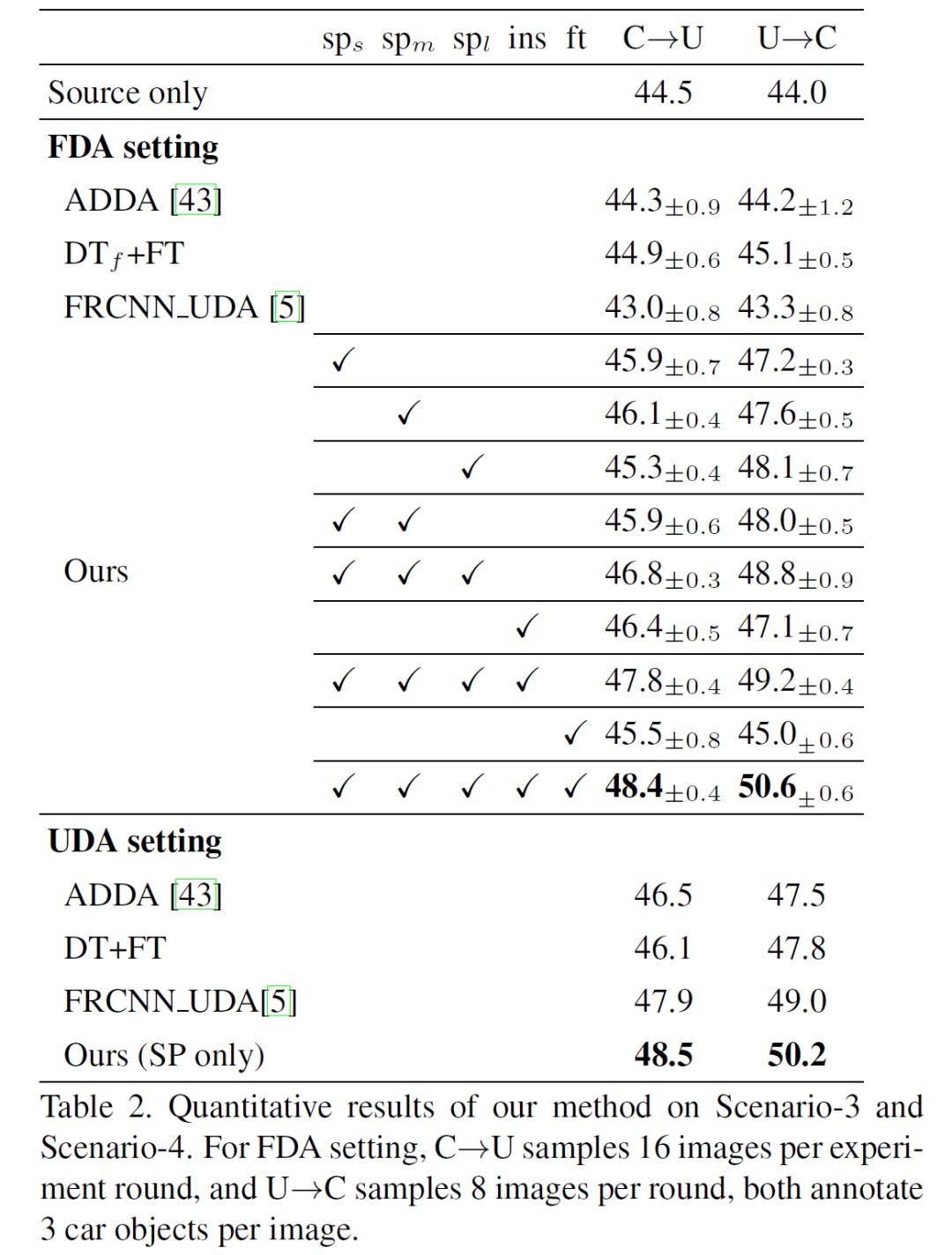
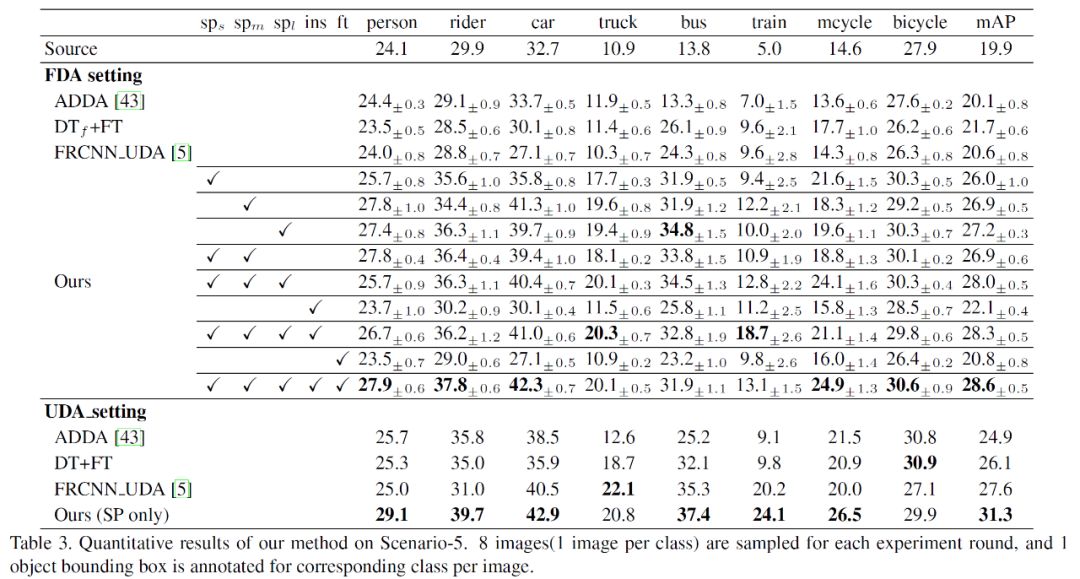
综合看来,文章提出的域适应问题是非常有实际应用价值的,在之前一些工作的基础上,FAFRCNN 提出了用少样本学习来完成检测器中的域适应过程,并与 Faster-RCNN 进行融合,实验结果也非常具有说服力,值得一提的是网络结构为了学习域变化,整体用了三个对抗网络训练,在应用中是否能够如 Faster-RCNN 一样的高效呢?在速度和准确性的 trade-off 之间表现如何,目前还没有文章作者会放出代码的更新,我们可以期待之后是否有相应地更新以及应用于其他数据集上的更新。
其他任务的少样本学习
1.Deep Tree Learning for Zero-shot Face Anti-Spoofing
paper: https://arxiv.org/abs/1904.02860
本文针对人脸识别过程中反欺诈(face Anti-Proofing) 的问题,提出了一个深度树网络(Deep Tree Network)来进行零样本的人脸反欺诈(Zero-Shot Face Anti-Proofing, ZSFA)工作,在之前的工作中仅能零样本识别 1-2 类别的识别欺诈攻击,本篇工作提供了更加深入的探索将可探测到的欺诈类别扩展到了 13 类,同时引入了首个人脸反欺诈的数据库,涵盖了多个类别的欺诈攻击,并证明了本身提出的论文达到了目前为止最好的性能。
2.Few-Shot Learning with Localization in Realistic Settings
paper: https://arxiv.org/abs/1904.08502
传统的识别方法通常要求体量大而且类别均衡的训练数据,同时少样本学习的时候要求在认为造成的小规模数据集上进行测试,然而现实世界中我们遇到的识别类问题却恰恰是显示了一种类别分布的重尾效应(heavy-tailed class distribution)。在这篇文章中证明了之前在人为设计数据及上学习到的少样本学习方法在此类分布模式的数据上并不起作用,根据已有的 meta-iNat benchmark 结果,文章提出了新的 parameter-free 思考与三个训练提升方式,最终在该 benchmark 上达到了非常好的提升效果。
3.Doodle to Search: Practical Zero-Shot Sketch-based Image Retrieval
paper: https://arxiv.org/abs/1904.03451
这篇论文主要关注的内容是基于草图的零样本图像检索(zero-shot sketch-based image retrival, ZSSBIR):当人们画出一个大致轮廓的草图作为检索请求,算法能够准确地检索到之前未见过类别中的图片,在前作基础上,文章提出了新的策略将草图与实际图像建模合并到同一个嵌入特征空间,同时外来的语义知识也被加入进来作为语义迁移的助力,并且成功在该任务上取得了不错的效果
4.Zero-Shot Task Transfer
paper: https://arxiv.org/abs/1903.01092
这篇文章理论性相对稍强,它提出一种名为 TTNet 的新型元学习算法,TTNet 可以做到没有任何标签的情况下对面临的新任务,回归出其该有的参数,也即是零样本的任务学习。文章在 Taskonomy 数据集上针对四个任务:曲面法线,空间布局,深度,以及相机姿态估计做了如上所述的零样本任务学习,而提出的方法 TTNet 超越了目前所有的 SOTA 模型,另一点值得提出的是,这篇论文也是首次尝试将零样本学习应用在任务转化中的一篇作品。
CVPR 其他少样本学习/无监督学习论文列表
注:加粗文章为 oral 文章, 未加粗文章是 poster
1.Generating Classification Weights with Graph Neural Networks for Few-Shot Learning(Oral)
2.Gradient Matching Generative Networks for Zero-Shot Learning(Oral)
paper:http://openaccess.thecvf.com/content_CVPR_2019/html/Huang_Generative_Dual_Adversarial_Network_for_Generalized_Zero-Shot_Learning_CVPR_2019_paper.html
3.Learning Inter-pixel Relations for Weakly Supervised Instance Segmentation(Oral)
paper:https://arxiv.org/abs/1904.05044
4.Unsupervised Person Image Generation with Semantic Parsing Transformation
paper:https://arxiv.org/abs/1904.03379
5.Rethinking Knowledge Graph Propagation for Zero-Shot Learning(Oral)
paper:https://arxiv.org/abs/1805.11724
6.Meta-Transfer Learning for Few-Shot Learning(Poster)
paper:https://arxiv.org/abs/1812.02391
7.Generative Dual Adversarial Network for Generalized Zero-shot Learning(Poster)
paper:https://arxiv.org/abs/1811.04857
8.Hierarchical Disentanglement of Discriminative Latent Features for Zero-shot Learning(Poster)
paper:https://arxiv.org/abs/1803.06731
9.Marginalized Latent Semantic Encoder for Zero-Shot Learning(Poster)
10.Spot and Learn: A Maximum-Entropy Image Patch Sampler for Few-Shot Classification(Poster)
11.Large-Scale Few-Shot Learning: Knowledge Transfer with Class Hierarchy(Poster)
12.Generalized Zero- and Few-Shot Learning via Aligned Variational Autoencoders(Poster)
paper:https://arxiv.org/abs/1812.01784
13.Dense Classification and Implanting for Few-shot Learning(Poster)
paper:https://arxiv.org/abs/1903.05050
14.On zero-shot recognition of generic objects(Poster)
paper:https://arxiv.org/abs/1904.04957
15.out-of-distribution detection for generalized zero-shot action recognition(Poster)
paper:https://arxiv.org/abs/1904.08703
作者简介:
Angulia Yang 毕业于新加坡国立大学,目前从事人工智能相关计算机视觉 (Computer Vision) 与机器学习(Machine Learning)的研究与开发工作,主要工作方向集中为迁移学习与图像分类,近期对强化学习与生成模型进展也有持续关注。在工程师的角色之外,我也是机器之心的一枚业余分析师与撰稿人,对编程技术与计算机视觉前沿工作保持时刻关注,通过文字与大家分享我对前沿工作的剖析和新技术的理解,并从中收获启发与灵感。AI 作为一个涵盖学科知识非常综合的行业,投入三年多的时间都在不停地更新充实自己的知识体系,也见证了视觉相关的技术进入越来越多的行业并且获得消费者的认可,一直相信 AI 技术的产生与发展不是壁垒与掠夺,而是互助与分享,AI For The Greater Goods of Everyone。非常欢迎读者朋友随时找我沟通交流业界动态、学术想法,或者是提出意见反馈想看到的论文分析与业界洞见,联系方式:anguliachao@gmail.com。
Angulia 机器之心个人主页: https://www.jiqizhixin.com/users/9cfaced6-c84b-45bf-bfc4-861e14f74742
参考链接:https://www.jiqizhixin.com/articles/2019-02-26
http://bbs.cvmart.net/topics/302/cvpr2019paper
本文为机器之心原创,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


