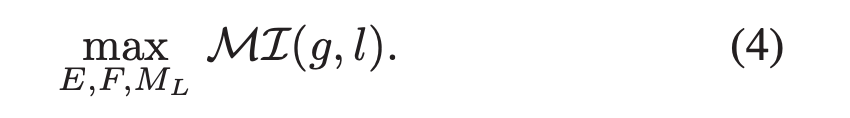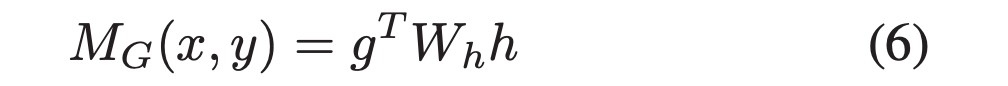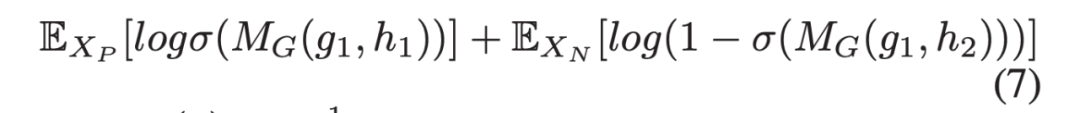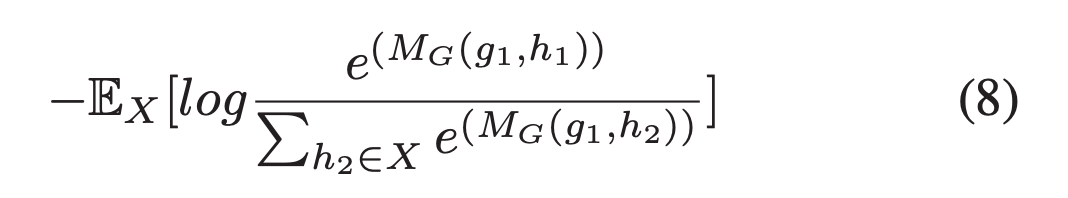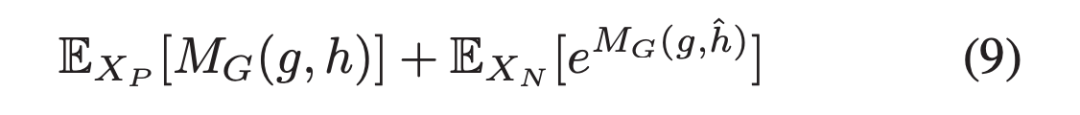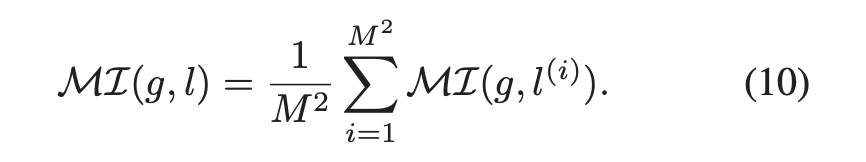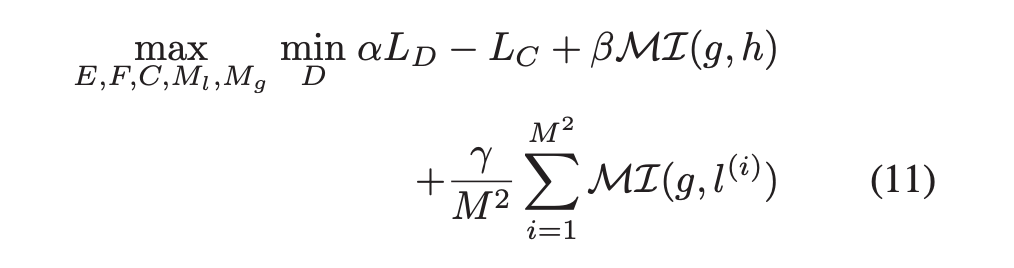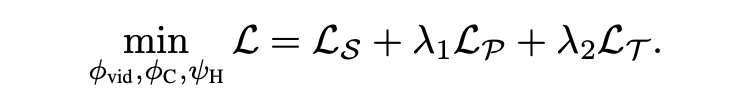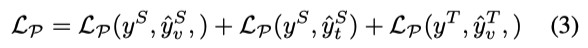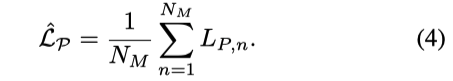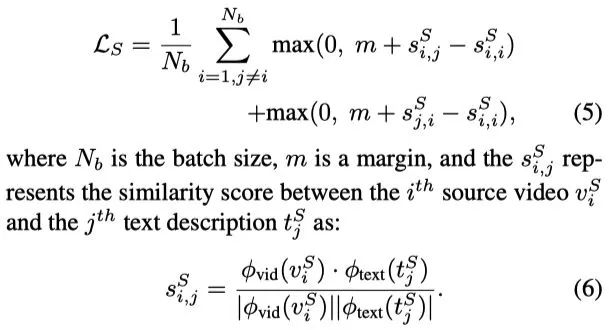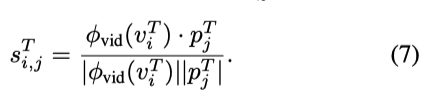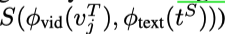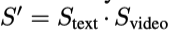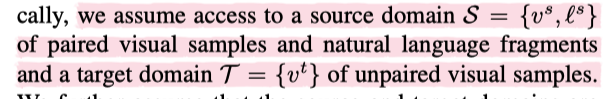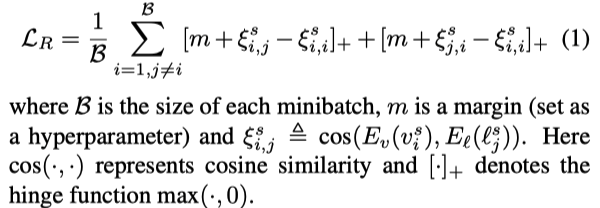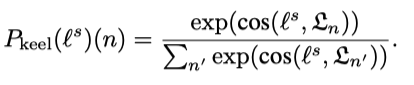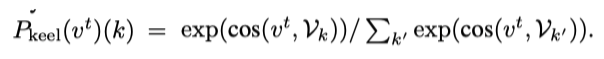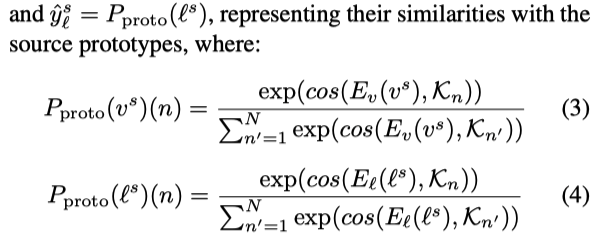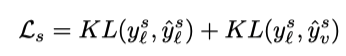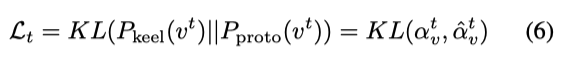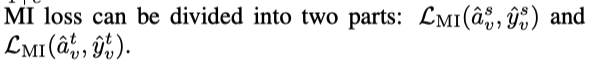©作者 | 李加贝
单位 | 浙江工商大学
研究方向 | 视频文本检索
本文介绍三篇来自于北京大学和牛津大学的工作,其思想都主要是利用了最大化互信息这一概念来减小域特征差异的,通过交叉熵损失函数来隐式的实现这一目的,并且在跨模态任务中的两篇论文中也有很多共通之处。这两篇论文都用到了单模态和跨模态 encoder,旨在通过单模态 encoder(在单模态任务中进行了预训练)来编码通用的特征表示,再通过最大化单模态和跨模态特征的互信息来学习更有鉴别性和可转移的特征,打破跨域的差异。
具体的,在 AAAI 的论文中,作者引入了概念分类一致性和为 target 视频赋予伪文本,在 CVPR 中,主要是通过聚类来获得聚类中心,使得不同的 encoder 编码的特征具有原型一致性,来使得源域和目标域的跨模态表示之间互信息最大化。
论文标题:
Structure-Aware Feature Fusion for Unsupervised Domain Adaptation
收录会议:
AAAI 2020
https://ojs.aaai.org/index.php/AAAI/article/view/6629
1.1 Key Idea
这篇论文应该是作者将互信息最大化引入到 UDA 任务中的第一篇论文,也是第一个将这种想法用到 UDA 任务中的。
由于现有的方法只对高级表示进行对齐,而没有利用复杂的多类结构和局部空间结构。并且以往的研究没有能够有效地将局部特征和分类器预测结合到单一全局特征中进行对抗学习。
在这篇论文中,作者将分类器预测和局部特征映射中传递的有价值的信息整合到全局特征表示中,然后执行单个极小极大博弈(对抗训练)使其域不变。并且采用一种新的目标方法通过有效的采样策略和鉴别器设计来隐式的最大化互信息(这一想法在之后的两篇跨模态跨域任务中都有用到)。
将 source 图像输入到 encoder 中得到 latent local 特征
,将局部特征通过特征转换器 F(全局池化)得到latent global 特征
,再利用分类器进行预测,使用传统的交叉熵损失函数进行优化。
解决 UDA 问题的一般方法是对编码器和特征转换器的进行正则化学习,以匹配
和
之间的边缘分布。一旦边缘分布匹配,source 分类器可以直接用于 target 特征上进行标签预测,在基于这样一种假设的情况下,作者使用对抗学习来最小化特征差异。
通过对抗学习,来最小化 E 和 F 跨域的差异,以至于域分类器 D 不能正确的分类样本来自于哪个域。
然而,上述假设是存在问题的:
1)只匹配边际分布而不利用 multi-mode 结构可能容易发生负迁移,并且不能保证来自具有相同类标签的不同域的样本将被映射到特征空间的相近位置;
2)只匹配全局特征而忽略局部几何空间结构。然而,域差异可能从早期卷积层开始就出现了。
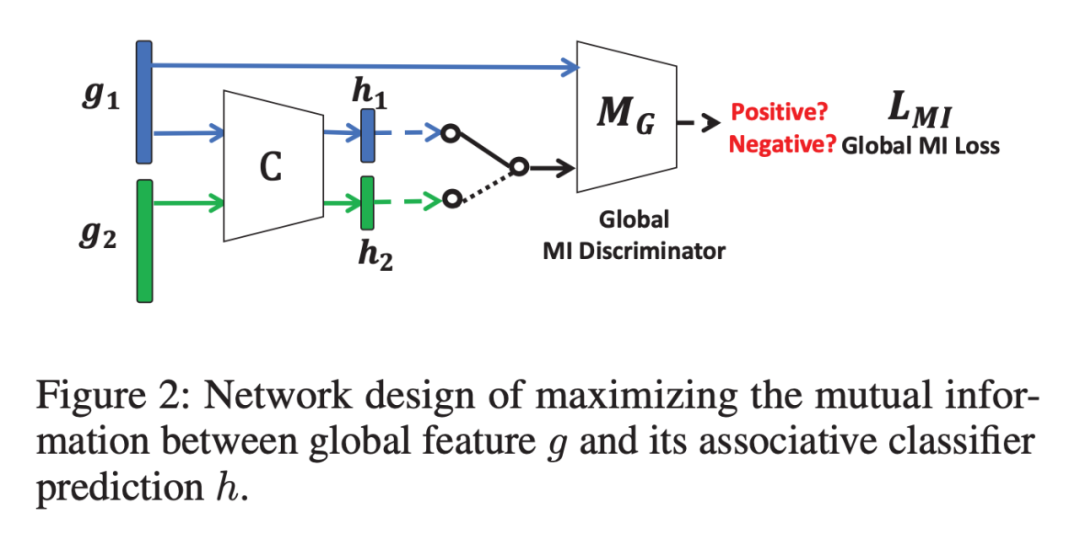
本文的目标是将多层次特征整合到全局特征中,仅使用单一的对抗性训练将其对齐。
因此作者在上述的基础上又引入了 global discriminator MG 和 local discriminator LG 通过最大化全局特征和分类器预测之间,以及全局特征和局部特征之间的互信息来实现该目标。
1.2.1 Maximize MI between global representation and classifier prediction
作者使用一种 encoder-discriminator 结构来隐式的估计 MI,作者使用如图 2 所示的网络设计来最大化全局特征 g 和其对应的分类器预测 h 之间的互信息,具体地,从联合分布 P(g, h) 和边缘乘积 P(g) P(h) 中采样正样本 (g1, h1) 和负样本 (g1, h2)。
给定 g1,全局 MI discriminator MG 旨在辨别其他输入 (h1 or h2) 是否来自同一输入图像,以协作的方式训练 F 和 C。
对于 MG,首先使用一个全连接层将分类器预测
映射为
,然后使用点积来计算 g 和
的相似度。
香农熵相比 KL 散度更加的稳定,因为它在 [0,1] 区间内,对称并且更平滑。
另一种替代方案,作者使用 Noise Contrasting Estimation (NCE) Loss。
第三种替代方案,作者使用 Mutual Information Neural Estimation (MINE) 来直接优化 MI 。
上述所有目标函数都是基于联合边际分布和边际分布乘积之间 KL 发散度的不同近似作为 MI 的定义。这篇论文是第一个将 MI estimation 引入到 UDA 问题中的。
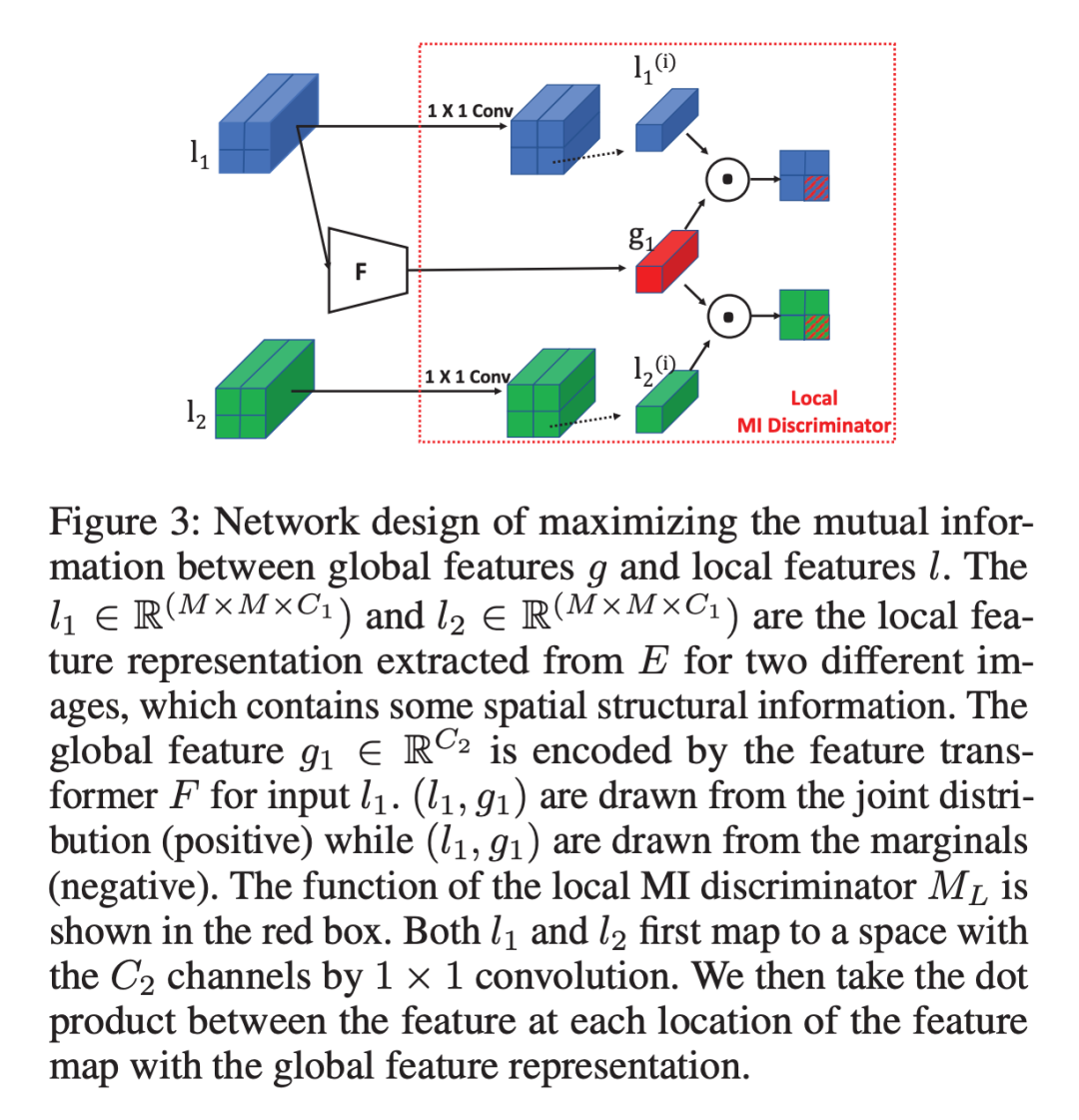
1.2.2 Maximize MI between Global representation and Local representation
如图 3 所示,首先编码输入,得到一个 feature map
,表示为
来保存空间结构信息,然后将 l 通过 feature transformer F,得到对应的全局特征 g,最后作者将在空间位置 i 的局部特征 l(i) 与全局特征 g 之间的 average MI loss 作为局部 MI estimator。
类似的,作者使用 encoder-discriminator 结构设计和采样策略来最大化 MI(g, l)。
从联合分布中采样 (g1, l1) 作为正样本,从边缘分布的乘积中采样 (g1, l2) 作为负样本,旨在训练局部 MI discriminator 正确的判别 l1 和 l2 哪个与 g1 是来自相同的输入图像,协作训练局部特征编码器E和全局特征转换器 F。
与全局 MG 略有不同,局部特征通过 1x1 卷积射为和全局相同的通道数,然后使用点积计算全局特征和每个位置i的局部特征之间的相似度,作为 ML(g, l) 的预测结果。
通过将 MG(g, h) 替换为 L(g, l (i)),上述的替代方案 (7) (8) (9) 同样可以用来最大化 ML(g, l)。值得注意的是,由于相同的全局表示鼓励所有 patches 具有高 MI,这有利于跨 patches 编码共享信息。
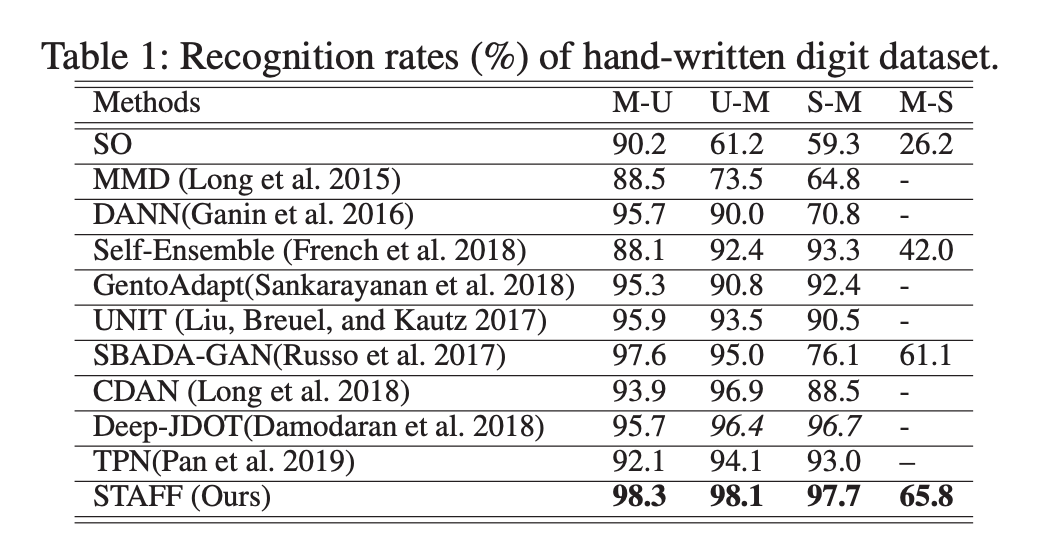
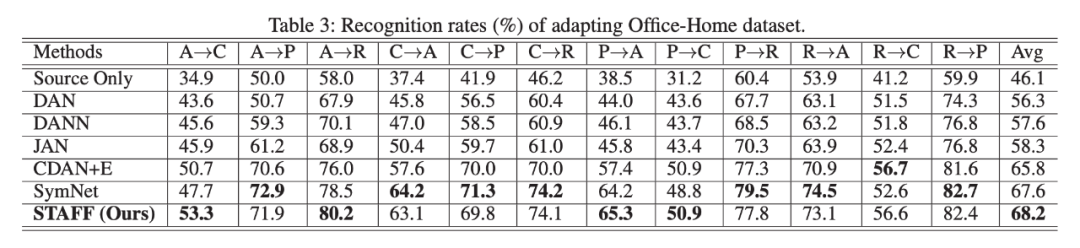
STAFF 在所有基准上都表现得很好,其中包括 Digit、Office-31 和 Office-Home 数据集。
STAFF 优于所有方法,其中 GentoAdapt、UNIT 和 SBADA-GAN 依赖于像素级图像生成,这是专门为数字和 real-world adaptation task 而设计的。这些方法在域位移较小的情况下取得了很好的效果,而在域差异较大的情况下,性能下降了很多,这可能是因为跨差异较大的领域进行图像转换具有挑战性。基于匹配潜在特征分布的方法具有较好的稳定性。
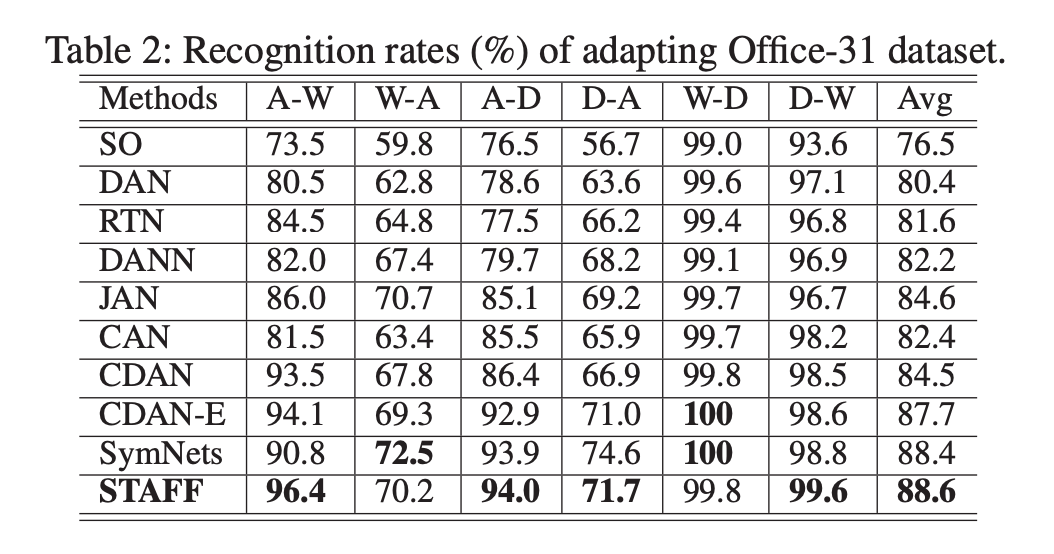
该方法在所有任务上都优于所有的比较方法。与数字数据集相比,这些任务难度更大,域间差异更大,适应精度更低,STAFF 在这样一个困难的任务上产生更大的提升,这表明了结构感知特征融合的重要性。
该方法在 12 个 transfer task 中有 10 个比所有 Baseline 方法的性能都要高,除了最新的 SymNets,作者解释为,潜在的原因是:OfficeHome 数据集包含更多的类类别,该模型可能期望在目标域上匹配更困难的多模态类预测分布(模态结构更重要)。
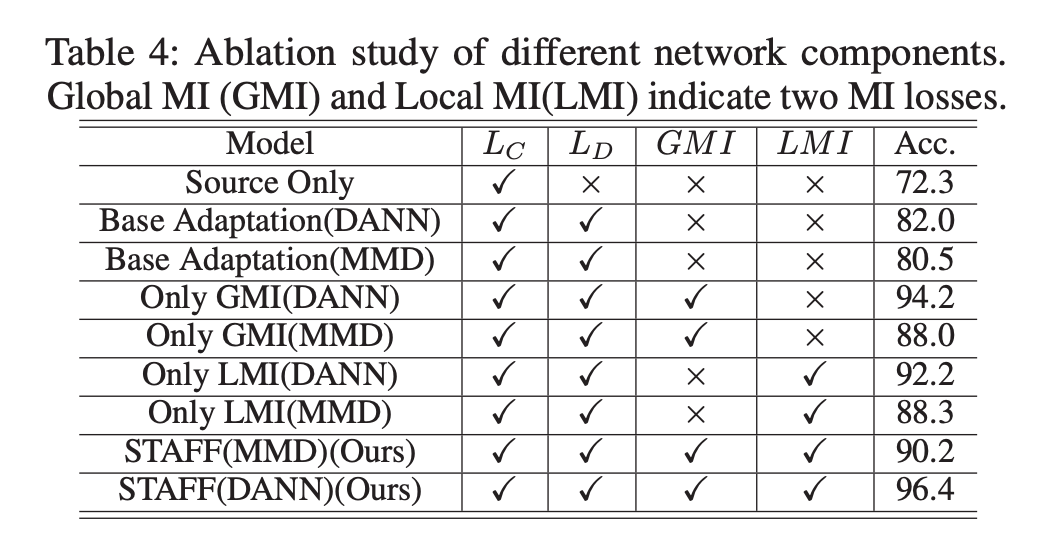
添加全局 MI 最大损失 MI(g, h) 或局部 MI 最大损失 MI(g, l),性能提高约超过 8%,验证利用互信息约束来集成多级特性用于散度衡量的有效性,另外可以观察到,作为单个模块,全局 MI 最大损失有助于获得更大的性能提升。结果表明整合分类器预测中有价值的信息,对保持域不变特征的识别能力,从而提高分类器的分类性能非常重要。
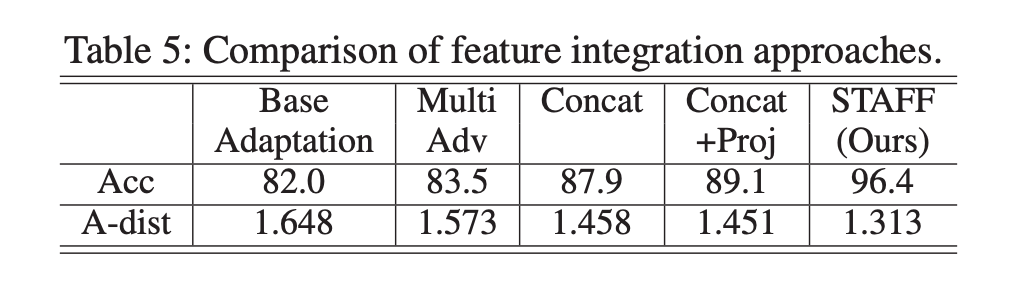
在无监督域自适应问题中,作者比较了不同的特征集成方法。通过四种方式将局部空间结构和分类器预测融合到全局表示中。表明了基于 MI 的集成方法能够更有效地整合结构信息。
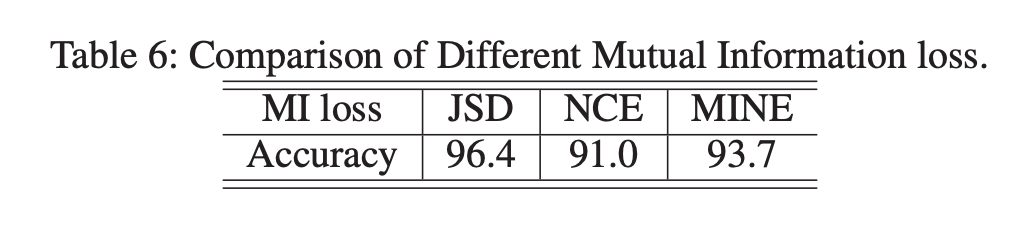
作者比较了上述方法中所提到的三个目标函数来最大化 MI,以集成局部和模态结构,其中包括 JensonShannon Divergence (JSD), Noise Contrastive Estimation (NCE) 和 Mutual Information Neural Estimates (MINE)。可以看出,使用 JSD 取得了最好的性能,作者还发现了随着 batchsize 大小的增加,NCE 损失的性能得到了很大的改善,batchsize 的增加使得负样本的数量增加,模型可以学习到更多的知识(当批量大小为 256 时,它可以达到与 JSD 类似的性能,即 96.3)。
作者还通过 A-distance 定量的测量了分布差异。A-distance 的计算如下:
,其中
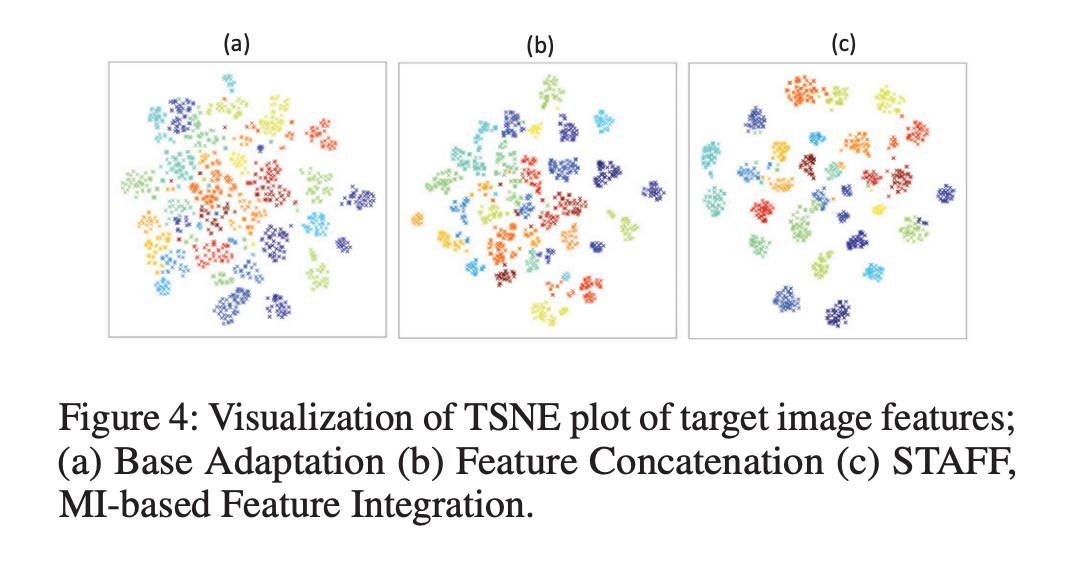
是使用支持向量机 (SVM) 分类器训练来区分源和目标的域分类泛化误差。可以看到,使用 STAFF(基于 MI 的集成)可以达到最低的 A 距离,这证明了它能更有效地缩小分布差距方面的优越性能。基于 MI 的特征集成明显比其他方法聚类更紧密,这表明了 STAFF 在更有鉴别性预测上的有效性。
作者可视化局部 MI 鉴别器的输出,来表示哪个空间位置与全局特征具有更大的 MI,图像中不同区域对应的 MI 值不同。颜色越热,MI 值越大。这些结果直观地表明了局部特征图中 MI 较大的位置与识别区域(即前景对象)密切相关。因此可以实现细粒度的特征对齐,从而获得更好的性能。
论文标题:
Mind-the-Gap! Unsupervised Domain Adaptation for Text-Video Retrieval
AAAI 2021
https://ojs.aaai.org/index.php/AAAI/article/view/16192
经验风险最小化面临着两种类型的 domain shift:
video content/style shift
description distribution shift(通常是由产生每个域的注释者团队之间的描述风格的差异所驱动的)
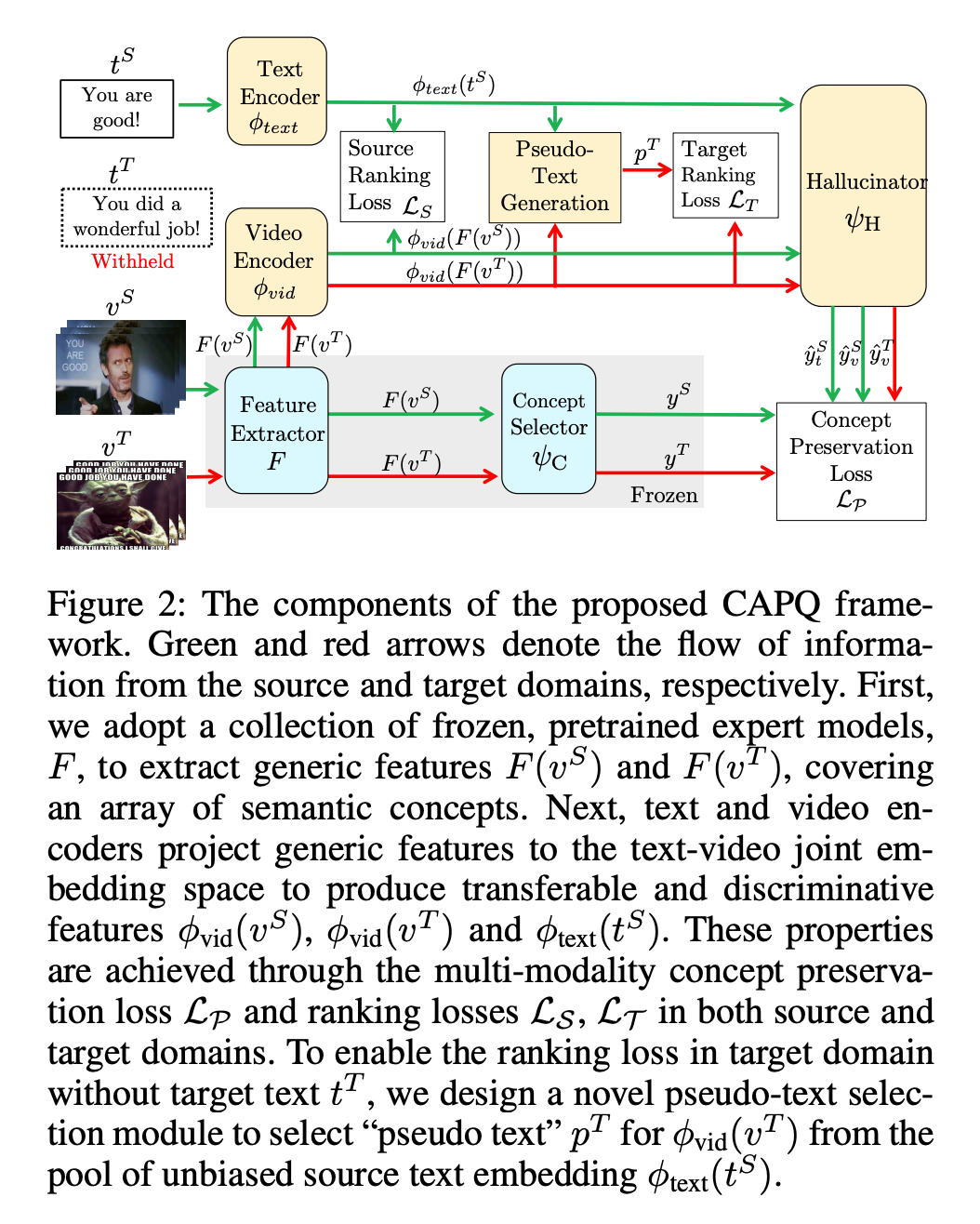
作者提出了 conceptAware-Pseudo-Query (CAPQ) framework 用于跨域视频文本检索。
CAPQ 由以下部分组成:
a feature extractor F, a cross-domain video encoder
, a text encoder
, a concept selector
and a hallucinator
.
来自 source 域的有标签的视频文本对和来自 target 域的无标签的视频。
goal:学习更有鉴别性和可转移的特征,打破跨域的差异,学习一个更好的 target 域嵌入空间。
Feature Extractor:
在图像分类或动作识别等任务上进行预训练的模型,并冻结作为特征 extrator,用来提起 source 和 target 域视频特征。
Descriptors F(vS) 和 F(vT)用来形成内容的通用表示(这是通过使用覆盖广泛语义概念的预训练模型来实现的)。
我觉得应该可以理解为一种单模态 encoder。
Video and Text Encoder:
video encoder φvid 将 F(v) 作为输入,并投影到视频文本联合嵌入空间。
text encoder φtext 首先使用预训练的 word-level embeddings 将每个 query sentence t 映射到一个特征向量集合,然后通过 NetVLAD 来聚合这些 word-level embeddings,并将最终的文本特征投影到视频文本联合嵌入空间中。
Transferable:
最小化 concept preservation loss LP,目的是通过惩罚无法保留预训练模型提供的判别信号的联合空间嵌入来保留先前获得的知识。
Discriminative:
2.1 Concept Preservation(只在训练中使用)
使用一个 concept selector ψC 将 generic video descriptor F(v) 映射到一个概念分布上。
就比如:视频检索经常使用在 ImageNet 上进行图像分类的预训练模型,那么 concept selector 就相当于是预训练模型的最后线性层,将 F(v) 映射到 ImageNet 1000 个概念分布上。
为了在不同的域之间提供一个共同的信号,作者对 source 和 target 的 generic video descriptors 都执行该操作,在 source 域中,由于视频文本对是可获得的,因此作者要求对于给定的匹配视频文本对 {vS, tS} ,它们应该映射到相同的概念分布上。
接下来,作者使用预测得到的概念分布 y 作为一种信号来鼓励视频文本联合嵌入保存预训练模型所具有的概念知识,具体地,作者构建了一个 hallucinator
(两层 MLP),使得 embeddings
和
的预测
与 y 保持一致,对于视频和文本,作者使用了相同的
,隐式的对齐两个不同的模态。
最终,concept preservation loss 表示为:
在 target 域中,只有视频,没有对应的文本。
2.1.1 Discussion on Multi-Modality Features:
由于在视频文本检索任务中,最近的一些工作是使用了多模态预训练模型特征,作者说明,通过使用
个特征提取器
,CAPQ 同样可以直接适用于多模态 setting,将公式(3)扩展为 multi-concept preservation loss。
2.2 Discriminative Joint Space Learning 使用 contrastive margin loss 来训练 source 域的视频文本对,来得到更有鉴别性的嵌入特征。
作者提出改进联合视频-文本嵌入空间(由
训练),以适应鉴别性 target 域检索的要求,提出了伪标签选择机制,具体地,从 unbiased text embeddings
中选择,并将 'best' 文本嵌入
赋给 target 视频作为伪标签,然后使用 second ranking loss
(类似公式(5))进行优化。
2.2.1 Mutually-Exclusive Selection Algorithm:
给定一个无偏文本嵌入
,作者通过选择和 target 视频相似度分数最高的文本嵌入作为伪标签。
但是单单这样做会存在一个问题,尤其对于训练初期,对于 target video vi 的伪标签文本嵌入,也可能会和同时和其他视频 vj 产生更高的分数 因此作者设计了一种互斥伪标签选择,通过使用双向 softmax 操作,首先给定一个相似度矩阵 S,沿着文本维度使用 softmax,得到 Stext,再沿着视频维度使用 softmax,得到 Svideo,然后将 Stext 和 Svideo 相成得到最终的相似度 S'。
最终,选择 S' 中分数最高的作为伪标签,作者说明,这是专为跨模态检索所涉及的,因为该方法首先查看所有候选文本和视频,建立平滑的相似度图,最后分配“最佳”伪文本,这些伪文本不是其他不同视频查询的最近邻,这也是与分类任务中伪标签的选择的关键不同之处。
我这里对于无标签的选择有点疑惑,如果存在这种极端问题,就是某些视频确实没有相关的的文本,或者说文本的相关度并不高呢,以及无偏文本集合的选择。
2.3 Experiment
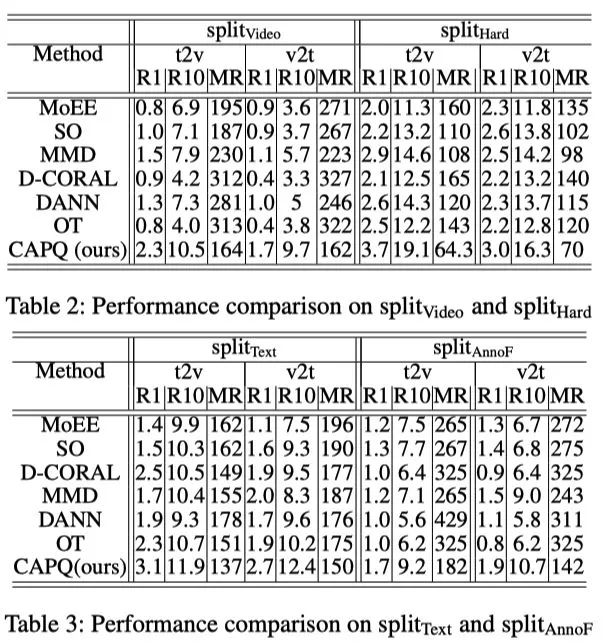
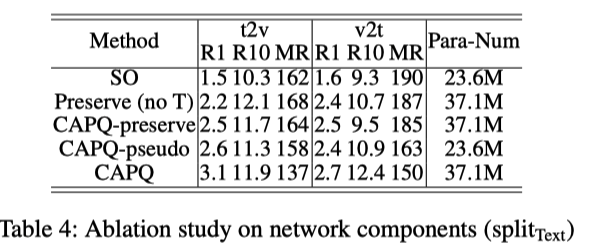
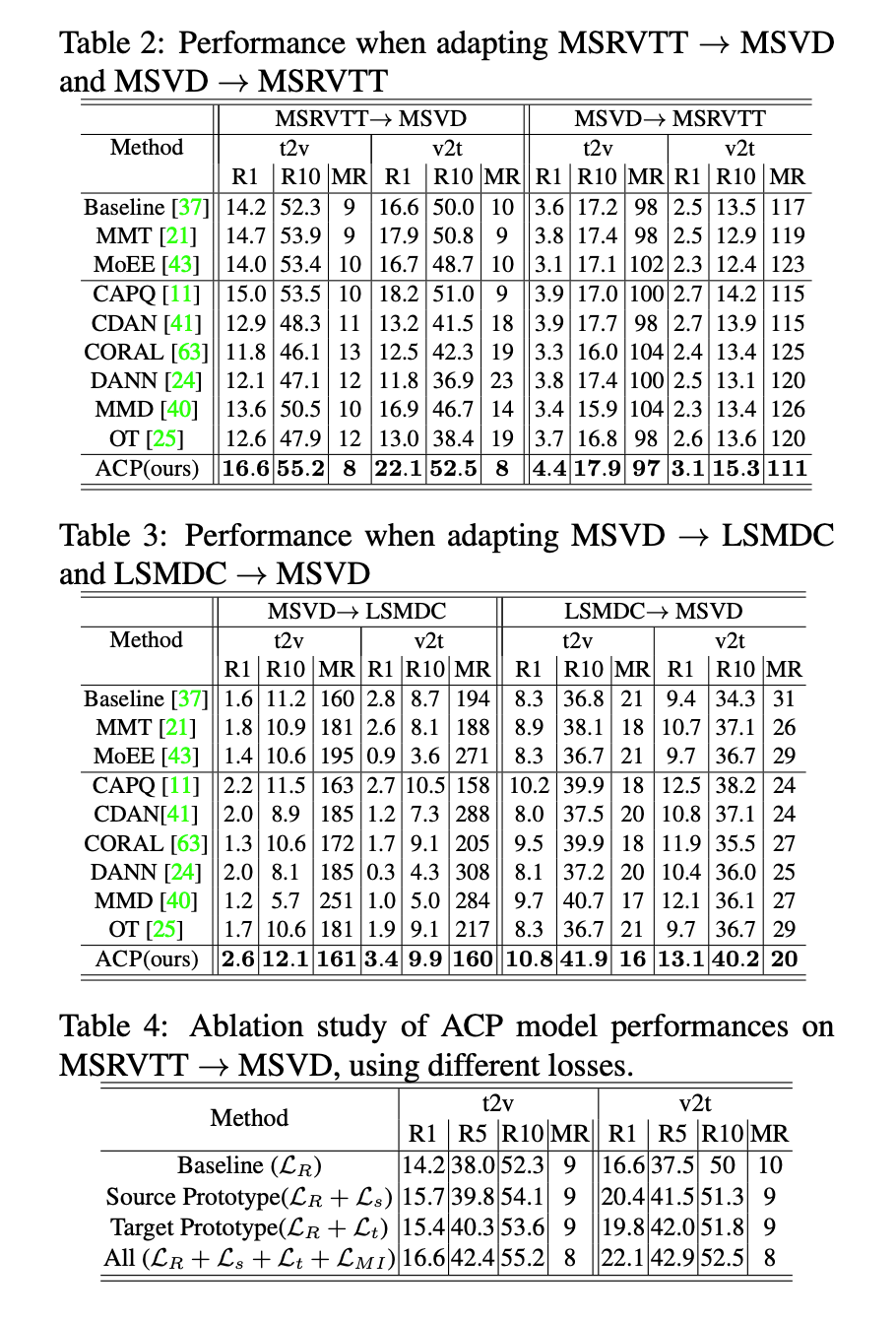
Video Shift: VisualEvents→MovieClips (split Video.)MSVD -> LSMDC
Text Shift: AudioVisualEvents→MovieClips(split Text.)MSRVTT -> LSMDC
Annotation Function Shift: MovieClips→Activities(splitAnnoF) LSMDC -> ActivityNet
VisualEvents→Activities (splitHard) MSVD -> ActivityNet
2.4 Ablation SO baseline (without adaptation)
伪文本选择作为一个单独的模块贡献了最显著的性能增益,这表明通过最小化伪文本查询和目标视频之间的第二排名损失来细化联合文本-视频嵌入空间是有价值的。
第二行中,作者报告了 CAPQ-preserve (no target videos),只在 source 视频和文本中使用概念保存损失(没有伪文本的选择),在这种没有 target 视频的情况下,模型依然超出了 baseline,这表明,使特征嵌入具有通用性是有用的,但对于跨域的视频检索任务是不够的。
在图4的最后一行中,作者展示了一个 CAPQ 不够有效的示例。在这种情况下,由于对目标视频中出现的概念的覆盖不够,伪文本方法没有很高的实用性。然而,所选的伪文本在这种设置中仍然提供了一些好处(特别是类似的场景(房间/公寓),并且仍然可以被 CAPQ 正确识别,从而比 SO 模型提供了一些性能提升)。
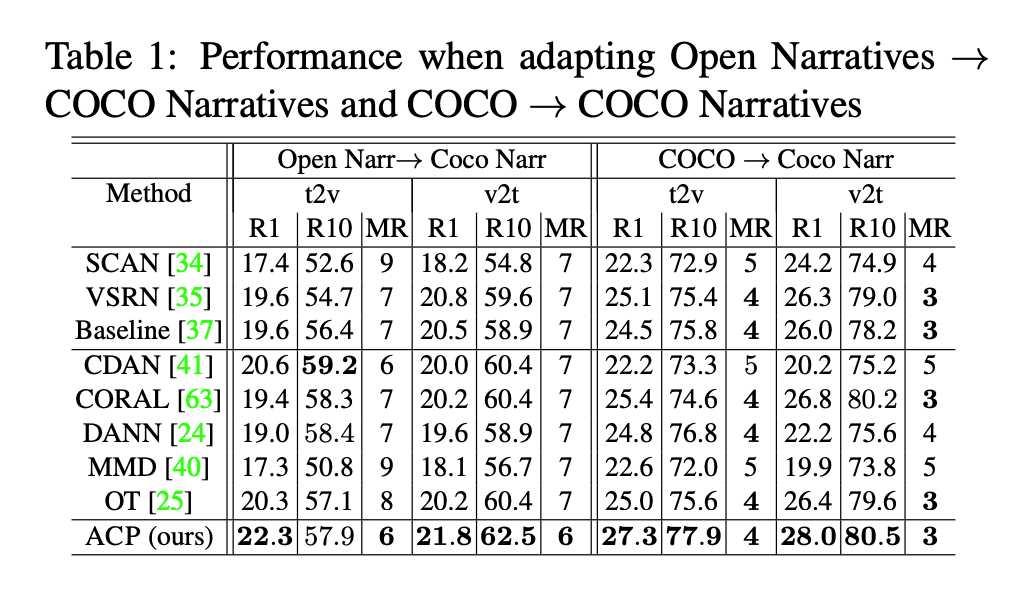
ACP
Adaptive Cross-Modal Prototypes for Cross-Domain Visual-Language Retrieval
收录会议:
论文链接:
https://openaccess.thecvf.com/content/CVPR2021/papers/Liu_Adaptive_Cross-Modal_Prototypes_for_Cross-Domain_Visual-Language_Retrieval_CVPR_2021_paper.pdf
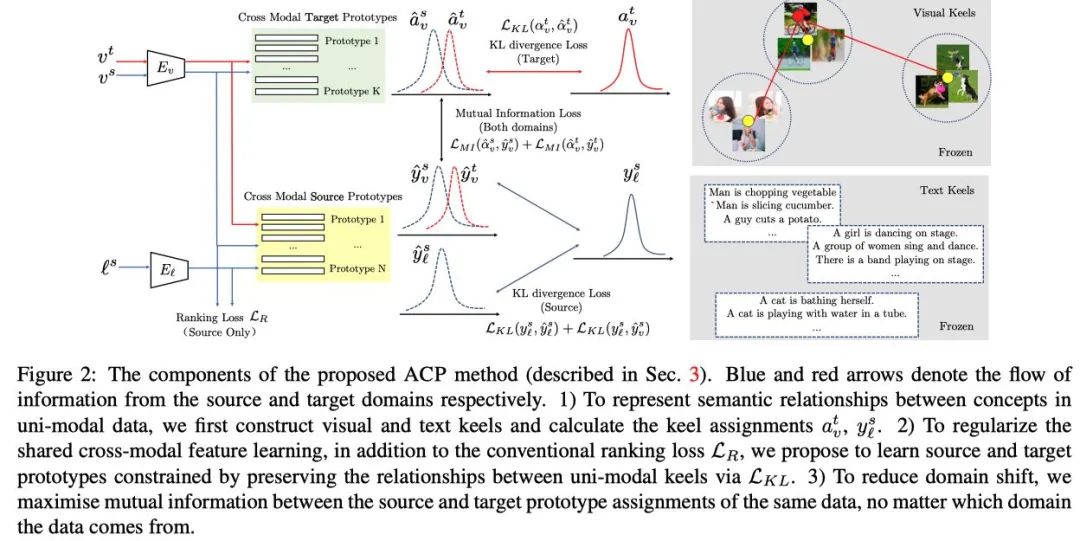
该模型旨在通过学习跨模态视觉文本表示来实现目标域检索,同时最小化源和目标域的单模态和跨模态分布偏移。
3.1 key idea
首先,作者对归纳偏差进行编码,即习得的跨模态特征应该是相对于每个模态中的概念构成的 其次,在学习过程中,作者在源域和目标域的跨模态表示之间采用互信息最大化。
Unsupervised Domain Adaptation (UDA)
sampled from joint distributions
and
(在一个联合分布上进行采样,并非任意两个不同的域)。
视觉和文本编码器 Ev 和 El
单模态视觉和文本 keels Kv 和 Kl
跨模态源和目标原型网络 Ps 和 Pt
3.3 Visual and Text Encoders
使用 visual encoder Ev 和 text encoder El 将 source 视觉样本和文本描述映射到一个跨模态嵌入空间中,使用 bidirectional ranking loss 来对齐视觉和文本。
3.4 Uni-modal Compositional Keels
为了用多个视觉概念(多个词)的组合来表示复杂的语义特征,作者提出使用每个模态中线程的结构只是来构建视觉和文本 keels,使用现成的视觉分类和文本分类模型作为视觉和文本 descriptors(就是作为单模态编码器),然后使用 Lloyds’s algorithm 进行聚类,得到一个聚类中心集合(即视觉和文本 keels),然后计算每个样本的特征与这些中心的相似度,并赋予标签。
Text Keel Construction: 使用通用的
g
eneric text descriptors(在大型语料库中预训练的模型,并冻结参数)来编码 source
文本描述,并将文本特征使用 Lloyds’s algorithm
进行聚类得到
N 个 cluster,每一个 cluster
中心命名为 text keel,然后计算每个文本样本特征与每个 keel 的相似度来得到 cluster assignment
的概率。
Visual Keel Construction: 与 text keel construction 类似,使用预训练模型来得到单模态视觉特征,并进行聚类,得到视觉 keels,然后计算每个 cluster assignment 的概率。
3.5 Source and Target Prototypical Network
使用 KL 散度使跨模态的原型预测和单模态的原型保持一致,target 原型网络是从视觉 keels(由 target data 构建)中进行学习的,source 原型网络是从文本 keels(由 source data 构建)中进行学习的。
由于原型网络是分别由 source 和 target 样本所驱使的,因此它们的分配差异反应了 domain shifts,相同的分配也反应了跨域之间的潜在关系,作者使用最大化 source 和 target 之间原型分配的互信息(MI)来进行跨模态特征正则化学习。
Source Prototypical Network: 原型网络由一个单独的线性映射组成
,原型网络权重矩阵的第 n 行代表了第 n 个原型,将原型网络应用于跨模态嵌入特征
和
上,目标是基于单模态的文本 keel 所提供知道信号来近似跨模态嵌入的中心。
将从单模态文本 keel 中得到的 keel assignment 作为一种软标签来指导跨模态文本嵌入
的学习过程,由于视觉内容
与 source 文本样本
是成对的,因此作者提出将从
中获得的软标签传播到
中。
Target Prototypical Network: 在跨模态嵌入特征
上应用原型网络
,来预测每一个 target 样本的原型 assignment。
3.6 Maximising Mutual Information between Cross-Modal Prototypes
对于每一个 source 和 target 视觉样本
和
,可以让它们通过 source 和 target 原型网络
和
,来获得跨模态原型 assignment。
为了减少 cross-domain shift,作者提出对齐相同输入的原型 assignment
和
,不论它们是来自于哪个域。
值得注意的是,作者这里并没有使用完美对齐来约束 source 和 target 的原型 assignment,因为 source 和 target 原型
和
可能表示了不同的概念(甚至是互补的概念),作者这里是采用最大化 source assignment
和 target assignment
之间的互信息,该设计的灵感来自于这样的观察:最大化互信息保留了跨域的公共信号,同时丢弃其中一个而不是另一个发生的信号。
由于 MI 很难直接衡量在高维空间中衡量两个随机变量,作者这里使用一个目标函数隐式的最大化 MI 通过一种 encoder discriminator 结构和一种有效的采样策略。
我的理解是,比如给定一个视频样本,通过 target 原型网络得到一个原型 assignment
,然后在将样本通过 source 原型网络得到一个原型 assignment
,使用映射矩阵,将
映射得到
(和
shape 相同),然后计算
和
的相似度,作为正样本;然后同理得到另一个视频样本的
,就算
和
的相似度(点积),作为负样本,然后使用 bce 损失,最大化正样本之间的 MI。
3.7 Objective Functions
3.8 Experiment
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读 ,也可以是学术热点剖析 、科研心得 或竞赛经验讲解 等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品 ,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬 ,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱: hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02 )快速投稿,备注:姓名-投稿
△长按添加PaperWeekly小编
🔍
现在,在「知乎」 也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」 订阅我们的专栏吧