
本文简要介绍CVPR2021录用论文“Sequence-to-Sequence Contrastive Learning for Text Recognition”的主要工作。该论文提出了一种针对文本识别,序列到序列对比学习的无监督方法SeqCLR。
无监督的对比学习方法在图像分类、目标检测和图像分割[1,2,3,4]中都取得不错的成果。但是无监督和半监督的方法在文本识别中还有待进一步探索。 对于已有的无监督方法SimCLR[1],它将整张图像作为对比学习中的输入元素,这种整图、非序列化的无监督方法从后文的实验中证明对文本识别的效果很差。所以本文提出了一个序列化的无监督方法SeqCLR,它从整张图片中映射出一定数量的实例来作为对比学习中的输入元素。 图片
图1(a)目前的对比方法比较从整个图像中计算出的单个表示。(b)SeqCLR的对比方法比较从整个图像中计算出的多个表示。
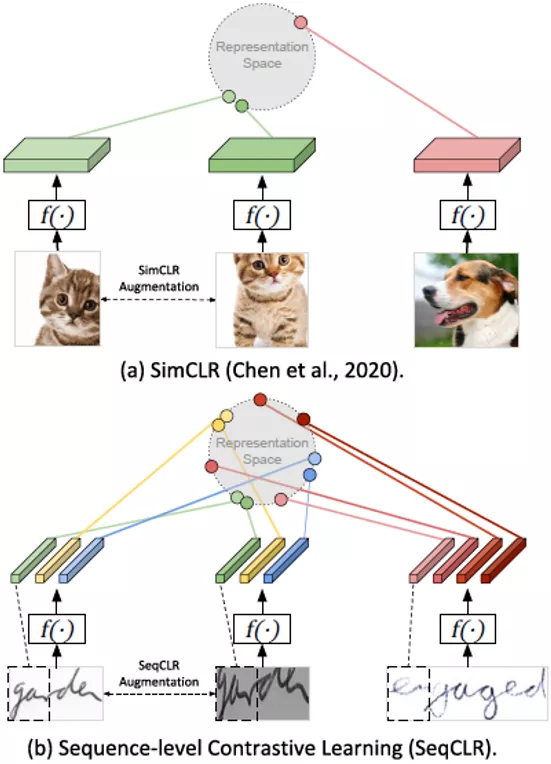
本文的方法是第一个提出用于文本识别的自我监督表示学习的工作。通过在特征图中加窗产生正负样本来将文本图片序列化,这种方法在一些手写文本和场景文本数据集中取得不错的效果。
成为VIP会员查看完整内容
相关内容
Arxiv
8+阅读 · 2020年12月4日

相关VIP内容
相关资讯
相关论文
Arxiv
8+阅读 · 2020年12月4日