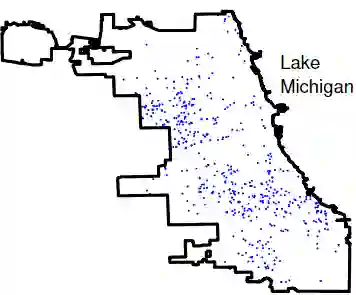
Truncated densities are probability density functions defined on truncated domains. They share the same parametric form with their non-truncated counterparts up to a normalizing constant. Since the computation of their normalizing constants is usually infeasible, Maximum Likelihood Estimation cannot be easily applied to estimate truncated density models. Score Matching (SM) is a powerful tool for fitting parameters using only unnormalized models. However, it cannot be directly applied here as boundary conditions used to derive a tractable SM objective are not satisfied by truncated densities. In this paper, we study parameter estimation for truncated probability densities using SM. The estimator minimizes a weighted Fisher divergence. The weight function is simply the shortest distance from a data point to the boundary of the domain. We show this choice of weight function naturally arises from minimizing the Stein discrepancy as well as upperbounding the finite-sample estimation error. The usefulness of our method is demonstrated by numerical experiments and a study on the Chicago crime data set. We also show that the proposed density estimation can correct the outlier-trimming bias caused by aggressive outlier detection methods.
翻译:修剪的密度是被修剪的域域定义的概率密度函数。 它们与非修剪的对应方具有相同的参数形式, 直至一个正常的常态。 由于正常常数的计算通常不可行, 无法轻易地应用最大隐利性估计来估计疏松的密度模型。 评分匹配( SM)是仅使用未经调整的模型来调试参数的强大工具。 但是, 它不能直接在这里应用, 因为用于得出可分解的 SM 目标的边界条件不能通过脱节的密度来达到。 我们本文研究的是使用SM 来计算变速概率密度的参数估计。 估测器将加权的飞利差最小化。 重量函数只是从数据点到域边界的最短的距离。 我们显示这种权重函数的选择自然产生于尽可能缩小斯坦差异, 以及上下限的定值估测值错误。 我们的方法的有用性通过数字实验和对芝加哥犯罪数据集的研究来证明。 我们还表明, 拟议的密度估计可以纠正侵略性测算出的偏差的方法。