一文理解Ranking Loss/Margin Loss/Triplet Loss
点击蓝字
关注我们

前言
ranking loss函数:度量学习
ranking loss的表达式
-
使用一对的训练数据点(即是两个一组) -
使用三元组的训练数据点(即是三个数据点一组)
成对样本的ranking loss
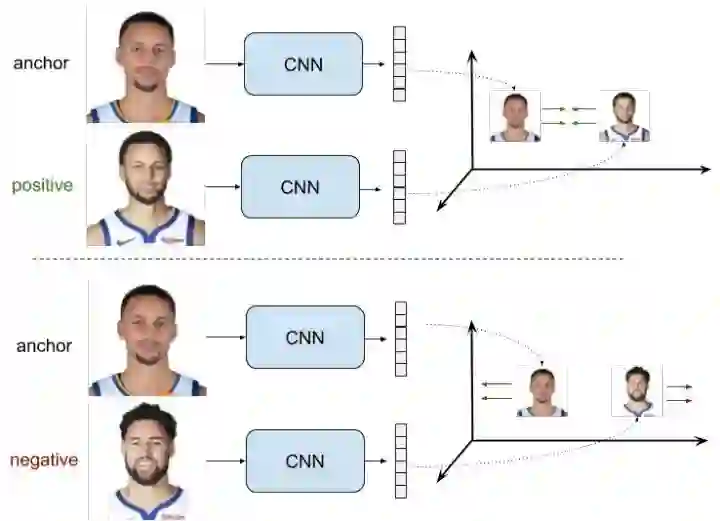
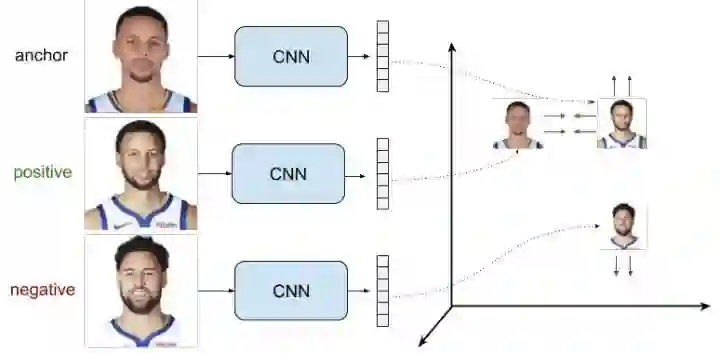
三元组样本对的ranking loss
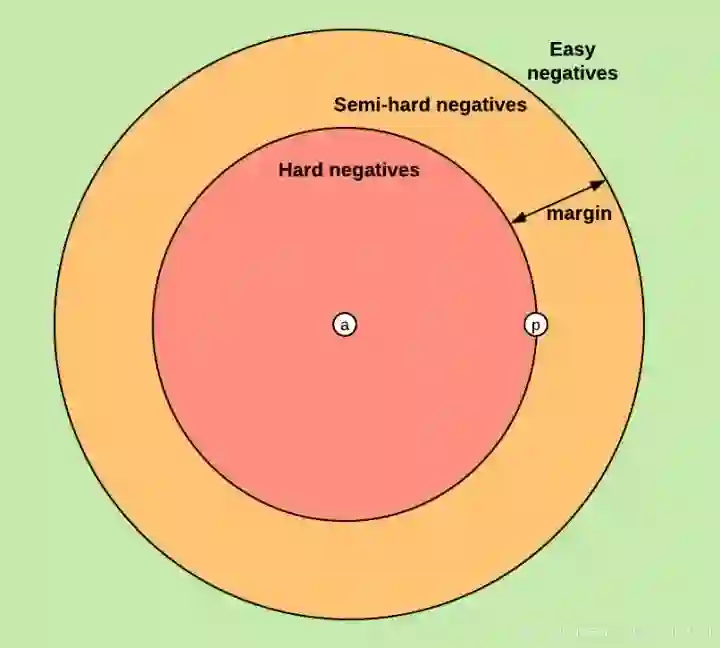
负样本的挑选
ranking loss的别名们
Siamese 网络和Triplet网络
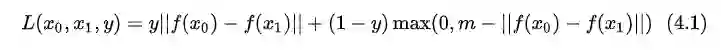
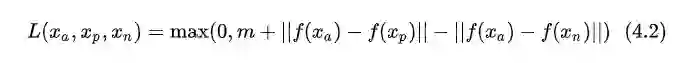
在多模态检索中使用ranking loss
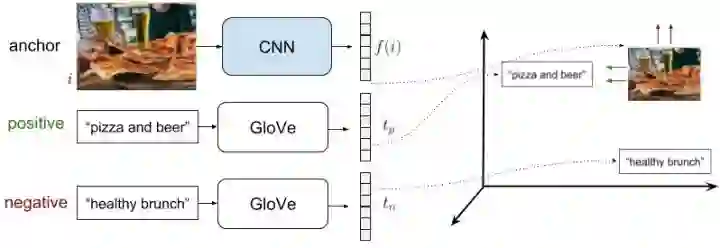
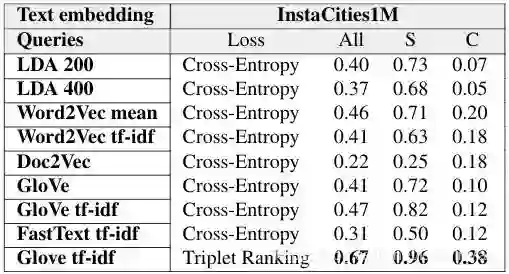
深度学习框架中的ranking loss层
Caffe
PyTorch
TensorFlow




登录查看更多
相关内容
专知会员服务
11+阅读 · 2020年5月25日



相关VIP内容
专知会员服务
11+阅读 · 2020年5月25日
相关资讯
相关论文