CVPR 2022 | 南大提出:Structured Sparse R-CNN:单阶段端到端场景图生成器
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:王利民 | 已授权转载(源:知乎)编辑:CVer
https://zhuanlan.zhihu.com/p/492255428
本文介绍我们在场景图生成 (Scene Graph Generation, SGG) 领域的工作——Structured Sparse R-CNN for Direct Scene Graph Generation。本工作将端到端稀疏目标检测器引入场景图生成领域,并提出了相应的关系建模组件和训练策略。该模型在 Visual Genome, Open Image V4/V6 数据集上取得了 SOTA 效果。论文和代码及模型已经开源:

论文:
https://arxiv.org/abs/2106.10815
代码(已开源):
https://github.com/MCG-NJU/Structured-Sparse-RCNN
研究背景
场景图生成任务,即,在图片中检测物体并预测物体之间的关系。检测出的物体和关系可以构成一张图(Graph),即场景图(Scene Graph)。
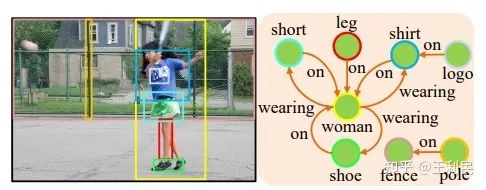
因此,在一张场景图中,物体和关系可以构成 三元组 (triplet),即 <主语, 谓语, 宾语>,其中,主语和宾语均为物体,谓语为关系。当然,(主语, 宾语) 可以构成一个 物体对 (object pair)。
研究动机
目前流行的场景图生成范式是多阶段的,包括:(1)图像物体检测;(2)关系图构建,选出潜在存在关系的物体对(也可以选全部的物体对);(3)关系分类,对筛选出的物体对的关系进行多分类。显然,这一套多阶段的范式十分复杂,并且关系分类依赖于前置的目标检测器。
事实上,有意义的关系具有稀疏性。如上图,像 <leg, on, woman> 和 <logo, on, shirt> 之类的三元组很容易被人们表达出来,而有的物体对,类如 (logo, leg),它们之间的关系则一般不会被人们关注到。因此,SGG 的主要目的就是将这些稀疏的、有意义的三元组检测出来。然而,之前的一大部分多阶段模型也没有考虑这种稀疏性。
近期,一系列基于查询的端到端稀疏目标检测器被提出,这一类能学习先验的检测器驱使我们去思考一个问题:在场景图生成领域中,是否也存在一种端到端的稀疏三元组检测器,能学习到这种稀疏性?答案是肯定的,在本工作中,我们提出了 Structured Sparse R-CNN,一种基于查询的、端到端稀疏三元组检测器。该检测器结合一组三元组查询,直接预测图像中的三元组分布。
在实验过程中,我们发现,在场景图生成领域中,直接套用目标检测的那一套范式会导致训练有一定难度。因此,我们提出了针对三元组检测的 3 点改进:(a)局部关系建模;(b)二阶段三元组标签分配策略;(c)针对三元组中物体标注类不均衡问题的损失函数修改。
方法
网络结构
主体
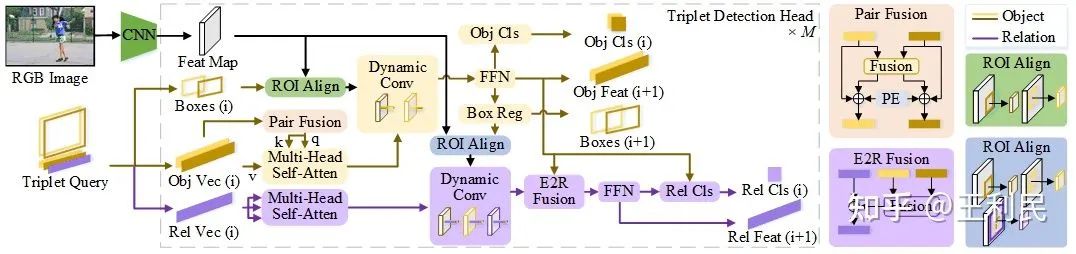
我们的网络可以视为是稀疏目标检测器 - Sparse R-CNN 的一个拓展。我们的网络由 CNN 、三元组查询和一系列三元组检测头组成。 三元组查询对物体框、对象表征和关系表征的先验信息进行编码。检测器以 CNN 特征和三元组查询作为输入,并使用两个级联模块(标记为黄色和紫色)逐步提炼检测结果:黄色部分进行物体对的检测,紫色部分进行关系识别。 三元组查询和检测头权重通过反向传播进行联合优化。图中,(i) 表示当前检测头的索引, PE 表示位置编码。
物体对检测:三元组的主语物体向量和宾语物体向量(上图的 Obj Vec (i) 中,深黄色和浅黄色)经过物体对融合 (Pair Fusion),再一起经过多头自注意力模块,然后,在各自对应的物体框 (Boxes) 上进行动态卷积,最后这两种向量分别经过 FFN 和分类头、回归头,来产生主语物体和宾语物体的检测结果。
关系识别:三元组的关系向量经过多头自注意力模块,再在其主语物体框、宾语物体框、主宾物体框并集上分别做三次动态卷积,产生结果后,经过物体到关系的融合 (Entity to relation Fusion, E2R Fusion),再由关系识别部分的 FFN 和分类头产生关系分类结果。
局部关系建模
对关系建模的最主要部分为,上图的紫色部分中,专属于关系特征的一系列模块,即,紫色标注的 Multi-head self attention、Dynamic Conv、FFN、Rel Cls。
此外,我们回顾了之前场景图生成领域的做法,即关系特征和物体特征的融合 (fusion)。我们提出了 2 种融合方式:(1)物体对融合 (Pair Fusion);(2)物体到关系的融合 (Entity to relation Fusion, E2R Fusion)。
物体对融合
在物体对检测(上图黄色部分)的多头自注意力机制 (Multi-Head Self-Attention, MHSA) 中,所有物体向量被混在一起送入该模块。这导致一个问题,即,每个物体不知道其在本来的物体对中,对应的另一个物体是谁。例如,在进行 MHSA 时,某个物体对的主语物体向量无法确认其对应的宾语物体向量是哪一个。因此,为了解决这个问题,我们的方法是:以一种类似于物体位置编码的方式,对每个物体向量加上一种约束。
具体的过程很简单,就是通过一组 MLP 把每对物体向量混合一下,此外,我们将每个物体向量对应的物体框的位置编码也融入进去。对融合之后的向量,则作为 MHSA 的查询向量和关键词向量的输入。
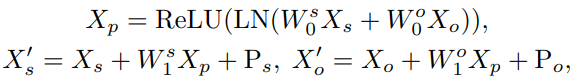
物体到关系的融合
将物体特征融入对应的关系特征的操作在之前场景图生成方法中比较常见,因此,我们也沿用这一思想,将主语物体特征和宾语物体特征融入它们的关系特征中。
网络训练
二阶段三元组标签分配策略
我们的网络是直接输出三元组结果的,因此,不像之前的 SGG 模型分多步进行物体标签分配和关系标签分配,我们的模型需要一种直接的三元组标签分配。这又带来一个问题:由于前文提到的关系稀疏性,三元组标签覆盖的物体样本很少,如果我们直接沿用稀疏目标检测器的标签分配(即,先把所有标签通过二分图匹配分给输出结果,再把没有分配到标签的结果全部视为拥有背景标签),就是会使得物体对检测部分的网络训练不充分。
那么我们会去考虑,能不能将所有物体的人工标签两两组合成物体对标签,把它们直接送给网络进行匹配?当然,单从匹配算法的执行上面来看,是可行的。因为,基于二分图匹配的标签分配策略是无向的。对于这种策略来说,它可以被看成从网络预测结果到标签的匹配,同时也可以看成,从标签到预测结果的匹配。查询的数量和标签的数量仅仅对这个匹配算法而言是没有影响的。
但这如果再考虑损失函数的话,其实还是不可行的:如果我们把物体标签两两组合来产生物体对标签,这样会使得这种标签的数量特别大。此时沿用上述的标签分配策略的话,会导致某个训练图像样本中,三元组查询都被强行分配了前景类别标签,没有背景类别了。
此时,我们可以去思考一个问题:是否存在一种特殊的物体对标签集合,这个集合里面,包含尽可能多的真实物体标签,同时,还能包含一类特殊的物体标签,它们虽然表示背景类,但却有定位框。
显然,这种标签集合从人工标注的角度来讲绝对不常见。但是,当我们没有现成的标签集时,我们可以去考虑半监督学习里面的伪标签策略。因此,我们的目标就是:如何产生一组既表示背景类、还要有定位框的伪标签。
答案呼之欲出,就是拿另一个目标检测器产生这些伪标签。
具体而言,一个目标检测器产生很多个物体预测,然后将这些物体检测结果两两组合成 O(N^2) 级的物体对,作为一个物体对集合。这个物体对集合,既包含了真阳性的物体预测,也同时包含了很多假阳性的物体预测。由于上文说到,我们需要的是尽可能多的真实物体标注,以及拥有物体框的背景标签。所以,对于这个集合,我们可以仅仅保留假阳性物体预测的定位框,而将其他的预测都替换成真实标签和背景标签。
至此,伪标签集合大体上制作完成了。接下来就是把里面的和真实三元组标签重合的一些伪标签删除,剩下来的元素组合成集合 P。现在,我们就需要考虑怎么将这个集合 P 用起来了。由于上文提到,基于二分图匹配的标签分配有一种无向性,那么,我们的标签分配其实就是在集合 P 和物体对预测之间找一种相似性。所以,我们考虑让产生集合 P 的目标检测器的输出和三元组检测器的输出同步变化,即,我们同时训练这 2 个检测器,让每次迭代时,目标检测器产生的集合 P 都要去引导三元组的检测,让三元组的检测结果更“像“伪标签集的分布。
此外,我们发现,物体对检测部分和目标检测器的权重可以共享,这并不会让训练崩溃。
总体训练流程如下图:
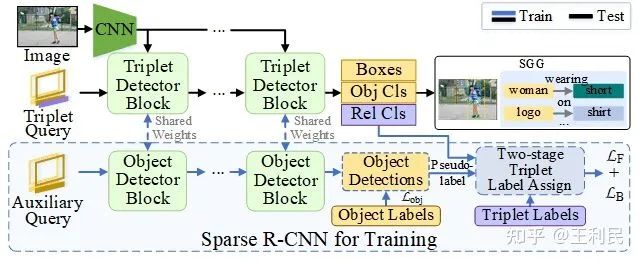
现在,知道了这套训练的大体框架,理解我们的二阶段三元组标签分配策略就很容易了:
阶段一,三元组标签通过一次二分图匹配,被分配给一些三元组预测。二分图匹配的费用为,主语、宾语物体的分类和回归损失的和,再加上关系分类损失:
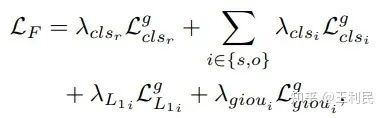
阶段二,剩下的三元组预测通过一次二分图匹配,被分配给集合 P 的元素。二分图匹配的费用为,主语、宾语物体的分类和回归损失的和:
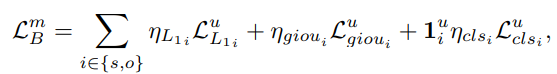
标签分配结束,两个阶段均要产生损失函数。阶段一产生的损失函数和阶段一的费用一致;而阶段二的损失函数,则需要把伪背景标签的定位框掩盖掉(注:这并不意味着这些定位框没用,它们直接影响了每个三元组预测得到的物体标签,相当于把标签的分布修改了)。此外,我们把一阶段没匹配真实关系标签的关系预测也算入二阶段:
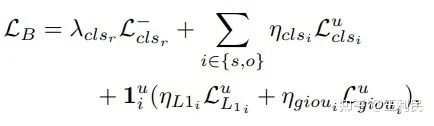
因此,最终的损失函数为:
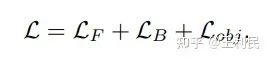
三元组中物体标注类不均衡问题
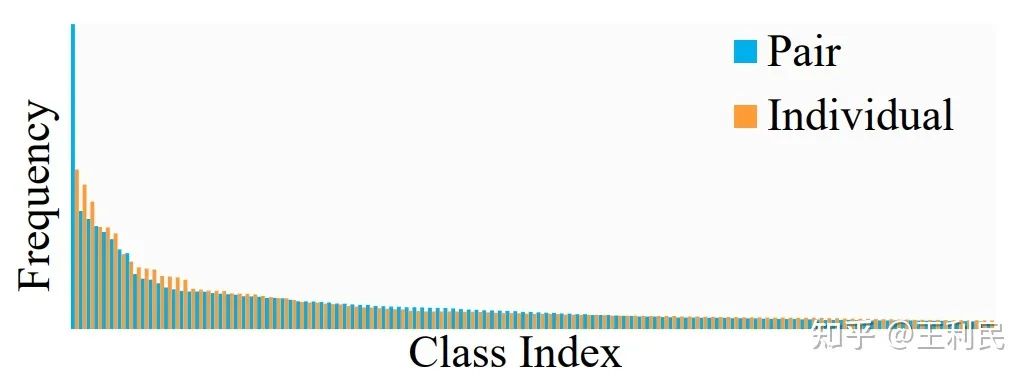
我们统计发现,三元组标签覆盖的物体和人工标注物体的频率分布是不一致的,如下图,个别物体在三元组里面频率过高,让别的物体频率相对减小:
虽然我们的二阶段三元组标签分配策略加了很多物体标签进来训练,但由于实际操作中,阶段二的损失函数的权重比阶段一小,所以这个问题其实仍然存在。因此,受之前工作的启发(引用见原文),我们改了一下用于物体分类的 focal loss 的参数,让它和类别频率相关:
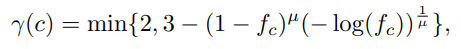
虽然函数形式比较复杂,但主要目的很简单,就是给尾部类别的权重相对大一点。
实验
消融实验
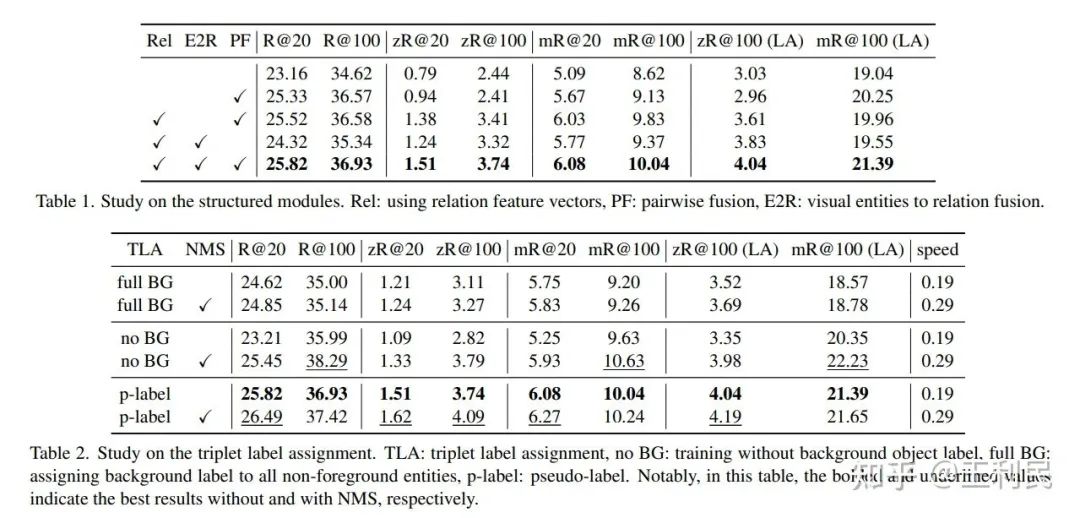
针对上述模块,我们进行了消融实验,可以发现,模块的影响都比较大。其中,影响最大的为基于结构化的交互的关系建模:

对比其他模型
Visual Genome 的结果
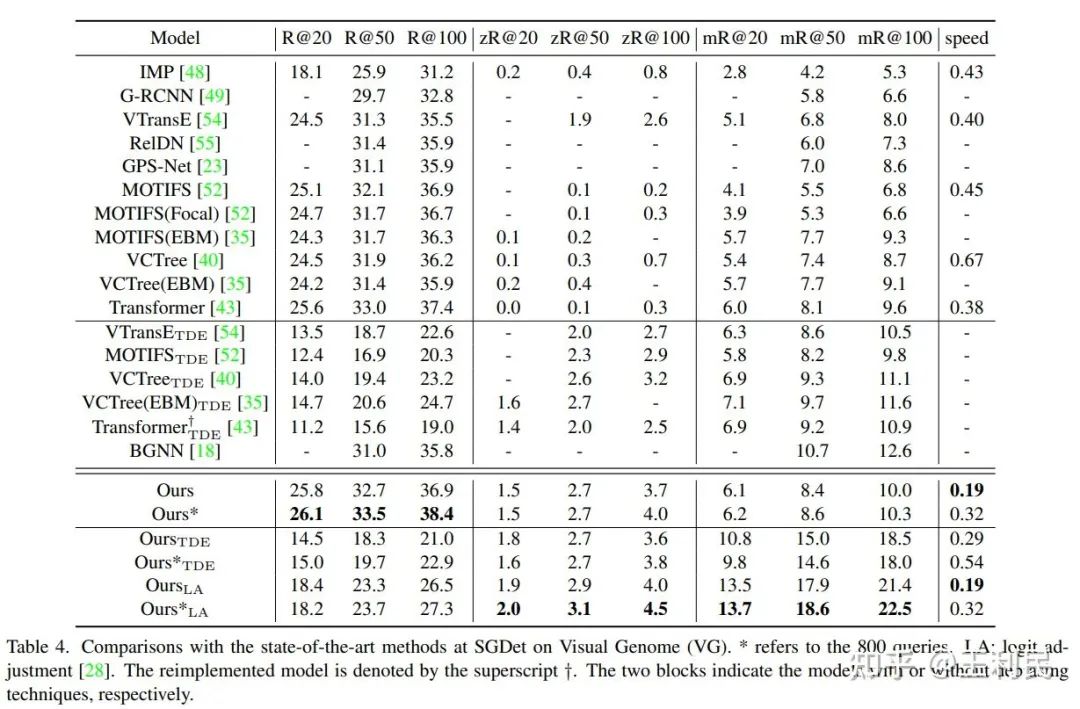
在 Recall 上,我们发现,300个查询已经能和之前的方法匹敌,更多的三元组查询能带来更强的效果(表中 * 的表示更多的三元组查询,800个)。此外,因为端到端检测器不需要 NMS,所以,在同一台服务器上测出来的推理速度中,我们的模型还算比较快的。
在 zero-shot Recall 和 mean Recall 上,我们发现,当不在关系分类上使用一些长尾的技巧(TDE,以及 Logit Adjustment, LA)时,我们的模型比以前的模型高一些。而使用这些技巧之后,我们的效果很好,可能是因为我们的模型跟长尾分类的方法配合的比较好(直接针对关系向量的建模;以及一对一的关系标签分配,让标签频率和统计量比较一致了)。
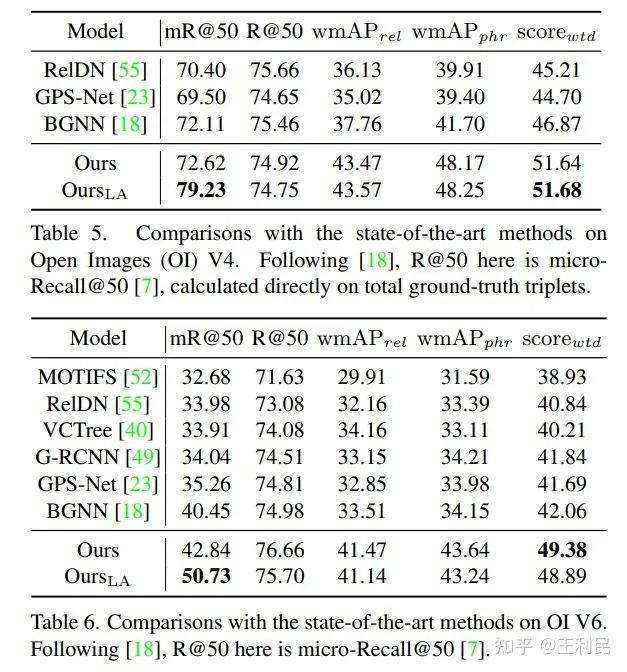
其他数据集的结果
结论
本工作将端到端稀疏目标检测器引入场景图生成领域,并提出了相应的关系建模组件和训练策略。希望我们的文章能够进一步推进场景图生成领域的研究,发掘端到端检测器在场景图生成上的具体作用。
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-Transformer或者目标检测 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer或者目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看