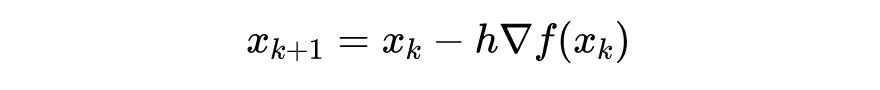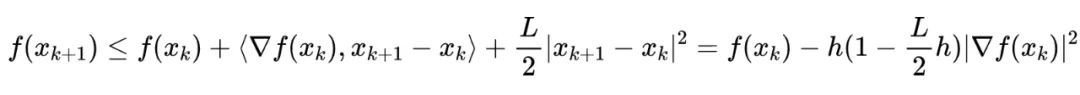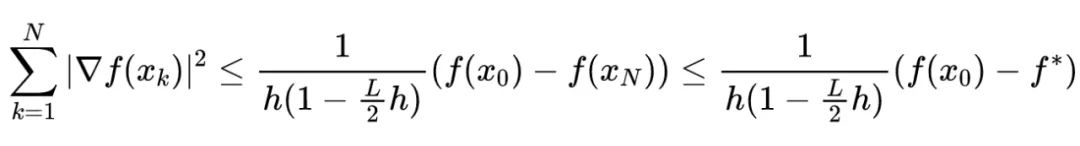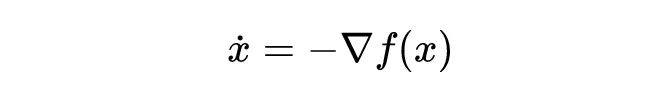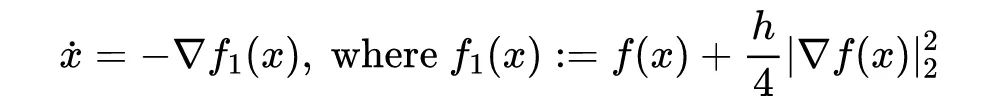本文是陶默雷 Molei Tao 和王雨晴 Yuqing Wang 的一篇博客的中文版。
©PaperWeekly 原创 · 作者 | 孔令凯、陶默雷
1.1 梯度下降法
在机器学习中,人们经常使用一阶优化器(1st-order optimizer)来训练模型。一阶优化器是指只利用一阶导数的迭代优化算法,其中最著名的是 梯度下降法(Gradient descent, GD) 。尽管从 GD 衍生出来了一系列强大的算法,这篇文章我们着重讨论 GD(虽然它的很多结论都可以推广到其他的算法里去)。GD 算法的迭代是:
其中
是
学习率 (learning rate, LR. 数值计算的领域也称之为步长 stepsize)
1.2 传统的学习率选择
很多时候,在机器学习和优化的领域,人们会分析具有
光滑性 (smoothness)的目标函数。在机器学习和优化方向的术语里,一个函数
被称为
-
smooth 是说
是全局
-利普希茨(Lipschitz)连续的。这是一个很强的假设(例如,在这种定义下,
是 2-smooth 的,但
就不是 smooth 的)。
虽然有些时候是这个条件可以放宽的(例如,我们可以做局部 smooth 的假设,或者利用定义域有界的性质),但是首先,让我们来看看在
-smooth 假设下,能得到什么结论。
定理: 给定一个
-smooth 的函数
,并且已知
的极小值
存在,那么当学习率满足
时,GD 收敛到一个驻点(stationary point)。
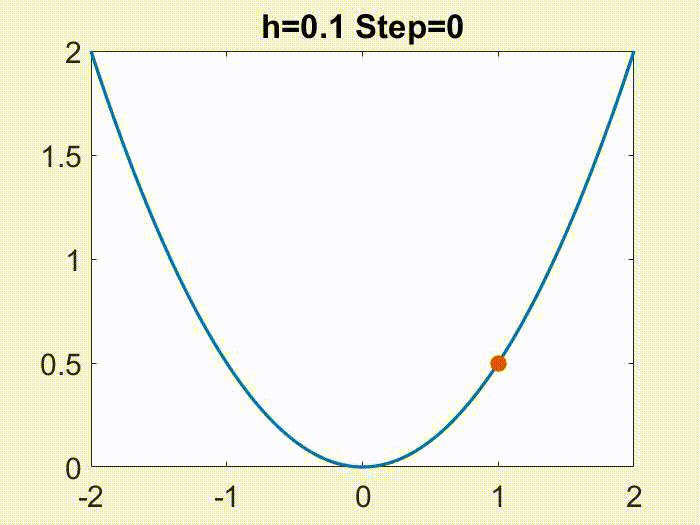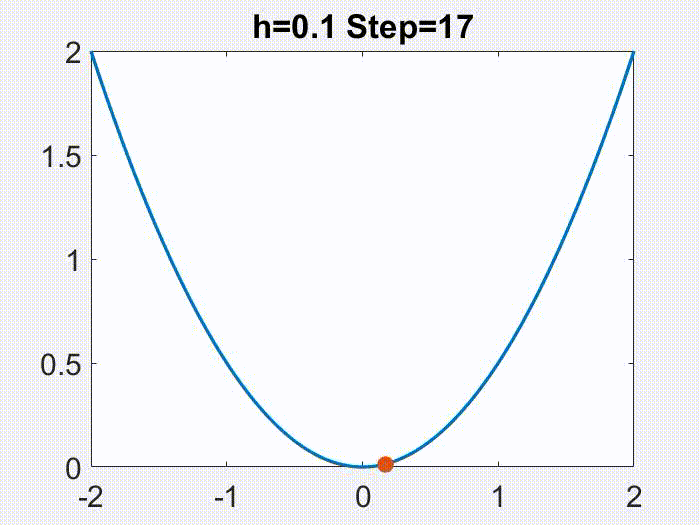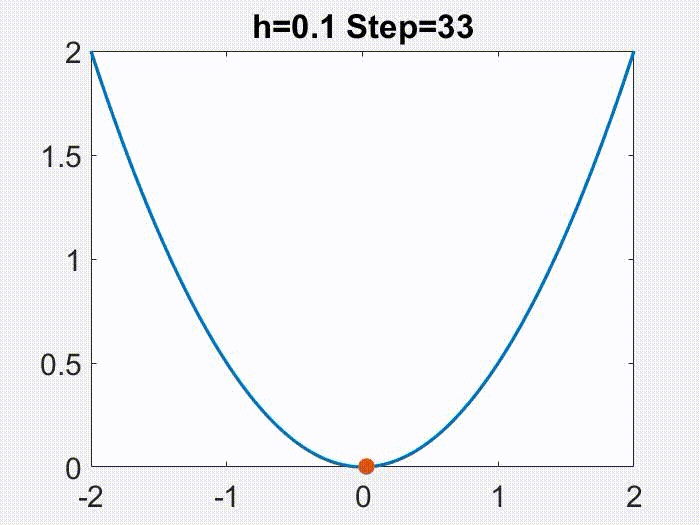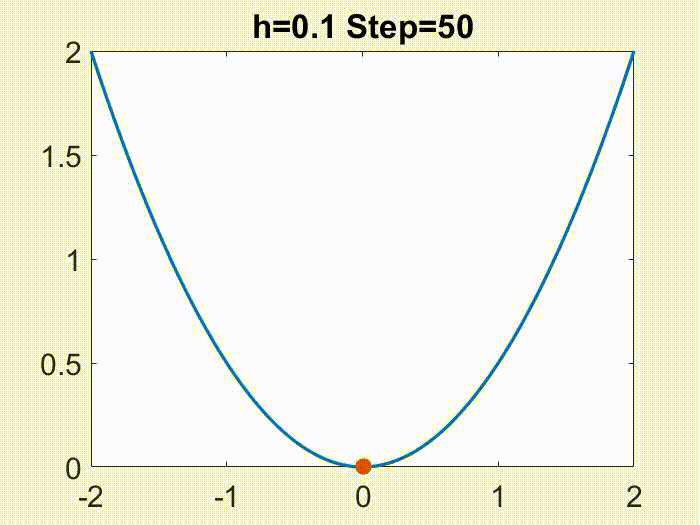
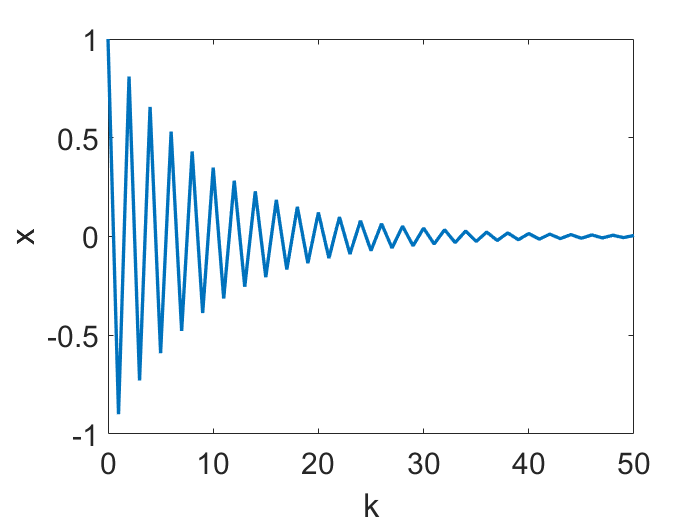
这个定理告诉我们,学习率
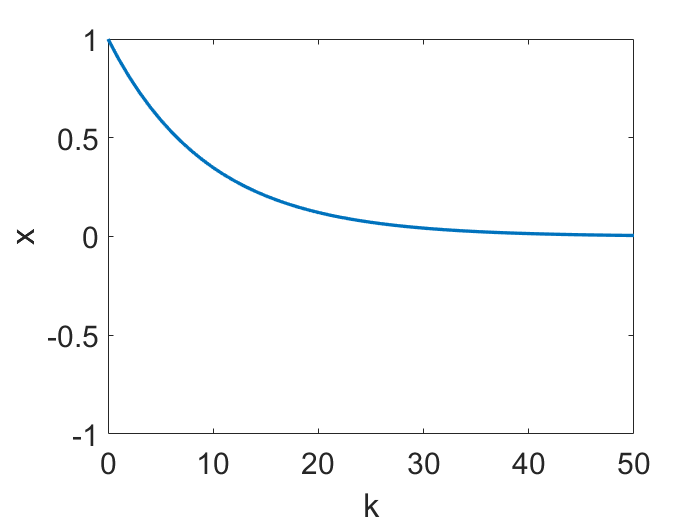
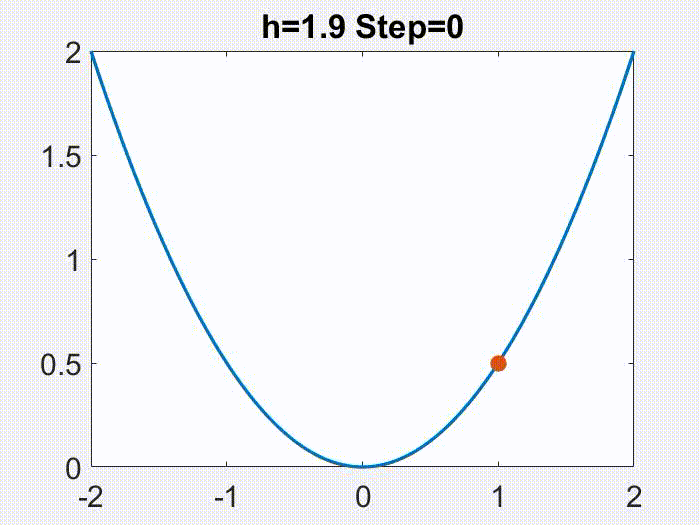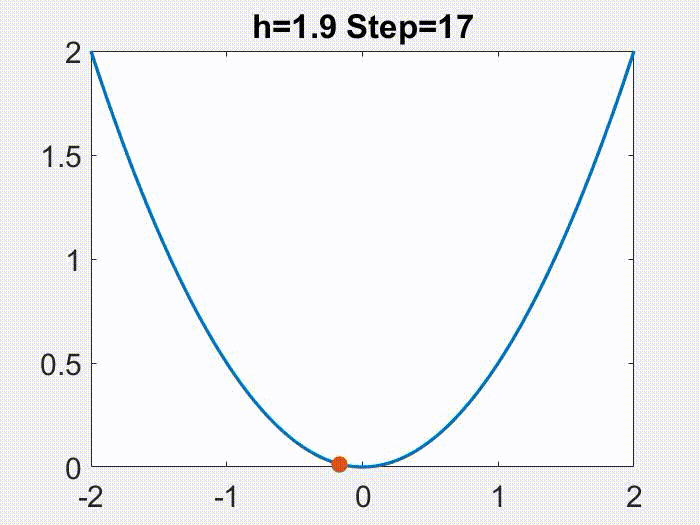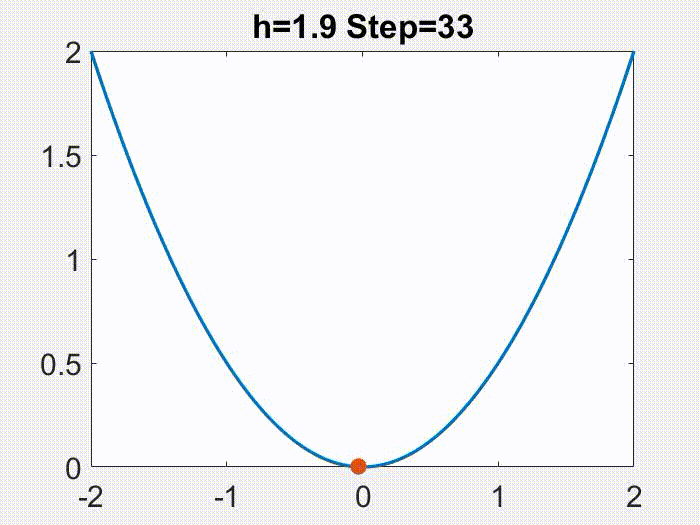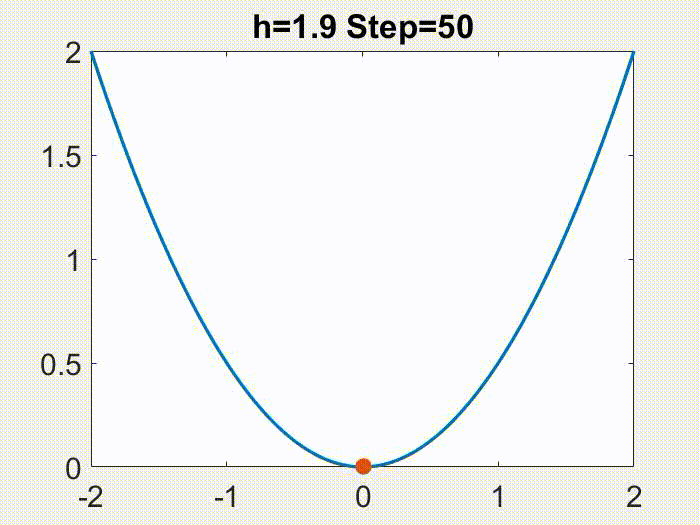
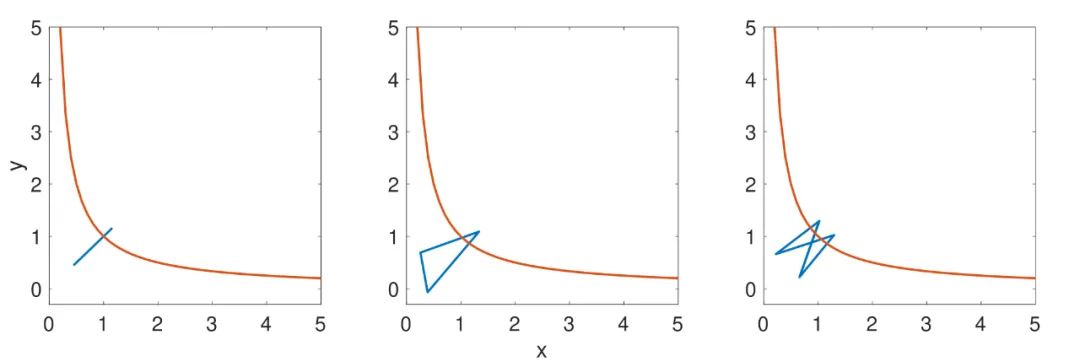
是一个有很好性质的区间。有意思的是,这个学习率的范围还可以划分成两个部分。就像下面的动画在目标函数
上面展示的,当
时,x 的轨迹是近似于单调且连续变化的,但是更大的学习率会导致一个不连续的,震荡的轨迹(仅仅
是震荡的,
仍然是单调下降的)。
1.3 这个简单学习率区间的最简单部分,以及此时GD和梯度流的关系
熟悉数值分析的朋友们或许可以很快的意识到, GD 可以看作由
梯度流 (gradient flow)的常微分方程(ODE)。
用显示欧拉法离散得到的。显然,在连续时间极限(h 无限小)的时候,x 是连续变化的。有兴趣的朋友可以试试,如何用经典数值分析的方法来得到上一节提到的
这个条件。这种学习率使 GD 很接近梯度流,因此我们称之为
小学习率(small LR) 。
然而,随着
增大,GD 偏离梯度流越来越多。显然,GD 在
的时候和梯度流的表现相去甚远。
2.2 后向误差分析(修正方程)
梯度流只反映了 GD 在
足够小的时候的表现,但是常微分方程也可以帮助我们理解更大
的效应。考虑到梯度流是 GD 的无穷小学习率的极限,如何理解不是无穷小的
的情况呢?答案是,我们可以在原来的
上面添加
的项来修正
不为 0 的带来的影响,就像泰勒展开一样。
数值分析中这种技术被称为“ 后向误差分析 ”,被修正过的 ODE 被称为 修正方程 (modified equation)。这个美妙的想法至少可以追溯到 [Wilkinson (1960)],经典的教科书 [Hairer, Lubich and Wanner (2006)] 则提供了非常棒的综述。
现在我们用修正方程来分析一下 GD。对梯度流做
的一阶修正会给出:
这是 GD 在
意义下的近似(0 阶修正方程就是
)。可以看到,一阶修正方程依然是一个梯度流,
也因此被称为(一阶)修正势能。
2.3 讨论
一阶修正方程
是很有用的。例如它可以用修正过的的目标函数来刻画由 GD 的离散化带来的隐式偏差(implicit bias,有时也被称为隐式正则化 implicit regularization)。今年已经是 2022 年了,机器学习社区也还在不断发现其在机器学习方面的应用。然而,方法本身并不是新的。
事实上,获得
的表达式并不困难,仅仅通过匹配 GD 的迭代表达式和
的泰勒展开就可以得到。然而这种“推导”仅仅是形式上的,甚至让人错误地认为修正方程对于任意大的
都好使。然而,(关于
的)幂级数存在收敛半径,同样,拓展到 ODE 后的幂级数也会有收敛性的问题。
一篇漂亮的论文 [Li, Tai and E (2019)] 超越了形式上匹配级数的非严格方法,严格刻画了在
足够小的时候一阶修正方程的误差。它所需的条件也更弱(SGD),而 GD 则是此文中的一个特例。其他一些较早的文献也已经给出了 GD 情况的表达式。例如(尽管这不是他们论文的重点),[Kong and Tao (2020)] 提供了
的表达式,并定量讨论了什么情况下,
(或者是任意高阶的修正势能
)是不够的。
尽管
可以在
更大的时候比
更好地逼近 GD。但它并没有解决所有的问题。这种方法在
太大时也会失效。
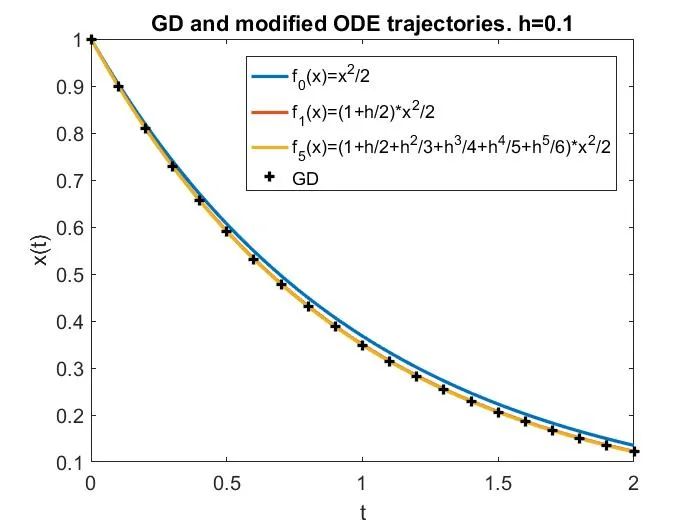
既然在
大时,一阶修正方程不够好,那么高阶的修正方程会更好吗?在大多数情况下,答案是否定的,甚至如果
太大了,修正方程的阶数越高,逼近效果反而越差。
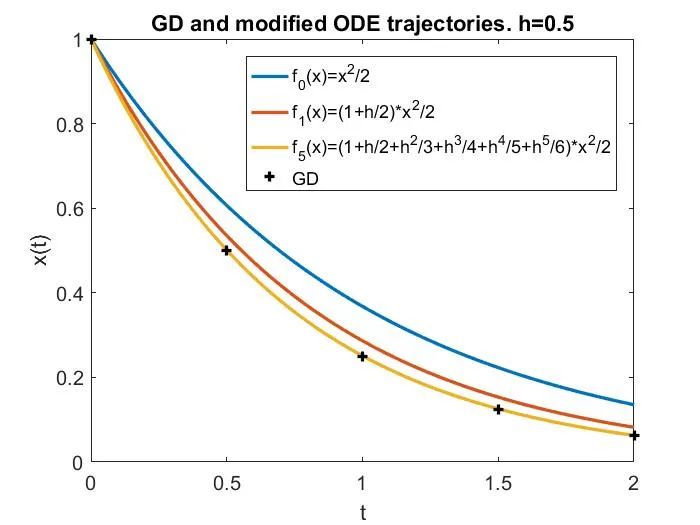
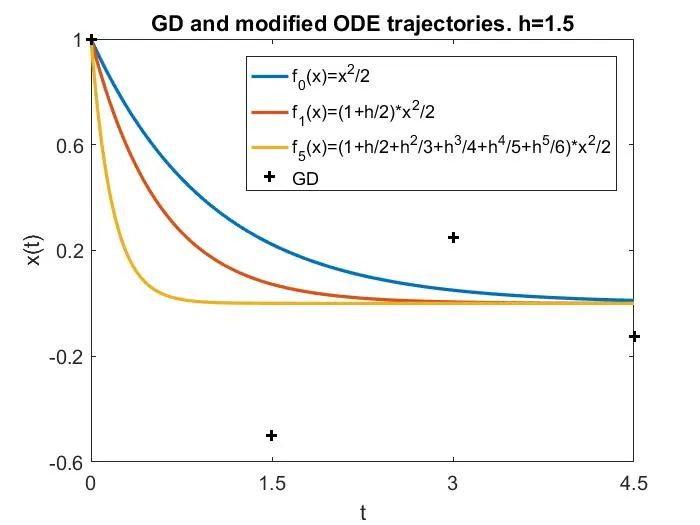
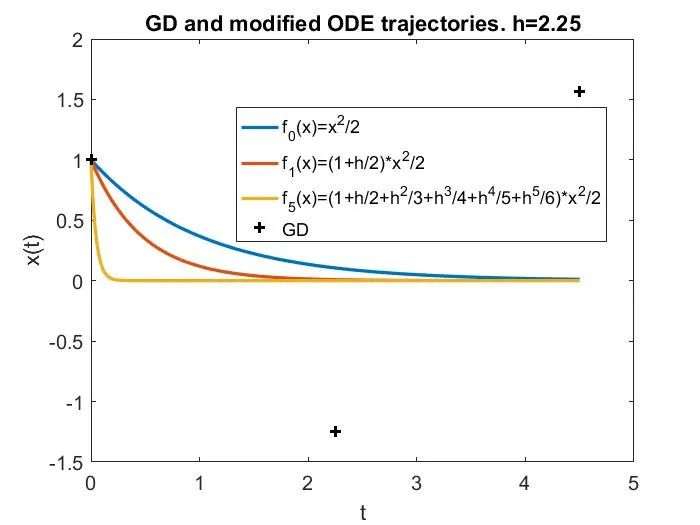
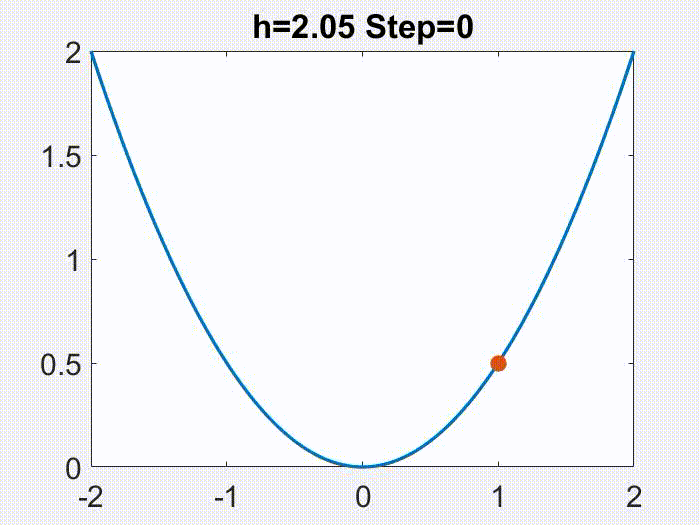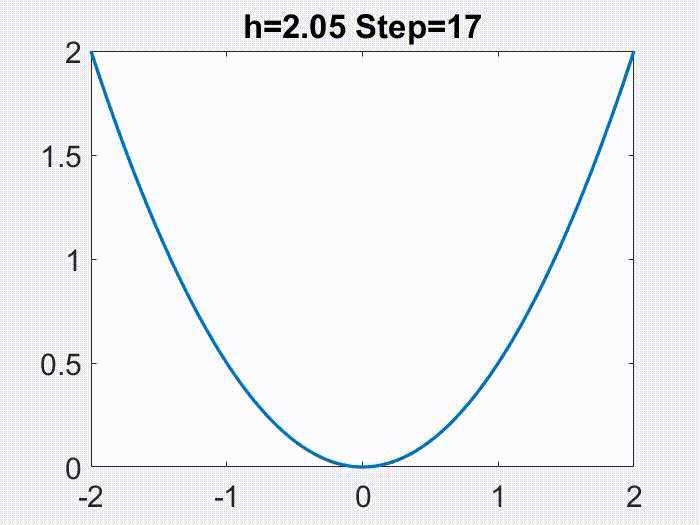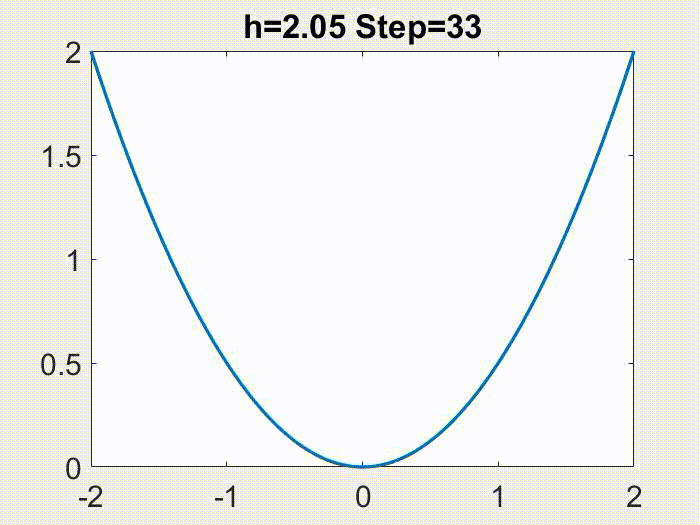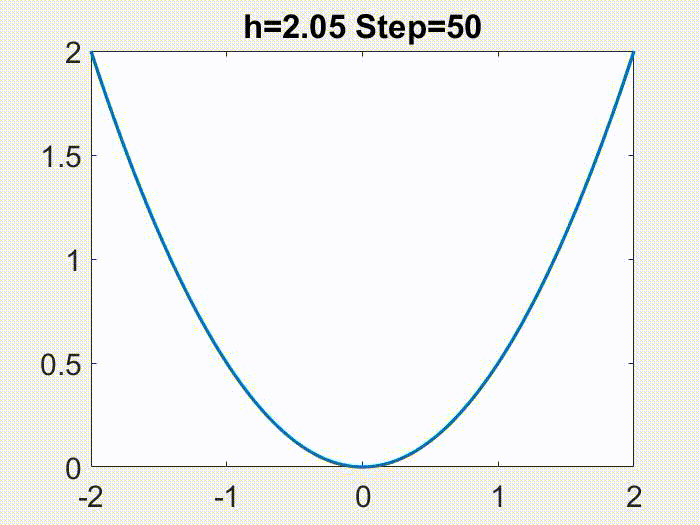
这可以通过下图来说明,其中 LR 分别为 1)接近于 0 的小学习率,此时梯度流很好地近似 GD;2)中等但仍然
,此时尽管梯度流不是 GD 很好的近似,但修正方程可以很好地近似 GD;3)更大,处于
区间,此时修正方程也不再有效;4)真正的大学习率,
,此时 GD 在简单的目标函数
上发散。
需要注意的是,尽管一些文献使用修正方程来研究 “大” 学习率,但在这篇博客中,我们仍将这种 LR 称为中等大小的学习率。原因是,当 LR 进一步增大时,修正方程会完全失效,但 GD 可能仍能找到有效的极小值,并且此时会有很多非平凡且有趣的效应:这些效应经常是对深度学习有益的!下面是一些例子。
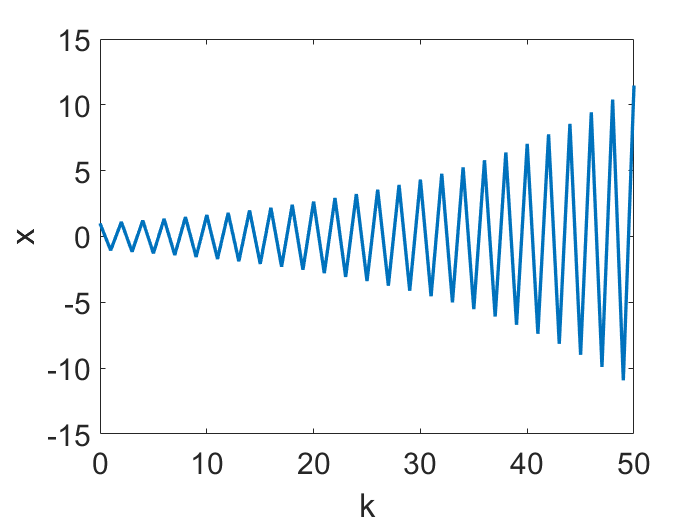
不收敛
人们的直觉或许是,LR 太大会导致 GD“爆炸”(即迭代得到发散的序列)。这种现象的确存在。如下图在
上的例子说明, 对于二次函数,当
时 GD 就会“爆炸”。
但是,对于更复杂的目标函数
, GD 不一定会在大学习率下爆炸。
更奇妙的是, 即使是在 GD 收敛的情况下, GD 也不总是收敛到一个点! 我们可以将 GD 迭代视为离散时间的动力系统。而动力系统可以有各种类型的吸引子(attractor),一些最常见的吸引子是不动点、周期轨道和奇异吸引子(没错,正是混沌,或者严格的说,很多情况下是混沌)。而他们都可以由 GD 产生!
下图是一个 GD 收敛到周期性轨道的例子,它来自于一个简化版的矩阵分解问题。其中
(注:尽管看起来简单,这个函数既不
-smooth,也不是凸的)。并且,它的 GD 迭代存在不同的周期,而图片中的 GD 迭代都不收敛到极小点。
时 GD 至少可以收敛到周期分别为 2, 3 and 4 的轨道,不同的轨道取决于不同的初始条件。图片中蓝线是周期性轨道,红线是所有满足
的极小点。
这些图片来自 [Wang et al (2022)](尽管这不是那篇文章的重点)。更多内容将在下下节中讨论。
现在让我们看一个 GD 收敛到混沌吸引子的例子(著名的洛伦兹蝴蝶是另一个混沌吸引子的例子)。
这些图片来自 [Kong and Tao (2020)]。下面是更详细的解释:
上面的势能有很多个 spurious 局部极小点。令人惊讶的是,就像动画表现的那样,GD 可以跳出这些局部极小点。
这背后的原因是大学习率!事实上,如果应用了小学习率,就像梯度流一样,GD 只会收敛到一个接近于初值的局部极小点。
人们最近开始赏识大学习率的这种效应,有趣的实验结果不断出现。一个主要的原因是,深度学习社区对于跳出局部极小点很感兴趣,因为这能提高训练的精度。跳出局部极小点,最流行的的方法是利用随机梯度带来的噪音。而大学习率提供一个截然不同的方式,即使梯度的完全确定性的,也依然有效。[Kong and Tao (2020)] 已经提供了严格的定量分析,主要想法如下:
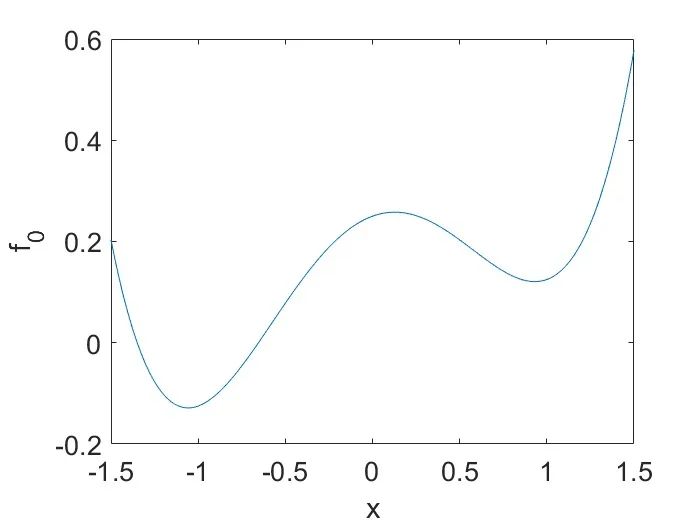
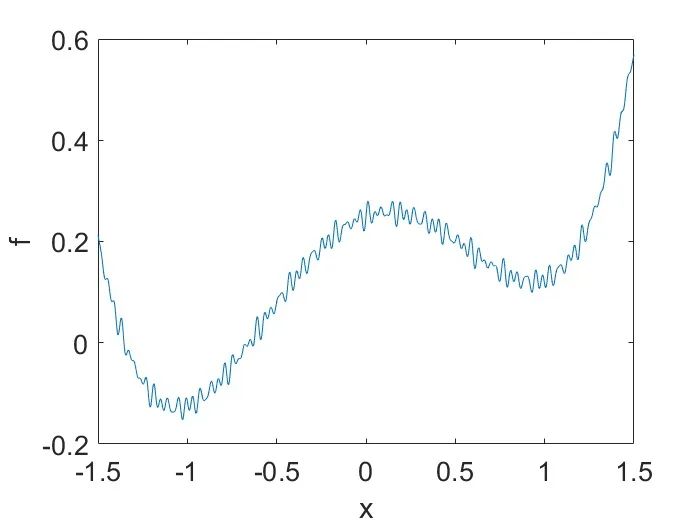
给定目标函数
,假设可以将其分解为
,其中
是宏观趋势, 而
表示微观细节,例如下图展示的一维函数:
直观来说,如果车开得很快,就感觉不到路上的小坑坑洼洼了。同样,当 LR 变得足够大时,GD 就不再能够解析
中的微观细节。那么,多大是“足够大”呢?用
表示微观尺度(与宏观尺度相对)并假设
是
-smooth 的,那么
(由二阶导数得出),这意味着传统的小 LR 是
。因此,如果
独立于
,那么我们有
, 此时学习率就是足够大的。
在这种模型下,[Kong and Tao (2020)] 严格证明了在
确定性的 GD 算法中, 微观部分的梯度(
)导致的效果很像是额外加上了噪音。事实上,使用来自动力系统、概率论和泛函分析的工具,此文在合理的假设下证明了 GD 迭代实际上收敛到一个混沌吸引子,因此 GD 给出的结果收敛到一个非常接近于
的概率分布。
熟悉统计力学的读者知道这就是著名的吉布斯分布(Gibbs distribution)。值得注意的是,这种 GD 的极限分布仅取决于目标函数的宏观部分(
),而微观细节
由于大 LR(
)的使用而消失了!
这一定量结果还表明,得到较小的
值(这也意味着较小的
值)的概率(显著)的更高。通俗来说,这意味着 GD 将更频繁地访问它们。通常情况下这是人们想要的(因为较小的训练损失很可能意味着更小的测试误差),因此,这是大学习率的一大好处。
在这种意义上,尽管 GD 没有随机性或小批量梯度(minibatch),但是大学习率的 GD 的行为 SGD 与 SGD 非常相似。它提供了另一种跳出极小值的方法!
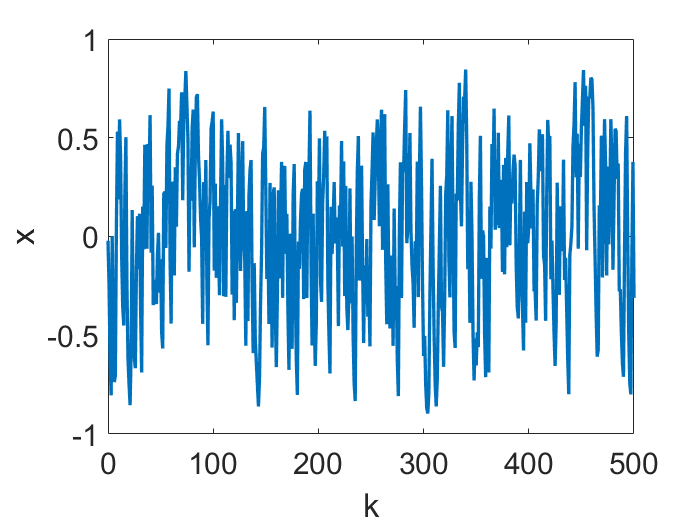
更多细节可以在 [Kong and Tao (2020)] 中找到,但让我们再最后摘录一个文中的讨论:现实问题中的目标函数,是否也存在这种多尺度结构?此文中同时包含了理论和实验的讨论。例如,如果训练数据是多尺度的,那么对于一个(非线性的)回归任务,理论上来说,神经网络的损失函数有可能继承这个多尺度结构!下面是小型前馈网络用 GD 训练时一个权重的变化:
可以看到它不收敛到一个点,而是“一堆点”,这实际上是混沌吸引子,也可以用概率分布来定量化的描述。
总结 [Kong & Tao (2020)] 表明,在大学习率的帮助下,GD 可以避开局部极小值并指数地倾向更小的局部极小值。这是因为,由于大 LR 产生的混沌动力学, GD不再是仅仅优化目标函数, 而是对概率分布进行采样。
3.3 大学习率导致的隐式偏差(implicit bias):偏好更平坦的极小值
现在让我们回到 GD 收敛到一个点的简单情况。这种简单的情况比看上去有趣得多。这里我们只讨论一件事:严格证明大学习率偏好更平坦的局部极小值。但首先, 这件事有什么意义呢?
流行猜想1: 更平坦的极小点可以更好地泛化。有许多工作支持这种猜测,但有趣的是,也有许多工作支持截然相反的结果。在这里我们不准备提出任何新的观点,而只是希望大家同意找到更平坦的局部极小值这件事有意义。
流行猜想2:
大学习率有助于找到更平坦的极小点。尽管这个猜想最近才出现,但正迅速受到关注。目前已经有相关的实验结果,还出现了半理论的分析,例如一些基于一阶修正势能
中的
修正项的工作(关于修正势能,请见上文“后向误差分析, 又称修正方程”部分)。
[Wang et al (2022)] 则研究了真正的大的学习率,而不是修正方程能够研究的中等学习率。在这种情况下,GD 对于平坦极小值的偏好更加明显。对于一类目标函数,此文为
流行猜想2
提供了严格的证明。
更具体地说, 考虑一类矩阵分解问题。它可以看作优化问题:
即试图为
的矩阵
找一个秩
的近似。这个问题本身就是一个重要的数据科学问题,但对于那些对深度学习感兴趣的人来说,它与 2 层线性神经网络的训练也几乎是一样的。
这里的目标函数
很有趣。例如,1)极小点是不孤立且不可数的。事实上,如果
是一个极小点,那么对于任何常数标量
,
也是极小点。作者将此属性称为同质性(homogenity),即使加了某些非线性激活函数(例如
,其中
是 ReLU 或 leaky-ReLU),这种现象也会存在。2)每个局部极小点都是一个全局极小点。
然而,这些极小点中有些是平的,有些是尖的。事实上,这可以通过在
的极小点处计算 Hessian 矩阵的特征值来判断。一旦大家完成这个计算,不难证明
意味着极小点周围局部是平的,否则就是尖的。所以
和
是否相近非常的重要,作者称此为均衡性(balancing)。
事实上,除了对深度学习潜在的影响(平的极小点意味着更好的泛化(?))之外, 拥有更平坦几何形状的极小点也有利于 GD 的分析和数值表现(否则需要更小的 LR)。所以,已有的文献经常显式地添加正则项(regularizers),从而促进
和
的均衡性。
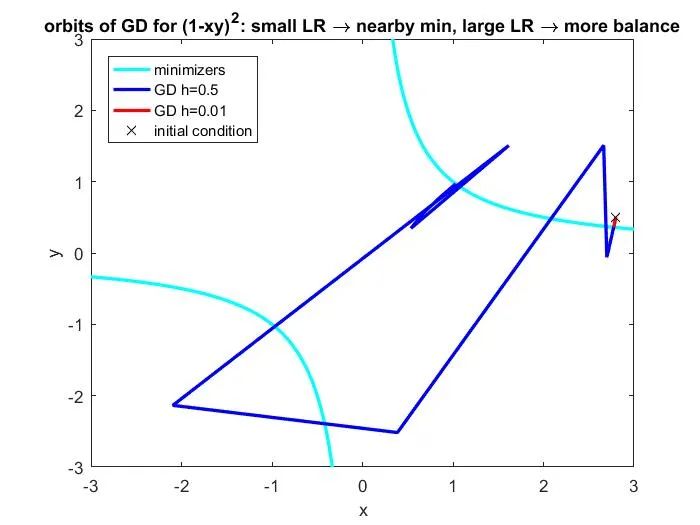
[Wang et al (2022)] 表明,如果 LR 足够大,GD 将开始倾向于选择具有均衡性的极小点。并且,LR 越大, 这种偏好就越强。这种对均衡的极小点的偏好并不需要通过额外的正则项得到。如下图所示, 即使初始条件已经接近不具有均衡性的极小点,并且小 LR 的 GD 确实会收敛到一个很近的极小点,大学习率的 GD 仍然会有截然不同的表现:它能"舍近求远"地收敛到一个更均衡的极小点。
注:[Wang et al (2022)] 也可以被认为与近期实验发现的一种被称为“稳定性边缘”(Edge of Stability)的现象有关 [Cohen et al (2021)], 这种现象正在迅速引起人们的关注。
更具体地说,[Wang et al (2022)] 证明了:1)如果 GD 收敛到一个点, 这个极限点
满足一个不等式,即
有一个上界,然后这个上界随着学习率的增大而减小;2)GD 的确收敛到一个点,即使学习率是真正大的那种。
这两个结论,第一个听起来很拗口(但很重要),第二个听起来则很容易;然而事实是,结论 1)可以使用动力系统现有的工具比较容易的得到,而结论 2)更不平凡。这是完全是因为大学习率造成的分析的困难。尽管此处我们不予讨论,但专业的读者也许会在此文的证明及其对 GD 动力学的深入研究中找到乐趣。
但我们希望再次回到一个与此博客相关的重点上去——多大的学习率才叫大呢?简单来说,平衡的现象发生在区间
,这与本文开头提到的传统工具能分析的区间是完全互补的。另外的一个小贴士是, 更大
可以使 GD 不收敛。
专家读者可能会问,等等,上述描述里的
是什么?事实上,这个问题中目标函数是四次的(即四阶多项式),因此其梯度不是全局利普希茨的。此文理论分析部分的优点不仅在于
,而且在于它只需要目标函数是局部利普希茨的。
中的
是指初始化时 Hess
的谱半径(spectral radius)。
总结: [Wang et al (2022)] 表明,当 LR 真正很大的时候,GD 具有收敛到更平坦局部极小值的隐式正则化效果。更大的 LR 可以使这种隐式的偏好更强。
以上就是本文的全部内容。由于篇幅限制和读者的多样性,我们仅仅触及了冰山一角,另外很多严格的细节和相关的工作都未能覆盖。非常欢迎您的提问,评论和引用。希望您喜欢!
[1]. J.H.Wilkinson. Error analysis of floating-point computation. Numer. Math. 1960
[2]. Ernst Hairer, Christian Lubich, and Gerhard Wanner. Geometric Numerical Integration. Springer 2006
[3]. Qianxiao Li, Cheng Tai, and Weinan E. Stochastic modified equations and dynamics of stochastic gradient algorithms i: Mathematical foundations. JMLR 2019
[4]. Lingkai Kao and Molei Tao. Stochasticity of deterministic gradient descent: Large learning rate for multiscale objective function. NeurIPS 2020
[5]. Yuqing Wang, Minshuo Chen, Tuo Zhao, and Molei Tao. Large Learning Rate Tames Homogeneity: Convergence and Balancing Effect. ICLR 2022
[6]. Jeremy Cohen, Simran Kaur, Yuanzhi Li, J. Zico Kolter, and Ameet Talwalkar. Gradient descent on neural networks typically occurs at the edge of stability. ICLR 2021
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读 ,也可以是学术热点剖析 、科研心得 或竞赛经验讲解 等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品 ,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬 ,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱: hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02 )快速投稿,备注:姓名-投稿
△长按添加PaperWeekly小编
🔍
现在,在「知乎」 也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」 订阅我们的专栏吧