近期神奇机器学习应用大赏

文 | 白鹡鸰给小轶讲了个笑话
编 | 小轶发出哈哈哈哈的声音
大家好久不见呀这里是你们的白鹡鸰,不知道各位有没有想我反正我是有想各位了~由于各种大人的原因,最近在卖萌屋存在感不高。虽然还要再等一段时间才能搞事情,但是,在日常的刷文章过程中,白鹡鸰实在是被整乐(yue)了,于是忍不住提前爬上来众乐乐一波。
众所周知,Arxiv本质上是一个预注册研究想法的网站,优点是文章更新又多又快,缺点是文章质量良莠不齐,全得靠人肉分辨。今天的主题就是最近白鹡鸰看到的一些Arxiv上机器学习领域有趣的文章,无论它们的质量如何,那研究内容实在是真的独特到让人忍不住多看一眼。

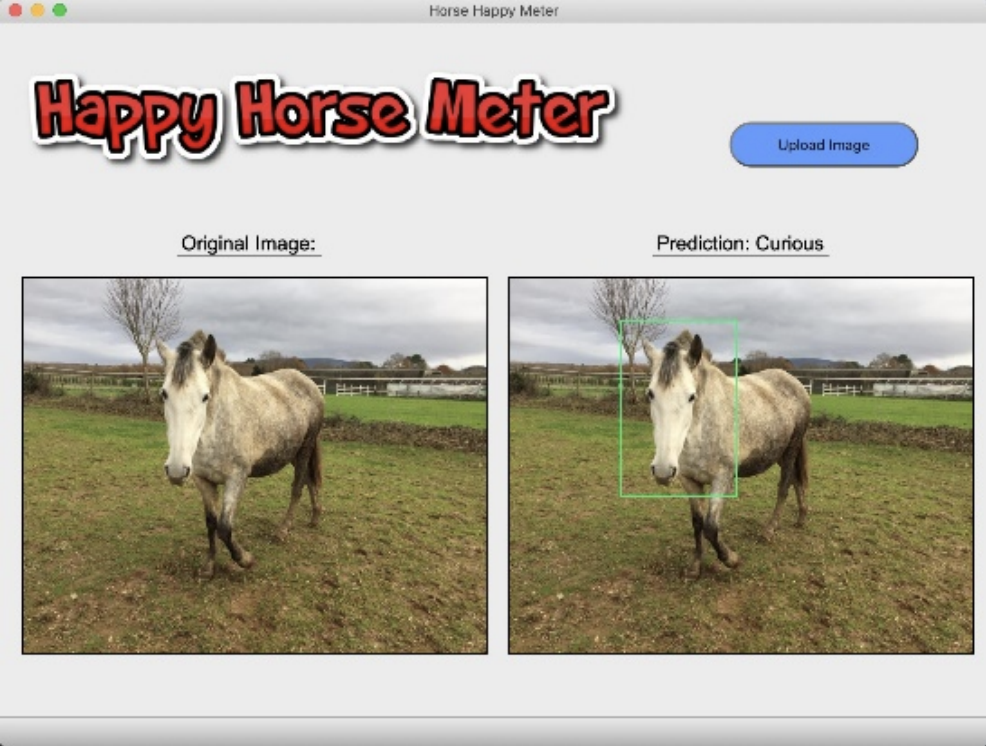
基于卷积神经网络的马匹情感识别
Emotion Recognition in Horses with Convolutional Neural Networks
https://arxiv.org/abs/2105.11953
“您了解马吗?您关心马吗?这位朋友,请允许我用几分钟的时间,向您介绍一下基于卷积神经网络的马的面部表情识别模型。”
两位来自MIT的朋友八成是期末要交AI大作业了,硬生生搞出了这么个玩意儿。没有专业人士支持的标注,400张图片的训练集和80张图片的验证集,就提一个问题——为什么要上CNN呢?迫击炮打蚊子大概就是指这种情况吧。他们还特地做了个交互界面,上传图片,哦,是一匹好奇的马。厉害,厉害。然而,我不关心马,我目前见到的会关心马的情绪的也只有你们俩,好了,下一个。
基于视觉的猪对新鲜事物的偏好行为识别
Vision-based Behavioral Recognition of Novelty Preference in Pigs
https://arxiv.org/abs/2106.12181
人的悲欢并不相通,但脑回路可能产生共鸣。UIUC不同专业的同学们,联合起来!动物学农业学再加上一个计算机的,他们的课题是猪对新事物的认知情况。标了几段视频,然后,LRCN。就报告内容而言,看起来比做马脸识别的那一组专业一点,好歹还知道调一调预训练模型的参数,结果可视化也还可以,如果我是动物行为学课程的老师应该能给个A+。不过,仔细想想这一组的分工,怎么都有点后背发凉。

人工智能,让孩子的数学学习“减负”!
FINNger -- Applying Artificial Intelligence to Ease Math Learning for Children
https://arxiv.org/abs/2105.12281
为什么会变成这样呢……明明数学是快(diao)乐(fa)的,机器学习也是快(diao)乐(fa)的,两件快乐事情重合在一起,得到的,本该是像梦境一般幸(tu)福(ding)的时间……但是,为什么,会变成这样?让幼儿园小朋友学编程难不难我不知道,但好歹教材还是人写的,但这拿机器学习来教数学,还真就不是人干事了,啊!

这篇论文的实质是手势识别,在小朋友做完计算题之后,图像识别检查正确答案。但是,这应用背景真的太迷惑了,我把自己带入了一下小朋友,如果都学会了加减乘除这样抽象的逻辑思维,写几个数字必然不在话下,何必还要用手指来比划呢?而作者宣称的“这是面对欠发达地区的教育手段”也不成立,因为这样的教育仪器做出来,成本绝对高于人工,对操作者的教育水平也有所要求,根本不是欠发达地区负担得起的。这个动机简直透着一股“何不食肉糜”的味道。
基于机器学习和自然语言处理的MBTI人格预测
Extending the Abstraction of Personality Types based on MBTI with Machine Learning and Natural Language Processing
https://arxiv.org/abs/2105.11798
看着文中罗列的机器学习方法,让人回忆起了被综述类大作业支配的恐惧。当你对要综述的学科和相关工作理解不够深刻时,无论一篇文章与这门学科的实质任务有什么关联,都只能胡乱复述一遍好凑字数。然而,本科生水水报告还可以理解,一个国际心理学协会的成员还这样泄洪就离谱了呀。针对特定领域的数据驱动型研究,对数据集的特征没有描述和总结,对任务没有定义和限制。Logic Regression与BERT齐飞,SVM与LSTM共一色。如果是回顾型工作,就该介绍一下过往的相关研究;如果是开创型工作,那好歹也该说明应用的算法的合理性。然而,翻开论文一看,这密密麻麻几十页的没个重点,结论更是迷迷惑惑,横竖看了半天,原来全篇都写着两个字:“灌水”!

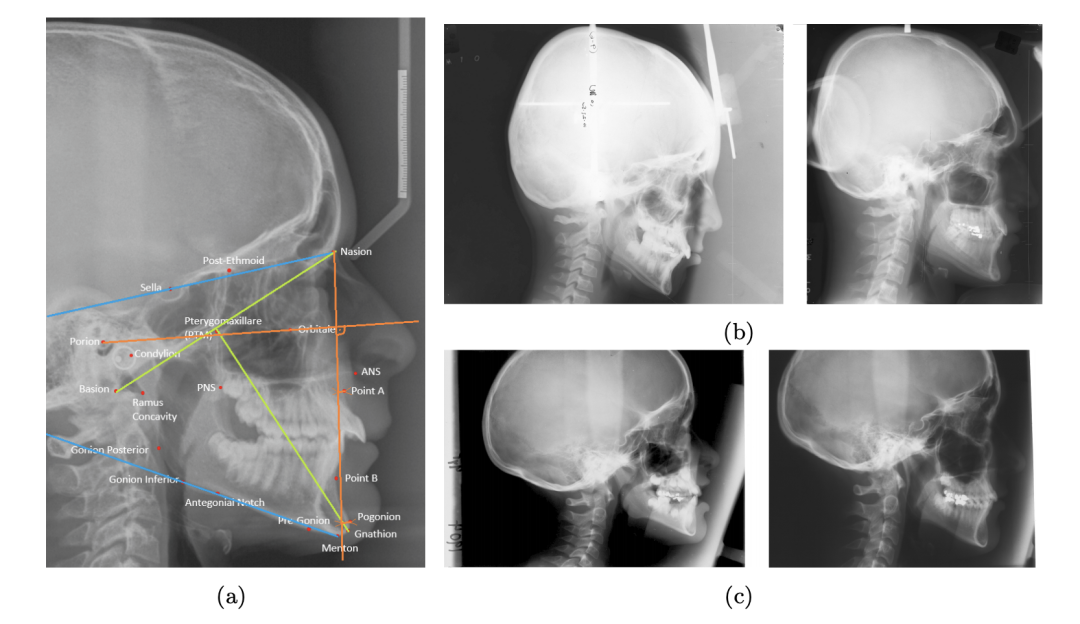
基于机器学习的面部骨骼生长预测
Prediction of the Facial Growth Direction with Machine Learning Methods
https://arxiv.org/pdf/2106.10464
通过人在幼年时期头骨的形状,预测其成年时面相的变化。其实这个工作挺有价值的,比如说对走失儿童、无名尸体的鉴别,或者医美方面都用得上,说不定还能给中国传统文化之算命提供一定的可解释性。但是,这个模型建不建得出来出来要打个问号:如果以头骨的数据作为输入,那这个任务隐含的假设是小时候长相相似的人在成长过程中面部变化的倾向也会相似,而实际上,基因、成长环境、生活习惯等因素都对人的长相有重要的影响。此外,如果真的想为这个任务建一个数据集,那么十年左右的数据采集周期是必不可少的。只能说,祝研究者好运 :)
利用深度学习的足球防守行为效果评估
What Happened Next? Using Deep Learning to Value Defensive Actions in Football Event-Data
https://arxiv.org/abs/2106.01786
欧洲杯期间发篇深度学习+足球防守的文章听起来还是很合理的。今天研究防守中具体行为的效果,明天说不定就能做防守策略,再过一阵子,四舍五入就可以不用请足球教练了,这可真是节约经费的好办法。不过这个任务中,最难的应该是收集球员的数据,毕竟不同的人在应对局势时的选择是不一样的,想准确预测个体行为建议输入端多加几个博弈模型。此外,人在极限情况下的爆发力是难以预计的,为了增加系统的稳定性,建议未来的足球比赛将人换成机器人,从而方便控制数值上限。不过好像这样一来还是不够简便,不如直接在计算机里做几个人物模型跑跑VR足球比赛——体育比赛就是用来挑战人类极限的娱乐活动,正搁这儿玩的起劲呢,非要用精密的计算破坏这种参与感,爪巴。
家居装潢必备神经网络
Style Similarity as Feedback for Product Design
https://arxiv.org/pdf/2105.12256
“我要用神经网络来搞设计。”
“呃……”
“设计的是装修风格。”
“好耶!”
“设计装修风格的本质是识别图片。”
“呃……”
“可以给用户推荐特定风格的家具产品。”
“……”
这大概就是我在看论文的时候的心情波动。老实说,这个想法还挺诱人的,如果只需要输入户型,地理位置,想要的装修风格,计算机就能自动帮你生成装修方案,甚至还找好装修方案里所有商品的购买途径。那么这个世界上应该会少很多类似于门口放人俑,屋顶吊画檐的装修事故。然而,理想是美好的,现实是惨烈的,文章的开头吹上了天,而实际功能只是风格识别+相似推荐,和装修限定版的电商推荐算法没什么本质区别,实在是欺骗感情。

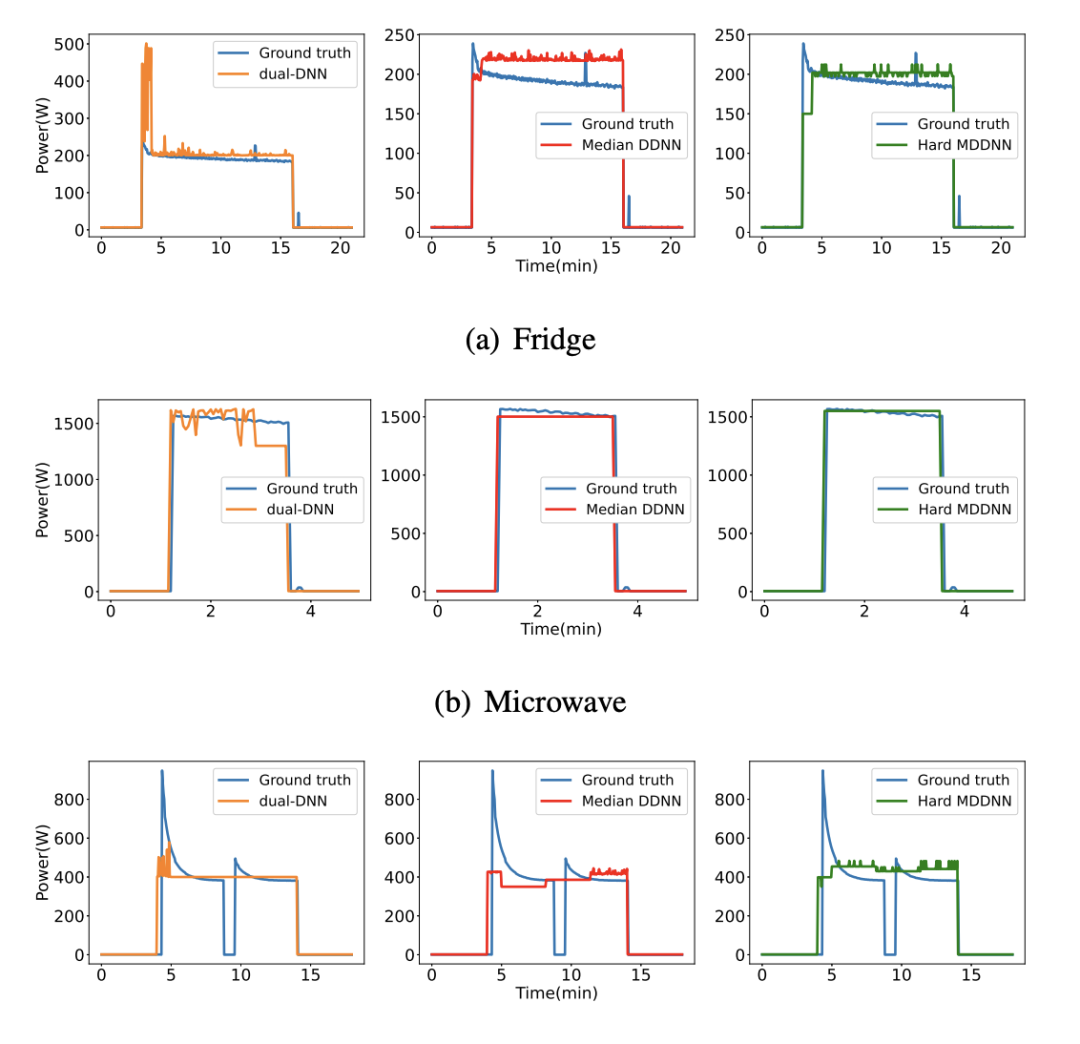
基于深度神经网络的非侵入式电力负载监控
More Behind Your Electricity Bill: a Dual-DNN Approach to Non-Intrusive Load Monitoring
https://arxiv.org/pdf/2106.00297
乍一看,白鹡鸰还以为这篇文章是讲通过电费评估信贷能力的,还暗笑莫不是“不想查电表的研究人员不是好金融大佬”。然而,实际上这是正儿八经用电表波动估计家电使用情况的研究。本质是通过输出波形还原多个输入波的问题基于的原理是不同的电器耗电的波形和频率都有各自独立的特征。虽然波的叠加是线性的,看起来没必要用机器学习。但是在正常情况下,要知道每个家庭有哪些电器和这些电器在不同工作状态下的耗能模式显然不是一件合法的事情(除非你真的干了什么要让人查电表的事情)。而且,一般来说,电力监控也不是针对任何个体的行为,而是为了获得群体的用电习惯,从而更好地分配电力,需要处理的数据不仅量大还具有多样性。因此,用DNN来做电力监控监控还是合理的。
当然,想想这项技术还可以用来检测个人的活动轨迹和生活习惯,还是有点令人毛骨悚然的。
基于视觉的食物识别与食谱评估
A Review of the Vision-based Approaches for Dietary Assessment
https://arxiv.org/pdf/2106.11776
The Food Recognition Benchmark: Using DeepLearning to Recognize Food on Images
https://arxiv.org/abs/2106.14977
不会吧不会吧,连图片识别食物式营养学都配拥有综述和benchmark了?看到这两篇文章的时候,我的认知出现了一些动摇。即使我们身处在一个一道菜只拥有一份配方的世界,能用一模一样的火候,做出份量完全一样的食物,请问火腿和人工肉怎么区分?长得像樱桃的红酒鹅肝又该怎么处理?更别提,最近开始流行用草莓做成的长得像草莓的龙吟草莓了。即使能够解决靠图片估计食物重量的问题,图片这种单一模态的输入也完全无法提供足够用来确认食物品种的信息啊。如果说,这个任务追求的只是粗糙的食物品种识别和单位重量内热量范围估计,好吧,当我没说。但是这一点点的估计失误,几百卡的热量可能就吃进去了,这可令人放心不下啊。

来之不义的人脸数据集
Indian Masked Faces in the Wild Dataset
https://arxiv.org/abs/2106.09670
拿一个新发布的数据集作为压轴,是想说两件事:
-
作为研究者,请注意 道德底线。 -
作为普通人,请注意 保护隐私。
这篇文章的作者认为他们提供了一个具有多样性的面部有遮挡数据集,是在为新冠时期带口罩的面部识别任务提供帮助。而我认为,这群作者为了水文章丢掉了他们底线。他们在未经授权的情况下,从Instagram上下载了他人的自拍图像,而基于这些数据提出的挑战,却未必是一个有价值的任务。事实上,人脸识别技术已经比较成熟,用自己带口罩的样子多刷刷屏幕,手机已经能学会自动解锁。可以说,这项技术的上限基本已经摆在那里了,实装效果只和软硬件配置条件有关。在这种情况下,为了发篇文章侵犯他人隐私,这种行为必须谴责。另一方面,这也说明了社交平台上发自拍确实是一件有风险的事情,这批研究者还只是拿脸来学学模型,万一哪天自拍被用来FakeGAN了,哦呵呵呵呵呵呵。
最后的话
与往期各种nb到闪闪发光的推文不同,今天的故事是围绕Arxiv上更能代表世界的参差——甚至是下限的那批文章展开的。有许许多多的工作,在假设没有说清楚,问题价值没有评估好的情况下,就稀里糊涂地开工了。他们的作者可能是迫于课程压力、或者学位要求,制造了一堆创新性欠缺,实验不充分的文本,还勇气可嘉地投放到了Arxiv上分享。不过,祸兮福兮,他们的文章凑巧被浪行飞翔的白鹡鸰看到了,于是,至少拿来奇文共欣赏,成功吸引到与原本文章质量不符的关注度了(手动滑稽)。
最后,请大家注意:
Arxiv有风险,刷文需谨慎!
萌屋作者:白鹡鸰
白鹡鸰(jí líng)是一种候鸟,天性决定了会横跨很多领域。已在上海交大栖息四年,进入了名为博士的换毛期。目前以图像语义为食,但私下也对自然语言很感兴趣,喜欢在卖萌屋轻松不失严谨的氛围里浪~~形~~飞~~翔~~
知乎ID也是白鹡鸰,欢迎造访。
作品推荐:
 萌屋作者:白鹡鸰
萌屋作者:白鹡鸰寻求报道、约稿、文案投放:
添加微信xixiaoyao-1,备注“商务合作”
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
![]()
 后台回复关键词【
后台回复关键词【




