简单复读机LR如何成为推荐系统精排之锋?

文 | 水哥
源 | 知乎
saying
1. 众所周知, 人类(划掉)推荐的本质是复读机
2. 精排之锋,粗排之柔,召回之厚
3. 在推荐里谈“过拟合”很容易给我们造成心理上的松懈,导致我们忽略环境,氛围等多种因素的作用。我们可以说一万遍有过拟合,但是不采取行动,就没有任何作用
这一讲开始,我们将介绍具体的模型。前面我们说过模型有三种:精排,粗排和召回。我们也大致提过,精排的作用是完成给定的拟合任务,没有任何其他杂念,就像一把锋利的刃,纯粹探究模型的上界。粗排是召回和精排之间的承接环节,它更需要的是平衡。而召回需要体现生态的方方面面,它包含了一个研究者对整个业务体系的厚重的思考。
我们分三个部分讲解模型,首当其冲的就是精排模型。在多种多样的模型中,最简单的是逻辑回归。在其他领域逻辑回归可能是一个大家课上都学,但是没什么人用的模型。但是在推荐领域,它做主流的时间可能比很多人想象的要长很多。我知道的一些现在很知名的公司,摆脱LR可能都没几年。从这一讲中我们能看出,逻辑回归虽然简单,但是它已经能贴合推荐这件事情的本质了。
下面进入正题。我们所能想到最简单的,最常见的建模是一个线性模型,其实就是 。在很多问题中直接使 接近ground truth 就可以完成一个最简单的拟合。但是推荐模型预估的问题,一般是点击率之类的,具体操作上是每次展示是否发生点击。点击与否是0/1的。这就要求我们模型的输出应该也是0/1的,或者至少是在 之间(这个时候就表明一个概率)。因此在外面会加上一个激活函数sigmoid(这个函数的输出是限定在0-1之间的),最终得到
这就是逻辑回归最终的形式。
但是上面这个过程,存不存在疑问呢?
为什么是sigmoid?
上面的激活函数使用了sigmoid,我们说是因为他的值域在0-1之间。但是如果仔细想想这个理由还有点牵强:是不是只要输出在0-1之间,什么激活函数都可以?比如说我可不可以先用Tanh把输出范围约束到 之间,再线性变换到0-1之间呢?为什么没有人这样做?可能有别的原因。
这个问题其实我翻找了很多的资料,大多数的回答都不是很令人信服,下面这个解释算是我觉得最让我接受的一个,是我在Quora上面找到一个很好的回答[1],这里转述一下:
这个形式,本身是无界的。我们不能让它去拟合一个 之间的目标。假如说原来点击的概率是 ,我们就要构造一个相关形式,让它的值域是 的,才能进行学习。可以首先做一个辅助函数 ,这样会把输出的范围放大到 之间。接下来再对这个式子取对数,就可以把输出范围变成 的,符合我们的要求。即令:
把这个式子解开,就可以得到上面的逻辑回归形式了。
工业界的应用方式
LR在工业界应用时,是有点特殊的。这个特殊的点在特征 上。这时候要注意一个时代背景,即特征的处理是比较原始的,怎么简单怎么来。推荐这个阶段的特征,不像其他领域如CV,NLP是一段连续的浮点数向量或者张量,也不是后来的embedding look-up table,而是无数的“one-hot”,怎么理解呢?比如我有1w个item,分别编号1-10000,那么在item id这里,就有1w个特征,只是每一个item只能是其中的一个取值为1,其他的取值都为0(这个就是one-hot). 相应地,也就有1w个不同的 。每一种特征,我们称之为一个slot,仅在这一种slot内是one-hot的。在我们计算 的时候, 是binary的,而 是浮点数,这个结果其实操作的时候,就是把用户所有不为0的 对应的 加起来即可。我们用下图来表示:
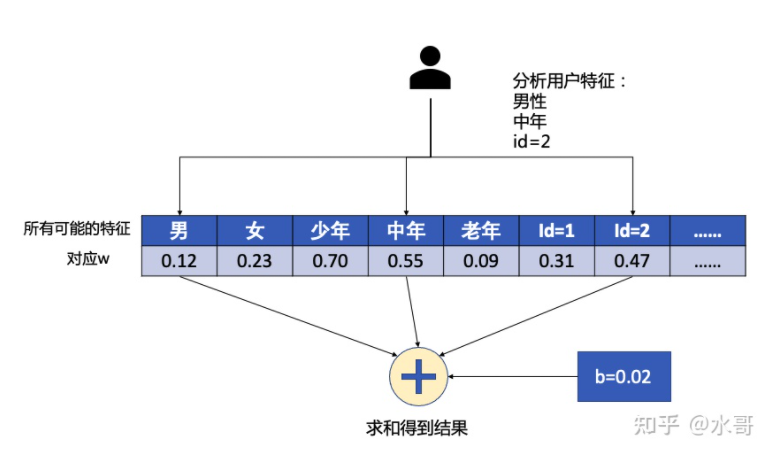
在这个例子中,有三种特征,性别,年龄段,和user ID。注意到这里 的表格需要存储所有可能的特征取值。对于当前的用户我们就分析,他的性别,年龄段,ID分别是什么。由于 是0/1的,直接取出对应的 ,并且和 相加。这里只画了用户侧的部分,item侧也是同样的道理。
但是要注意的是,特征 在概念上是one-hot的,实际上不需要真正做出来一段向量然后用一个矩阵映射什么的。因为很多时候这个one-hot里面是会有“洞”。即有一些ID可能不出现,这时候再做一个满的矩阵太浪费了。实际中都是稀疏保存的,就是哪个有值存哪个。后面的embedding look-up table也是这么做的。
推荐的本质是复读机
按照上面这个例子,我们设想一个极限情形:如果只有user ID和item ID两种特征,会出现什么情况?
在一开始没有样本来的时候,他们的 都没有值(简单起见,假设是初始化为0),如果user 1和item1这个组合发生了点击,那么回传梯度的时候,这两个对应的 会以相同的幅度变大一些。接下来,当user2面对item1,由于item1的 是有值的,输出的排序就比user2面对一个没见过的item2要大。
所以这个过程其实不是很合理:我们对user2完全没有知识,为什么就输出了一个明显倾向于item1的结果呢?原因是因为user1给出了一个正反馈。我们的模型只能从前面的结果里面去学习,它好像没有什么自己的主见,只会人云亦云罢了。这个例子推到更极限的情况呢?如果只有item ID特征,那这个模型就完全变成了一个简单的计数统计,谁被点的次数多,谁的排序就永远靠前。在这里面没有任何“灵性”,我不用模型也能做到这一点。这就是我们这一讲要强调的一个观点:
推荐的本质是复读机
第一个马上就能想到的问题是,为什么推荐是复读机,而CV,NLP不是?
因为推荐存在不确定性,必须要试错才能拿到label,而且很难归因。当我们面对一组样本,某个用户和某个item,我们是否能说的上这个点击会不会发生?我感觉是很难的。所以只有试了试才知道。这个试错的机制还造就了之前提到过的探索与利用以及冷启动的问题。另一方面,当点击发生的时候,我们也很难说,是因为这个用户就是容易点击,还是说这个item就是好,还是某种巧合。这就造成了上面例子中的问题,也许user1点击item1只是随手一点,模型也会给item1一部分权重(认为它好)。
但是CV,NLP不一样的是,它们的label是一个固定的东西,一幅图片里面是猫就是猫,是狗就是狗,拟合的目标很清晰,且不存在偶然性。
那我们接着往下想,为什么推荐必须要试错才能拿到label?我们可以做到像CV那样,给出一个确定性的判断吗?我的结论是,现阶段不可行,未来说不定可以。在推荐这件事中,有很多的信息我们是拿不到的,比如你在刷视频的时候,你是在公交上还是在教室里?你这次拿起手机之前是和同学聊完天,还是刚刚睡了一觉醒来?你是一个怎样的人?给你推送教育知识会不会让你想起被考试支配的恐惧?这些都是变量,都会影响对当前这个item的判断。然而这些特征暂时都是不可获取的。在著名的《影响力》[2]里面就提到一个例子:当商家在网站上卖沙发的时候,如果背景是云朵,顾客就会更关注舒适度,如果背景是硬币,顾客就会更关注性价比。假如有一天,用户的一切信息,item的一切信息我们都拿到了,那个时候足够好的泛化可能会出现。
所以我个人不太喜欢同学们经常在做推荐的时候频繁提“过拟合”,这个概念没错,但是如果我们把全部注意力都转移到这里,很容易忽视很多值得关注的细节。在我看来,上面这些信息都没有,模型完全还处于远远欠拟合的状态。如果我们对各种特征,对于用户的刻画都全知全能了,那么也许就不需要面临复读机引发的问题了(这里扯得有点远,我们到了产品篇或者运营篇再详细讲讲吧)。
第二个问题是,真实情况真的这么糟吗?
其实也没那么糟,在LR这个模型里面,增加泛化的要点是增加一些能泛化的特征。还是像上面图中的例子,当我们有年龄性别这样的输入之后,一部分归因可以归到年龄性别上,那么下次一个新的用户来的时候,我们就可以根据他的年龄性别给出一些先验判断。这本身也是一种复读,但是更科学了。以此类推我们实际中会加很多能描述用户或者item泛化属性的特征来缓解这个问题。
“推荐本质是复读机”这个理论不是完全正确的,之所以这么说,是希望同学能够以一个更加自如的姿态来看待这个领域。一开始我们往往敬畏之心会过度旺盛,加上圈子里面天天《重磅》《大突破》,渲染的好像有多么高深一样,我们会觉得这个领域不知道从何下手。不如换一个角度,你首先要相信,现代科学的发展没有那么突飞猛进,很多情况都是增量式的改进,你先从简单的视角来看待,慢慢再深入也许上手更快。再说了,复读也不是坏事,只要复读的足够高级,你也看不出我在复读嘛。
强解释性
LR这个模型解释性是非常强的。我们还是举上面图中的那个例子,我们有四种特征,user ID,item ID,年龄,性别。假如在分布均匀的茫茫负样本中,只有三个正样本,分别是:
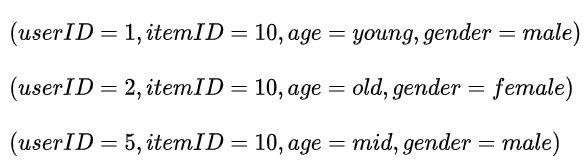
通过这些样本,模型会有怎样的趋势,我们能看出怎样的结论?通过对模型的分析,我们可以判断,itemID=10这里,对应的w收到三次正向的梯度,gender=male两次,其他都是一次。那么从模型的角度看,itemID=10就是一个更重要的因素,也就是说,模型认为10号item就是好。如果是我们人为分析的话,我也会这么觉得。模型给出的判断符合人的认知。我们完全可以拿出一个模型,看看里面的 分布是怎样的,然后说, 幅度明显大的特征,就比小权重的特征更重要。这一点在大多数实践中是成立的。因此事实上,LR也可以作为特征重要性分析的一种工具。
我们本讲中的LR特征种类少,特征的取值也少。但在实际应用中,特征的数量是非常非常多的。比如我又上亿用户的时候,单单user ID这一个特征就有上亿的取值。由于特征的每一种取值都要独占一个 ,那么也就存在一个对应的 。即使我的机器很多,要做完一次预估都需要穷举所有非0的 也是非常非常费劲的。尤其是我可能会得到很多 取值是0.0001,0.000001这样的,你说不加吧,结果可能又不对,加上吧,零零碎碎的也太烦人了。怎么样既能做到结果是准确的,又能很省力的完成呢?这就是LR主要面临的问题,请看下期——
下期预告
精排之锋(2):工业LR的稀疏要求
往期回顾
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
![]()
[1]. https://www.quora.com/Logistic-Regression-Why-sigmoid-function
[2]. 《影响力》这是社会心理学的一本很著名的书,推荐大家读一读
 后台回复关键词【
后台回复关键词【




