超越Transformer,清华、字节大幅刷新并行文本生成SoTA性能|ICML 2022
![]()
新智元报道

新智元报道
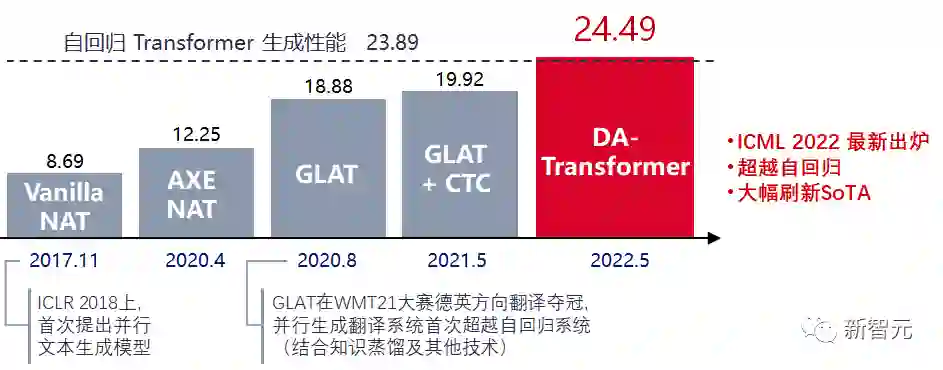
【新智元导读】清华&字节联合提出的DA-Transformer摆脱了传统并行模型依赖知识蒸馏的问题,在翻译任务中大幅超越了之前所有并行生成模型,最高提升 4.57 BLEU。同时也首次达到、甚至超越了自回归 Transformer 的性能,在最高提升 0.6 BLEU 的同时,能够降低7倍的解码延迟。|还在纠结会不会错过元宇宙和web3浪潮?清华大学科学史系副教授胡翌霖,这次给你讲个透!
DA-Transformer不再依赖知识蒸馏,彻底摆脱自回归模型参与训练;
大幅超越之前所有的并行生成模型,最高涨点 4.57 BLEU;
首次在未使用知识蒸馏的情况下,接近并超越自回归 Transformer 性能,真正实现又快又好的文本生成。(最高+0.60 BLEU,7~14倍解码加速)

The CoAI group, Tsinghua University, China
Department of Computer Science and Technology, Tsinghua University, China.
ByteDance AI Lab
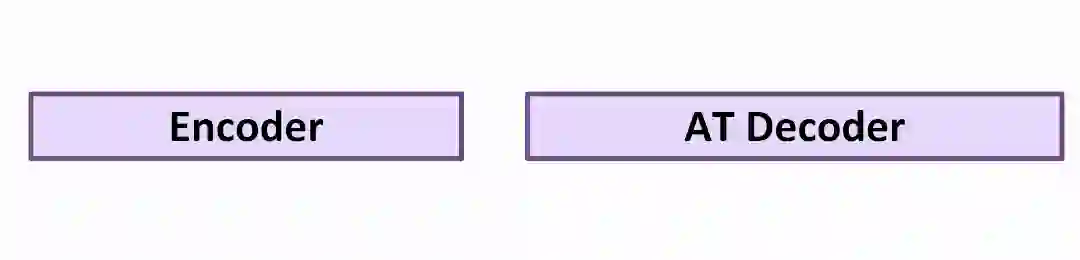
背景:自回归和非自回归文本生成
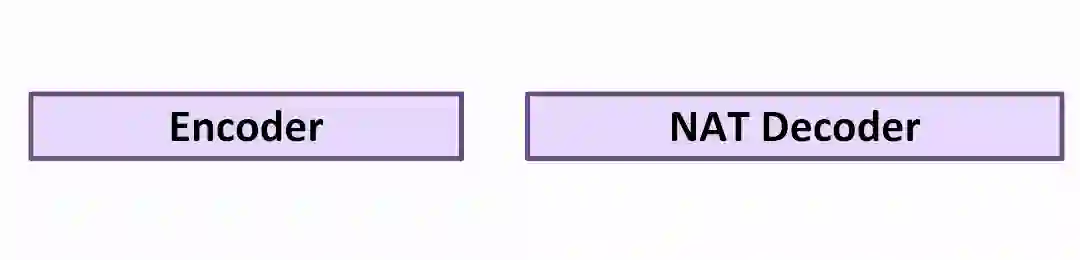
并行生成中的一对多难题
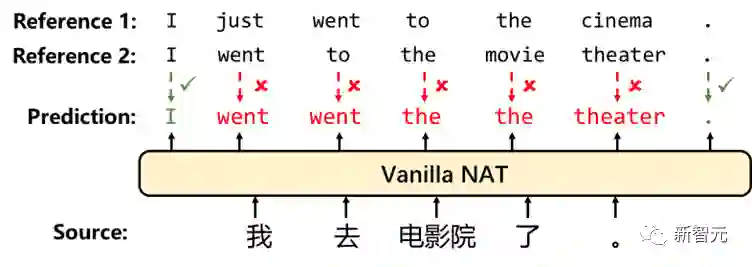
在训练时,多个不同的参考文本会在某些位置提供不一致的词作为训练标签。由于 NAT 会独立学习预测每一个位置上的词,不一致的标签会损害模型的准确率,增加训练难度。
在解码时,NAT 缺少合适的解码手段去恢复正确的词间依赖。即使模型在训练时能够正确学得每个位置上的标签分布,NAT也无法得知每个位置上的预测词分别来自哪一个参考文本。
DA-Transformer:在有向无环图上的并行生成模型
在训练时,模型将参考文本分配到不同的路径上,避免在同一位置提供冲突的标签,提高了模型预测的准确率。
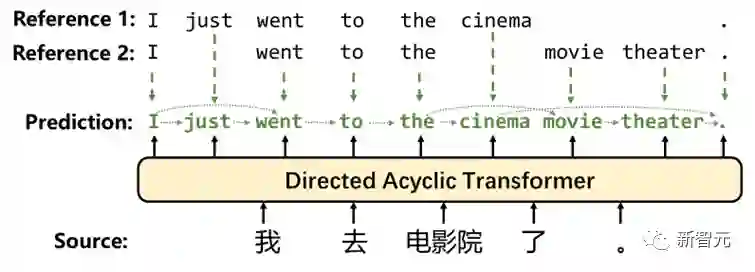
在解码时,模型可以通过有向边的转移,采样或搜索出合理的输出,保证了输出中词语搭配的正确性。
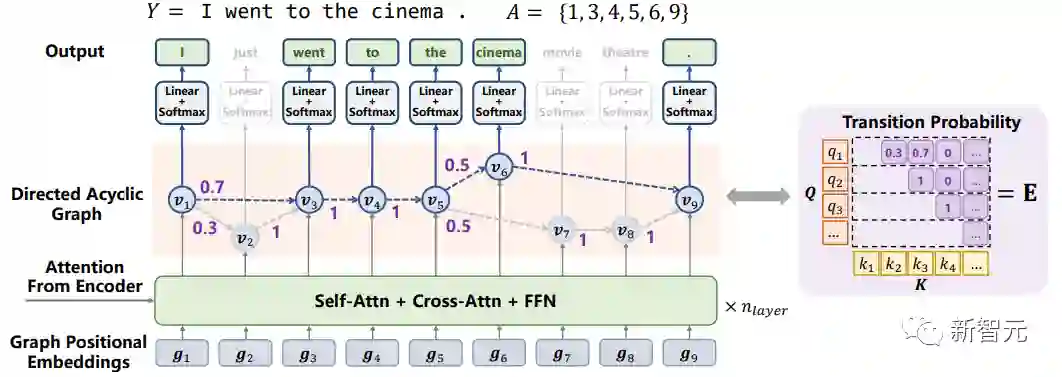
训练方法简单通用:无需多个参考文本
对于单个样本,训练时会将提供的参考文本稀疏地分配到图上结点,每次只更新图的一部分;
对于整个数据集,有向无环图上的不同输出可以通过综合多个训练样本学习得到。
解码方法多样:在有向无环图上搜索路径
实验结果:又快又好的并行生成
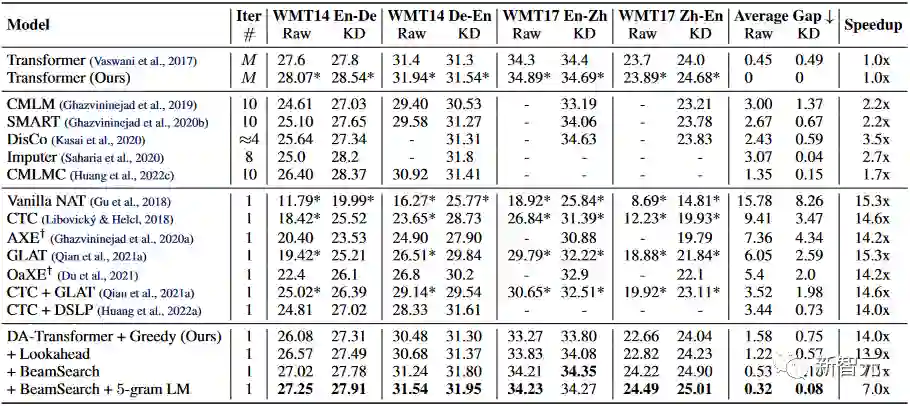
与自回归模型相比,DA-Transformer无需知识蒸馏,在四个翻译方向上均获得了接近自回归模型的性能,同时提供了7~14倍的解码加速。特别地,在WMT17中英翻译数据集上,首次展示了并行生成模型能超越自回归模型性能,提升近0.6 BLEU;
与单次预测的并行生成模型相比,DA-Transformer大幅刷新了之前的SoTA,不仅提升了生成质量(Raw Data上平均提升近3 BLEU,最高的翻译方向上提升4.57 BLEU),同时维持了较高的加速比;
与多次预测的并行生成模型相比,DA-Transformer 从加速比和生成质量上都大幅超越已有模型。
生成例子:有向无环图上的多样输出

总结
DA-Transformer 显著提升了词表上预测的准确率;
通过在图上采样,DA-Transformer 能够生成多样且高质量的结果,与自回归生成模型相当;
通过调整图的大小和解码方式,DA-Transformer 能够提供多种不同的生成质量和解码速度的权衡。




