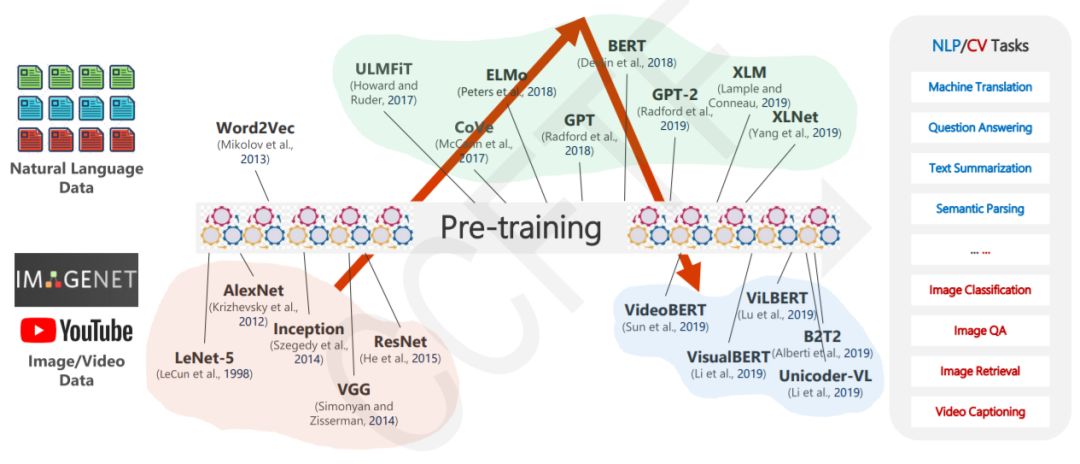
最新必读【预训练语言模型(BERT/XLNet等)】论文,Google/微软/华为ICLR2020提交论文
【导读】近年来,预训练模型(例如ELMo、GPT、BERT和XLNet等)的快速发展大幅提升了诸多NLP任务的整体水平,同时也使得很多应用场景进入到实际落地阶段。专知小编整理最近关于预训练语言模型研究的进展,包括ICLR2020提交论文,有Google、微软、华为等。
请关注专知公众号(点击上方蓝色专知关注)
后台回复“PLM” 就可以获取最新预训练语言模型论文下载链接~
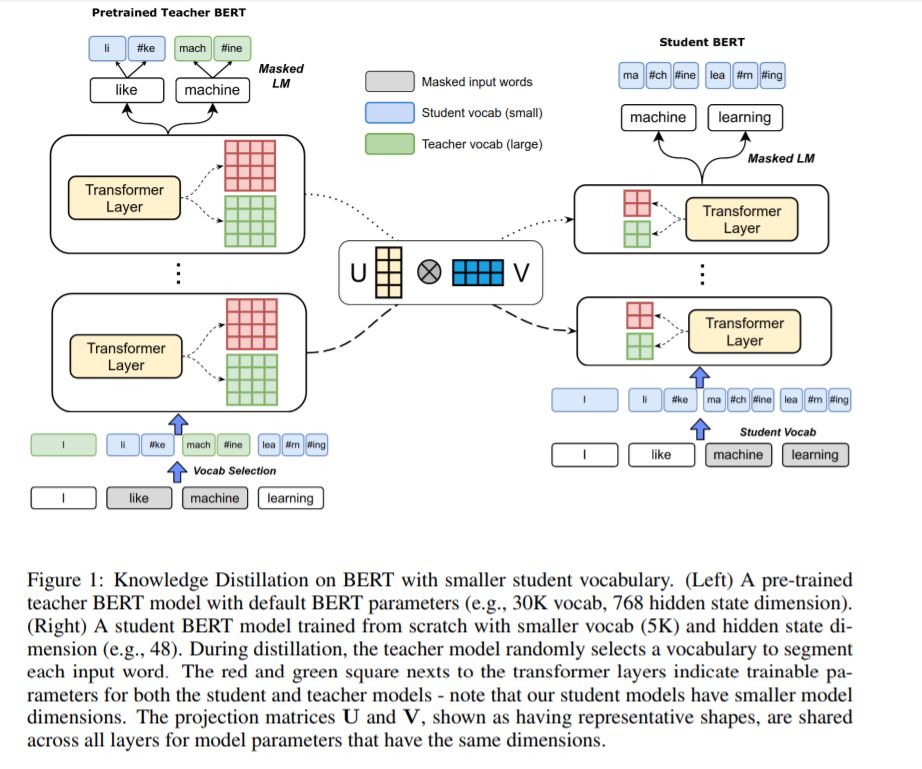
1、Extreme Language Model Compression with Optimal Subwords and Shared Projections(极限语言模型压缩,可获得7MB模型)
ICLR ’20提交论文 ,Google AI
作者:Sanqiang Zhao, Raghav Gupta, Yang Song, Denny Zhou
摘要:预先训练的深度神经网络语言模型,如ELMo、GPT、BERT和XLNet,最近在各种语言理解任务上取得了最先进的性能。然而,它们的大小使得它们在许多场景中的应用不合实际,尤其是在移动设备和边缘设备上。特别是,由于输入词汇量和嵌入维数较大,输入词嵌入矩阵占模型内存占用的很大比例。知识蒸馏技术在压缩大型神经网络模型方面取得了成功,但在生成词汇量与原始教师模型不同的学生模型方面效果不明显。本文介绍了一种新的知识蒸馏技术,用于训练词汇量显著减少、嵌入和隐藏状态维数较低的学生模型。具体地说,我们采用了一种双训练机制,同时训练教师和学生模型,从而为学生词汇获得最佳的单词嵌入。我们将此方法与学习共享投影矩阵相结合,共享投影矩阵将分层知识从教师模型转移到学生模型。我们的方法能够将BERT_BASE模型压缩60倍以上,只是稍微降低下游任务指标,就可以得到内存不足7MB的语言模型。实验结果还表明,与其他先进的压缩技术相比,该方法具有更高的压缩效率和精度。
网址:
https://www.zhuanzhi.ai/paper/04680670e59b98f5305f30c7b57963e2
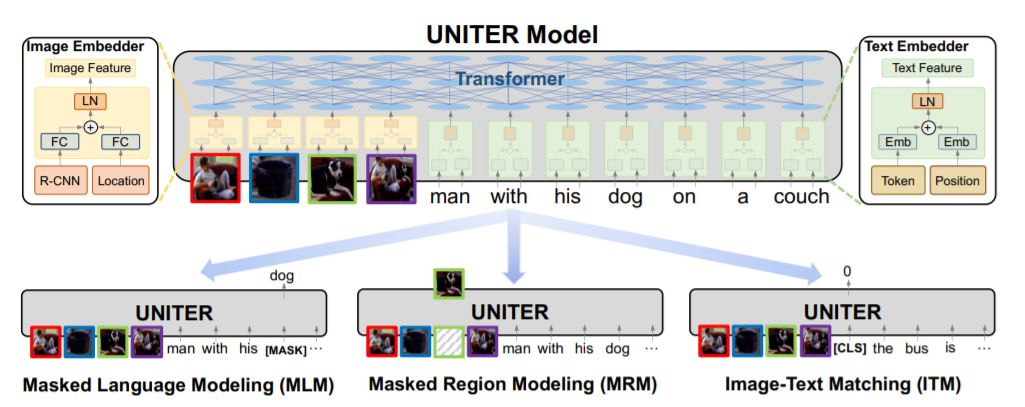
2、UNITER: Learning UNiversal Image-TExt Representations(通用图像文本语言表示)
ICLR ’20提交论文 ,微软
作者:Yen-Chun Chen,Linjie Li,Licheng Yu,Ahmed El Kholy,Faisal Ahmed,Zhe Gan,Yu Cheng,Jingjing Liu
摘要:联合图像-文本嵌入是大多数视觉-语言(V+L)任务的基础,其中多模态输入被联合处理以实现视觉和文本理解。在本文中,我们介绍了一种通用的图像-文本表示方法UNITER,它是通过对四个图像-文本数据集(COCO、可视基因组、概念说明和SBU说明)进行大规模的预训练而获得的,可以通过联合多模态嵌入为异构下游V+L任务提供支持。我们设计了三个训练前的任务:掩蔽语言建模(MLM)、图像-文本匹配(ITM)和掩蔽区域建模(MRM,有三个变体)。与将联合随机掩蔽应用于两种模式的多模态训练前同步工作不同,我们在训练前任务(即,蒙面语言/区域建模的条件是充分观察图像/文本)。综合分析表明,条件掩蔽比非条件掩蔽具有更好的性能。我们也进行了一个彻底的消融研究,以找到一个最佳的设置组合的训练前的任务。大量的实验表明,UNITER通过6个V+L任务(超过9个数据集)实现了新的技术水平,包括可视化问题回答、图像-文本检索、引用表达式理解、视觉常识推理、视觉蕴涵和NLVR2。
网址:
https://www.zhuanzhi.ai/paper/985d49f20391b09747e78b8a03c0ccca
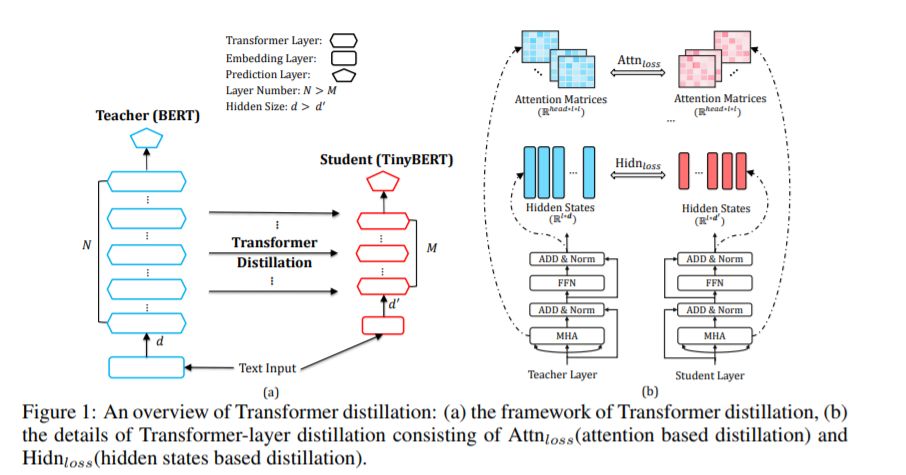
3、TinyBERT: Distilling BERT for Natural Language Understanding(微型化BERT自然语言理解)
ICLR ’20提交论文 ,华为诺亚方舟
作者:Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, Qun Liu
摘要:语言模型预处理,如BERT,显著提高了许多自然语言处理任务的性能。然而,预训练语言模型通常计算开销大,内存占用大,因此很难在一些资源受限的设备上有效地执行它们。为了在保证模型精度的同时加快推理速度,减小模型尺寸,我们首先提出了一种新的transformer 精馏方法,它是一种专门设计的基于transformer 模型的知识精馏(KD)方法。通过使用这种新的KD方法,一个大型老师BERT所编码的大量知识可以很好地转移到一个小型学生TinyBERT身上。此外,我们还为TinyBERT引入了一个新的两阶段学习框架,该框架在训练前和特定于任务的学习阶段都执行transformer 蒸馏。这个框架确保TinyBERT能够捕获BERT老师的一般领域和特定于任务的知识。TinyBERT在经验上是有效的,在GLUE数据集上取得了与BERT相当的结果,同时比BERT小7.5倍,推理速度快9.4倍。TinyBERT也明显优于最先进的基线,即使只有28%的参数和31%的基线推断时间。
网址:
https://www.zhuanzhi.ai/paper/4e8284902660b49194b8f89fd2230ea3
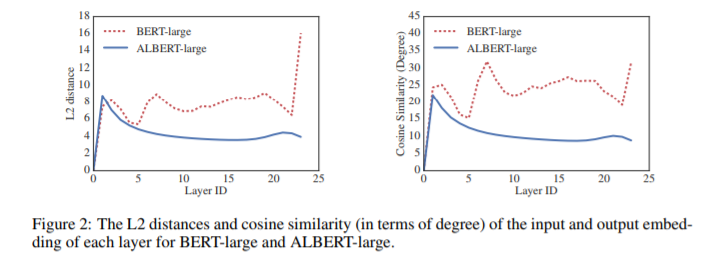
4、ALBERT: A Lite BERT for Self-supervised Learning of Language Representations(语言表示自监督学习Lite BERT)
ICLR ’20提交论文 ,Google
作者:Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut
摘要:在训练自然语言表示时,增加模型大小通常会提高下游任务的性能。然而,在某种程度上,由于GPU/TPU内存的限制、更长的训练时间和意想不到的模型退化,模型的进一步增加变得更加困难。为了解决这些问题,我们提出了两种参数减少技术来降低内存消耗,提高BERT的训练速度。综合的经验证据表明,我们提出的方法导致模型规模比原来的BERT更好。我们还使用了一个自我监督的损失,重点是建立句子间一致性的模型,并表明它始终有助于下游任务的多句输入。因此,我们的最佳模型在GLUE、RACE和SQuAD基准上取得了最新的最好的结果,而与BERT-large相比,参数更少。
网址:
https://www.zhuanzhi.ai/paper/de1be2ecdc499e72ab28d79a37f679e4
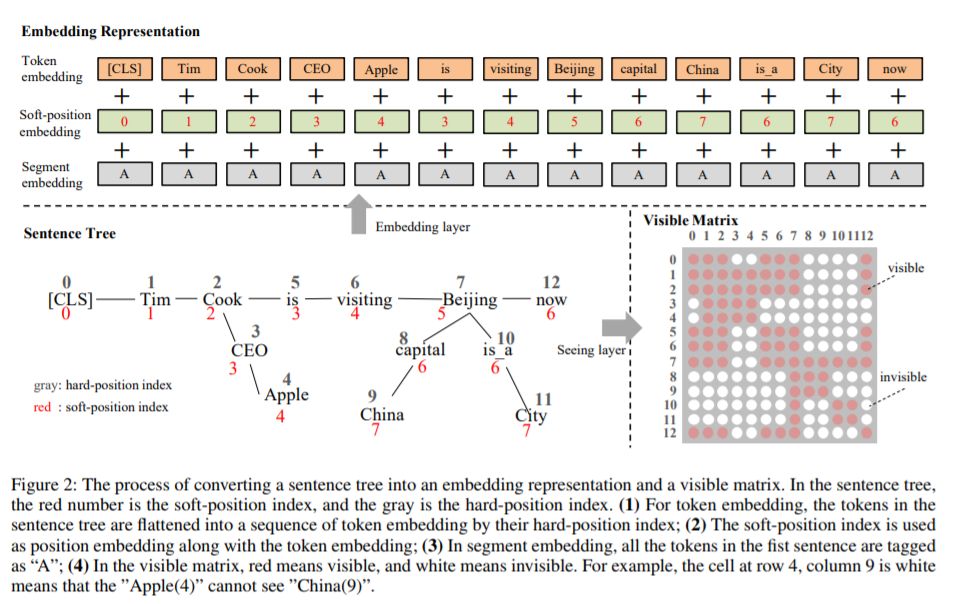
5、K-BERT: Enabling Language Representation with Knowledge Graph(知识图谱语言表示)
AAAI ’20提交论文 ,北京大学,腾讯
作者:Weijie Liu, Peng Zhou, Zhe Zhao, Zhiruo Wang, Qi Ju, Haotang Deng, Ping Wang
摘要:预训练的语言表示模型,如BERT,从大型语料库中捕获一般的语言表示,但是缺乏领域特定的知识。在阅读领域文本时,专家用相关知识进行推理。为了使机器能够实现这一功能,我们提出了一种基于知识图谱支持知识的语言表示模型(K-BERT),其中将三元组作为领域知识注入到句子中。然而,过多的知识掺入可能会使句子偏离正确的意思,这就是所谓的知识噪声(KN)问题。为了克服KN, K-BERT引入了软位置和可见矩阵来限制知识的影响。由于K-BERT能够从预训练的BERT中加载模型参数,因此不需要进行自训练就可以通过KG轻松地将领域知识注入到模型中。我们的实验显示了12项NLP任务的良好结果。特别是在特定领域的任务(包括金融、法律和医学)中,K-BERT的表现明显优于BERT,这说明K-BERT是解决需要专家参与的知识驱动问题的一个很好的选择。
网址:
https://www.zhuanzhi.ai/paper/ce9df4d0aa699cc4f0eed4d83daf23e1
更多最新论文:
6. 语言模型作为知识库?Language Models as Knowledge Bases? Fabio Petroni, Tim Rocktäschel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, Alexander H. Miller, Sebastian Riedel. EMNLP2019.
论文:
https://arxiv.org/pdf/1909.01066.pdf代码:
https://github.com/facebookresearch/LAMA
7. BERT 语言知识探究,Investigating BERT's Knowledge of Language: Five Analysis Methods with NPIs. Alex Warstadt, Yu Cao, Ioana Grosu, Wei Peng, Hagen Blix, Yining Nie, Anna Alsop, Shikha Bordia, Haokun Liu, Alicia Parrish, Sheng-Fu Wang, Jason Phang, Anhad Mohananey, Phu Mon Htut, Paloma Jeretič, Samuel R. Bowman. EMNLP2019.
论文:
https://arxiv.org/pdf/1909.02597.pdf代码:
https://github.com/alexwarstadt/data_generation
8. VideoBERT: A Joint Model for Video and Language Representation Learning. Chen Sun, Austin Myers, Carl Vondrick, Kevin Murphy, Cordelia Schmid. ICCV2019.
论文:
https://arxiv.org/pdf/1904.01766.pdf
其他请移步阅读:
【清华大学NLP】预训练语言模型(PLM)必读论文清单,附论文PDF、源码和模型链接
-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!560+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程



