
最近 BERT 这一类基于预训练的语言理解模型十分流行,也有很多工作从改进预训练任务或者利用知识蒸馏的方法优化模型的训练,但是少有改进模型结构的工作。依图研发团队从模型结构本身的冗余出发,提出了一种基于跨度的动态卷积操作,并基于此提出了 ConvBERT 模型。
这一模型在节省了训练时间和参数的情况下,在衡量模型语言理解能力的 GLUE benchmark 上相较于之前的 State-of-the-art 方法,如 BERT 和 ELECTRA,都取得了显著的性能提升。其中 ConvBERT-base 模型利用比 ELECTRA-base 1/4 的训练时间达到了 0.7 个点的平均 GLUE score 的提升。
之前 BERT 这类模型主要通过引入自注意力机制来达到高性能,但是依图团队观察到 BERT 模型中的 attention map 有着如下图的分布(注:attention map 可以理解成词与词之间的关系),这表明了大多注意力主要集中在对角线,即主要学习到的是局部的注意力。这就意味着其中存在着冗余,也就是说很多 attention map 中远距离关系值是没有必要计算的。
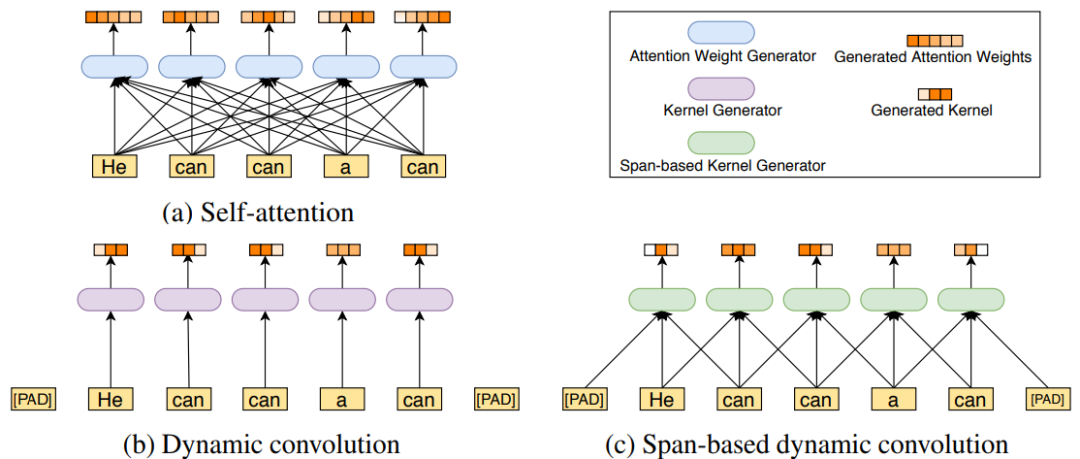
于是依图团队考虑用局部操作,如卷积来代替一部分自注意力机制,从而在减少冗余的同时达到减少计算量和参数量的效果。
另一方面,考虑到传统的卷积采用固定的卷积核,不利于处理语言这种关系复杂的数据,所以依图提出了一种新的基于跨度的卷积,如下图所示。原始的自注意力机制是通过计算每一对词与词之间的关系得到一个全局的 attention map。
此前有文章提出过动态卷积,但其卷积的卷积核并不固定,由当前位置的词语所代表的特征通过一个小网络生成卷积核。这样的问题就是在不同语境下,同样的词只能产生同样的卷积核。但是同样的词在不同语境中可以有截然不同的意思,所以这会大大限制网络的表达能力。
基于这一观察,依图提出了基于跨度的动态卷积,通过接收当前词和前后的一些词作为输入,来产生卷积核进行动态卷积,这在减少了自注意力机制冗余的同时,也很好地考虑到了语境和对应卷积核的多样性。
