那个在国际翻译大赛上夺冠的模型,字节刚刚给开源了(附夺冠代码)
机器之心发布
作者:钱线、封江涛、周浩
Transformer 等文本生成主流算法的逐词生成对适合并行计算的 GPU 并不友好,会导致 GPU 利用率低下。并行生成有助于解决这一问题。前不久,字节跳动火山翻译团队的并行生成翻译系统 GLAT 拿下了 WMT2021 De-En/En-De 的双料冠军。为了帮助大家跟进这一成果,火山翻译开源了一个名为 ParaGen 的 Pytorch 深度学习框架,其中包含 GLAT 模型复现和 WMT21 的代码。

代码地址:https://github.com/bytedance/ParaGen
文本生成是自然语言处理的一个重要研究方向,具有广泛的应用场景。比如文本摘要、机器翻译、文案生成等等。不同于一般的分类、标注等任务,文本生成不仅要考虑每个词的重要性,提高单词的预测准确性,也要兼顾词语之间的搭配,保持整个文本的流畅度。因此一般的做法是逐词生成,每产生一个词都会考虑和已有词的关系。
经过以上步骤进行文本生成的这类模型称为自回归模型,比如目前主流的生成算法 Transformer。该模型首先对原始文本进行编码,比如机器翻译中的待翻译文本或者是文本摘要中的原文。然后再从左到右逐词解码产生翻译好的文本或是摘要。基于该算法的开源软件有 tensor2tensor、fairseq 等。然而逐词生成对适合并行计算的 GPU 来说并不友好,导致 GPU 利用率低下,句子生成速度慢。因此近年来有很多研究探索如何并行生成文本,降低响应延时。
此前,字节跳动人工智能实验室 (AI-Lab) 的火山翻译团队研发了并行生成的翻译系统 Glancing Transformer (GLAT)(参见《ACL 2021 | 字节跳动 Glancing Transformer:惊鸿一瞥的并行生成模型》),并且使用它一举拿下了 WMT2021 De-En/En-De 的双料冠军 (参见《并行生成奇点临近!字节跳动 GLAT 斩获 WMT2021 大语种德英自动评估第一》),彰显出了并行生成的强大潜力。ParaGen 正是在这个背景下应运而生。团队的研究者们发现,对于并行生成来说,单单是模型的改进已经不能满足研究的需求,训练方法、解码算法的改进也变得日益重要。而 ParaGen 的开发正是为了解放并行生成研究的生产力。
在 ParaGen 中,火山翻译开源了 GLAT 模型复现和 WMT21 的代码,帮助大家更好地去跟进并行生成的研究结果。在未来,火山翻译也将开源更多并行生成相关的技术,推动并行生成技术的进一步发展,帮助并行生成这一技术逐渐走向更多的生产应用。与此同时,除了并行生成以外,ParaGen 也支持了多元化的自然语言处理任务,包括自回归翻译、多语言翻译、预训练模型、生成任务、抽取任务、分类任务等,并提供从零复现的代码,帮助刚接触自然语言处理研究的同学更快进入到研究的状态。
ParaGen 让开发更灵活、更自由、更简便
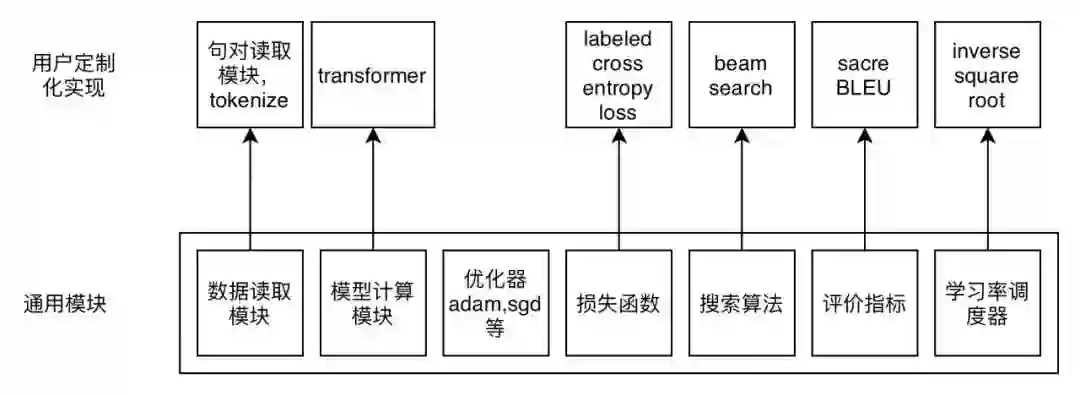
ParaGen 支持了多达 13 种可自定义模块,包括数据读入、数据预处理、数据采样、数据加载、网络模块、训练模型、推断模型、优化目标、搜索算法、优化器、数值规划器、训练算法和评价目标,相比于同类的文本生成框架,大大提高了二次开发的灵活性。而对于不同的模块,ParaGen 采用微内核的设计,每个模块只提供一些通用基本的实现,彼此之间互相独立,比如数值优化器中 InverseSquareRootRateScheduler、网络模块的 positional embedding、数据读入的 JsonDataset 等。也正是得益于这细致的 13 类模块拆解,ParaGen 可以更方便地进行自定义。例如需要实现 glancing training 的方式,在 ParaGen 里面仅仅只需要重载一个 forward_loss 函数,就可以模块化的实现自定义的训练。
import torch
from paragen.trainers.trainer import Trainer
from paragen.trainers import register_trainer
@register_trainer
class GLATTrainer(Trainer):
"""
Trainer with glancing strategy
"""
def _forward_loss(self, samples):
glancing_output = self._generator(**samples['net_input'])
fused_samples = self._fusing(samples, glancing_output)
logging_states = self._criterion(**fused_samples)
return loss
不同于既往的过程式开发,ParaGen 更偏向于组装式开发。过程式开发中,框架固定一个流程代码,用户则想办法将各个模组填入到流程里面。而 ParaGen 的组装式开发则是完全不同。想象你目前正要实现一个任务,ParaGen 像是一个工具箱,你可以根据自己想要的功能组装出一个完整的流程出来,比如可以选择合适的 Dataset 类来进行数据读取、选择 Sampler 来进行 batch 组合、选择 Metric 来进行结果评估、甚至定义自己的训练流程等等。而在碰到了没有实现的工具时,ParaGen 的工具又可以作为父类使用,通过重载一小部分的函数来定制自己的专属工具,以适配更多的任务。
与此同时,ParaGen 代码结构拆解的更加细致,用户只要花 2-3 小时阅读代码就能了解整个项目的框架,从而定制自己的任务。不仅如此,ParaGen 也提供了相应的教程,帮助初学者认识学习了解整个 ParaGen 代码的基本知识和使用方式。
ParaGen 让开发更稳定
ParaGen 能够很好的支持不同方向的同时开发。ParaGen 支持可插拔的方式进行代码开发,允许用户脱离框架进行开发。用户可以在任何的目录下开发自己专属的模块,并通过 --lib {my_lib} 命令进行导入 ParaGen 执行,使得二次开发代码独立于主代码,更加有利于二次开发代码的维护和主框架的稳定,保证了不同项目开发的并行性和稳定性,不会引起彼此代码的冲突。
ParaGen 采用 apache2 开源协议,该协议十分宽松,比如允许其他开发人员二次开发后闭源等,方便更多的优秀开发人员或者团队的参与。
作为首款翻译质量超过传统自回归模型的并行文本生成软件,ParaGen 证明了同时兼顾速度和质量的可行性,为后续研究提供了可复现的实现。在应用层面,极大地满足了终端部署的低功耗快速响应的性能需求。在后续的开发中,ParaGen 一方面会探索更多并行算法,比如条件随机场模型,进一步提高性能。另一方面也会开拓更多的部署环境,比如移动终端,嵌入式系统等等,方便更多实际场景的应用开发。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com


