去年来自谷歌大脑的研究团队在网络架构设计方面挖出新坑,提出 MLP-Mixer ,这是一个纯 MLP 构建的视觉架构。该架构无需卷积、注意力机制,仅需 MLP,在 ImageNet 数据集上就实现了媲美 CNN 和 ViT 的性能表现。
之后清华大学等机构的研究者先后将纯 MLP 用于构建视觉架构和新的注意力机制,这些研究将 CV 的研究重心重新指向 MLP。
众多研究者纷纷感叹:CV 领域网络架构的演变从 MLP 到 CNN 到 Transformer 再回到 MLP,真简直是一场 AI 领域的「文艺复兴」。
时隔不到一年,来自 IBM Research 的研究团队近日又提出了 pNLP-Mixer,将 MLP-Mixer 应用于自然语言处理(NLP)任务。
![]()
论文地址:https://arxiv.org/pdf/2202.04350.pdf
大型预训练语言模型极大地改变了 NLP 的格局,如今它们成为处理各种 NLP 任务的首选框架。但是,由于内存占用和推理成本,在生产环境中使用这些模型(无论是在云环境还是在边缘环境)仍然是一个挑战。
研究者开始提出可替代方案,他们最近对高效 NLP 的研究表明,小型权重高效(weight-efficient)模型可以以很低的成本达到具有竞争力的性能。IBM Research 提出的 pNLP-Mixer,是一种可用于 NLP 任务的基于投影(projection)的 MLP-Mixer 模型,它通过一个全新的投影层(projection layer)实现了高权重效率。
该研究在两个多语言语义分析数据集 MTOP 和 multiATIS 上对模型进行了评估。结果表明,在 MTOP 数据集上,pNLP-Mixer 达到了与 mBERT 媲美的性能,而后者有 38 倍多的参数,此外,pNLP-Mixer 还优于小模型 pQRNN,而后者参数是前者的 3 倍。在长序列分类任务中,pNLP-Mixer 在没有进行预训练的情况下比 RoBERTa 表现更好,后者的参数是 pNLP-Mixer 的 100 倍。
作为一种从头开始设计的高效架构,pNLP-Mixer 适用于两种边缘情况,即内存和延迟受限,并作为 NLP pipeline 的主干网络而存在。
![]()
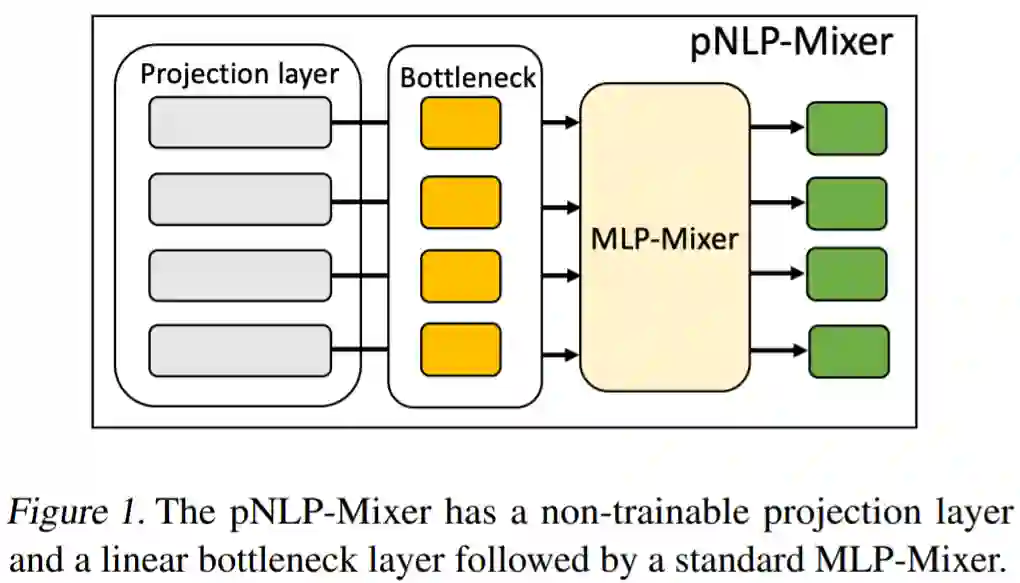
图 1 描述了 pNLP-Mixer 模型的架构,是基于投影的模型,不像基于 transformer 的模型那样可以存储大型嵌入表。pNLP-Mixer 使用投影层,该投影层使用不可训练的哈希函数从单个 token 中捕获词法知识。这个投影层可以被看作是从输入文本中生成表征的特征提取器。一旦输入特征被计算出来,它们就会被送入一个称为瓶颈层(bottleneck layer)的可训练线性层。其中瓶颈层的输出是标准 MLP- mixer 架构(Tolstikhin et al., 2021)的一系列 MLP 块的输入。
使用全 MLP 架构进行语言处理具有一些优点。与基于注意力的模型相比,MLP-Mixer 可以捕获长距离依赖关系,而不会在序列长度上引入二次成本。此外,仅使用 MLP,模型不仅实现起来简单,而且在从手机到服务器级推理加速器的各种设备中都具有开箱即用的硬件加速功能。
这项研究表明,在 NLP 任务中,像 MLP-Mixer 这样的简单模型可以作为基于 transformer 模型的有效替代方案,即使在不使用大型嵌入表的环境中也是如此。这其中的关键是模型提供了高质量的输入特征。
投影层是基于局部敏感哈希(LSH),从文本中创建表征。虽然这一概念在其他现有的投影中是常见的(例如 pQRNN (Kaliamoorthi et al., 2021)),但该研究提出的投影方法却是全新的。MinHash 因计算简单被用作哈希函数,并依靠子词 tokenization 来确定哈希输入。子词 tokenization 通常在 transformer 模型中使用,它确保了任何字符串都可以被表征为子词单元的组合,即不存在词表外的词。在该研究的语境中,使用子词 tokenizer 有两个主要优点:
通过训练新的 tokenizer 或使用可用的预训练语言模型中的词汇来扩充语言知识;
![]()
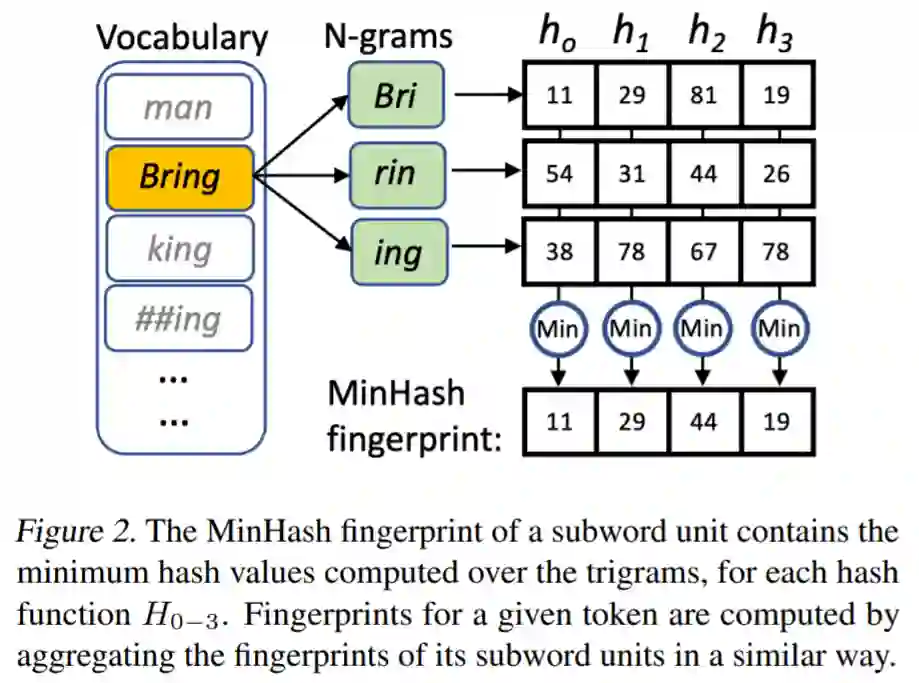
投影层通过复用词汇表 V 的单个子词单元的 fingerprint 来计算每个输入 token t 的 MinHash fingerprint F^t。fingerprint F ∈ N^n 是由 n 个正整数组成的数组(F_0 到 F_(n-1) ) ,使用 n 个不同的哈希函数 h_0(x) 到 h_n-1(x) 将字符串映射成正整数来进行计算。
MLP-Mixer 是一个简单的架构,仅由 mixer 块组成,每个块有两个多层感知器 (MLP),以换位操作(transposition operation)进行交错。第一个 MLP 输出的换位给到第二个 MLP,然后对序列维度进行操作,从而有效地混合了 token 之间的信息。此外,MLP-Mixer 遵循了最初的架构设计,使用了跳跃连接、层标准化和 GELU 非线性。
在该方法中,投影层产生的矩阵 C∈R^(2w+1)m×s 将通过一个瓶颈层,即一个线性层,该线性层输出矩阵 B∈R^b×s,其中 B 为瓶颈大小,s 为最大序列长度。这个矩阵 B 是 MLP-Mixer 模型的输入,它反过来产生与 B 相同维度的输出表征 O∈R^(b×s)。在输出 O 之上应用分类头以生成实际预测。在语义解析的情况下,这个分类头是应用于每个 token 的线性层,而对于分类任务,该方法使用注意力池化。
在评估模型的最终性能之前,该研究彻底分析了所提架构。本节的实验是在英文 MTOP 的验证集上进行的,报告的指标是最佳 epoch 的精确匹配准确率(exact match accuracy)。该研究使用具有 2 层的 pNLP-Mixer 作为基础模型,瓶颈和隐藏大小为 256,输入序列长度为 64,token 特征大小固定为 1024,窗口大小为 1,并训练 80 个 epoch,学习率为 5e ^-4 、batch 大小为 256。
首先,该研究比较了不同特征提取策略对性能的影响,包括:
BERT 嵌入
二进制
TSP
MinHash
SimHash
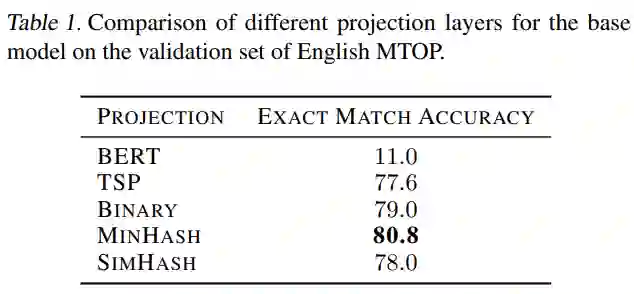
下表 1 给出了基模型获得的投影分数。结果表明,BERT 嵌入的性能极差,这是因为 BERT 的主要优势之一是它产生上下文嵌入,即包含来自周围上下文的信息的嵌入,这里需要单独嵌入每个 token。关于基于哈希的投影,它们都在相同的值范围内达到分数。然而,表现最好的投影 MinHash,精确匹配准确率为 80.8%,与最差的投影 TSP 相比,其得分为 77.6% ,它们之间存在相当大的差异。超过 3% 的差异凸显了仔细设计投影层的重要性,并证明了进一步研究投影算法的努力。鉴于这些结果,在剩下的实验中,该研究仅将 MinHash 视为投影层。
![]()
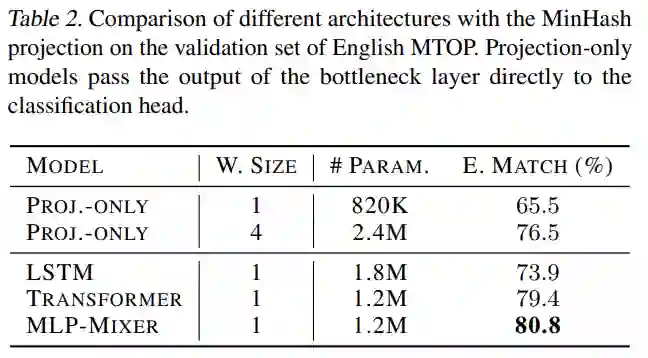
已有结果表明,MinHash 投影提供了强大的语言表征。下一个问题是 MLP-Mixer 是否是处理这种表征的最佳架构。为了研究这一点,该研究首先考虑一个基线,其中 MLP-Mixer 被移除,瓶颈层的输出直接传递给分类头。在这里,研究者考虑两个不同的投影层,一个窗口大小为 1,另一个窗口大小为 4。该研究将 MLP-Mixer 与其他两种架构进行比较,方法是保持相同的投影、瓶颈层和分类头,并用 LSTM 和具有相似数量参数的 transformer 编码器专门替换 MLP-Mixer。
表 2 表明简单地移除 MLP-Mixer 并仅依赖投影会导致性能显着下降。特别是,使用窗口大小为 1 的投影将参数数量减少到 820K,但代价是性能下降超过 15 个点。另一方面,大型投影层导致参数数量翻倍,而精确匹配准确率仅达到 76.5%,即比 MLP-Mixer 低 4.3%。从替代模型来看,LSTM 的性能明显低于 MLP-Mixer,但使用 180 万个参数,即多出 50%,精确匹配准确率较低(73.9%)。Transformer 模型的参数数量与 MLPMixer (1.2M) 大致相同,得分低 1.4%。最后一个结果是显着的:对于相同数量的参数,MLPMixer 优于 transformer,同时具有线性复杂性依赖于输入长度,而不是二次。总体而言,该评估表明 MLP-Mixer 是一种用于处理投影输出的重量效率高的架构,即它比具有较少参数的替代方案具有更高的性能。
![]()
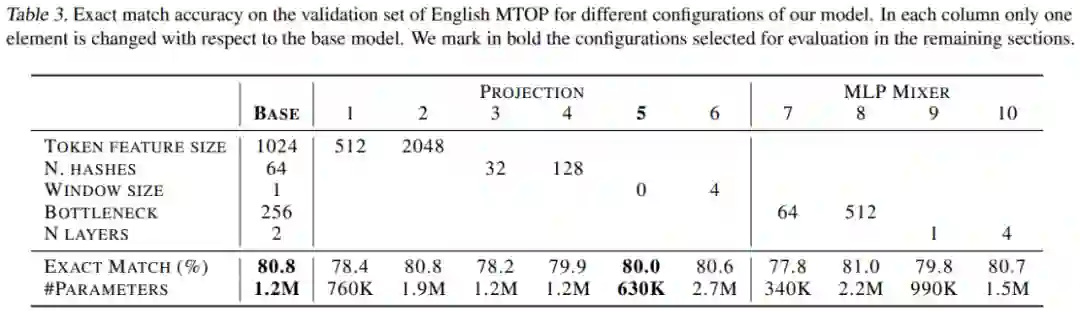
该研究对 pNLP-Mixer 模型进行了广泛的架构探索,以确定不同超参数对下游性能的影响,研究范围包括投影超参数和 MLP-Mixer 超参数。对于投影,研究包括 token 特征大小、哈希数和窗口大小;而 MLP-Mixer 研究了瓶颈大小(bottleneck size)和层数。使用的学习率为 5e^−4,batch 大小为 256,隐藏大小为 256。表 3 报告了每个配置的精确匹配准确率和参数数量。
![]()
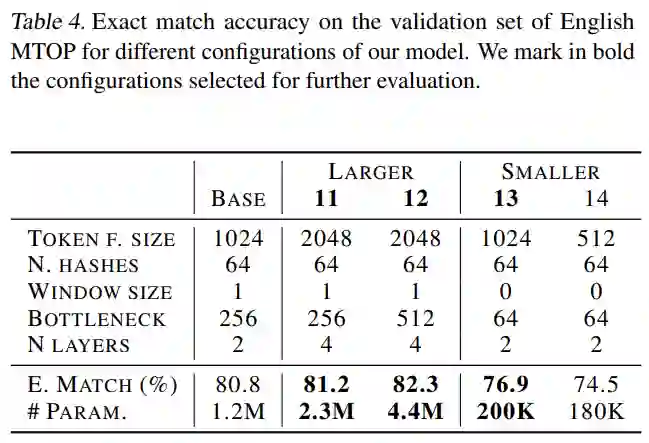
考虑到 MLP mixer,将瓶颈大小(bottleneck sizes)增加到 512 会略微提高性能,而当使用 4 层时,它会达到与 2 层相似的值。然而,这些超参数并不独立于投影层:较大的投影可能需要较大的 MLP-Mixer 来处理所有的信息。因此,表 4 研究了投影大小和 MLP-Mixer 之间的关系。
实验报告了两个较大模型和两个较小模型的结果,由结果可得较大的模型具有更大的特征和瓶颈大小,实验还表明 4 层达到了所有研究模型的最佳性能。另一方面,其中一个小型模型仅用 200K 参数就达到了 76.9% 的精确匹配。
![]()
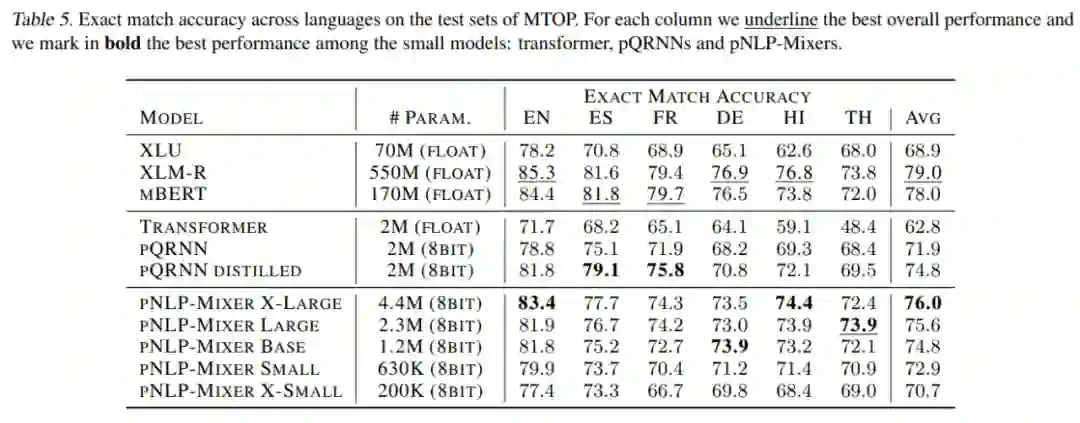
表 5 结果表明,大型语言模型 XLM-R 和 mBERT 获得了最高分。值得注意的是,从较小的替代方案来看,pNLPMixer X-LARGE 只有 4.4M 参数, mBERT 参数量达 170M,平均精确匹配准确率仅比 mBERT 和 XLM-R 低 2 和 3 个点。LARGE 模型具有与 pQRNN 相似的大小,比 pQRNN 精确匹配准确率高近 3%,比精馏后的 pQRNN 高 0.8%。
![]()
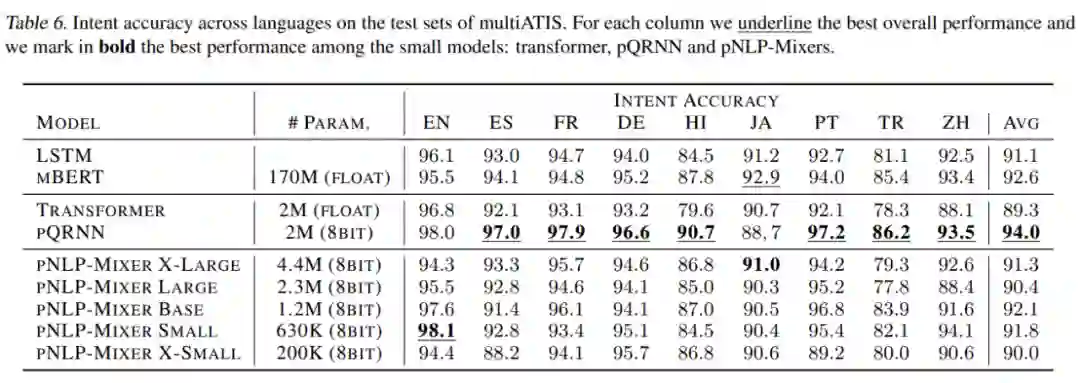
表 6 是在 multiATIS 数据集上的评估结果。在这里,pQRNN 获得了最高的 intent 准确率,甚至比 mBERT 高出 1.8%。在 pNLP-Mixer 系列中,我们看到更大的尺寸并不对应更好的性能;由于 ATIS 查询中使用的词汇相对统一和简单,因此表达能力更强的模型不一定更好。事实上,BASE 模型在 pNLP-Mixers 中达到最高分,达到 92.1%,仅比只有 1.2M 参数的 mBERT 低 0.5%,但参数只有 pQRNN 参数的 60%。较小的 pNLP-Mixer 模型 SMALL 和 X-SMALL 分别获得了 91.8% 和 90.0% 的竞争性能,而参数都非常小。
![]()
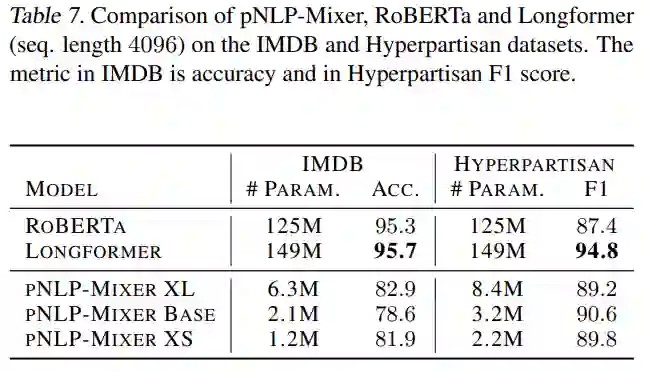
表 7 显示,在 IMDB 中,RoBERTa 和 Longformer 的性能明显优于 pNLP-Mixer,Longformer 的准确率达到 95.7%,而最好的 pNLP-Mixer 只有 82.9%。然而,在 Hyperpartisan 任务中,Longformer 仍然是最好的模型,而 pNLP-Mixers 的表现优于 RoBERTa, BASE 模型达到 90.6 F1,即高出 3.2 分。
微型 pNLP-Mixer 模型的参数分别是 Longformer 和 RoBERTa 参数的 1/ 120 倍和 1/ 100 ,在 Hyperpartisan 任务中获得了具有竞争力(甚至优于 RoBERTa)的结果,而无需任何预训练或超参数调整。然而,pNLP-Mixer 在 IMDB 上的性能较低。总而言之,这个结果提出了一个问题,即具有预训练的大型 pNLP-Mixer 是否可以成为大型 Transformer 模型的轻量级替代品。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com