【NeurIPS 2020】核基渐进蒸馏加法器神经网络
Kernel Based Progressive Distillation for Adder Neural Networks

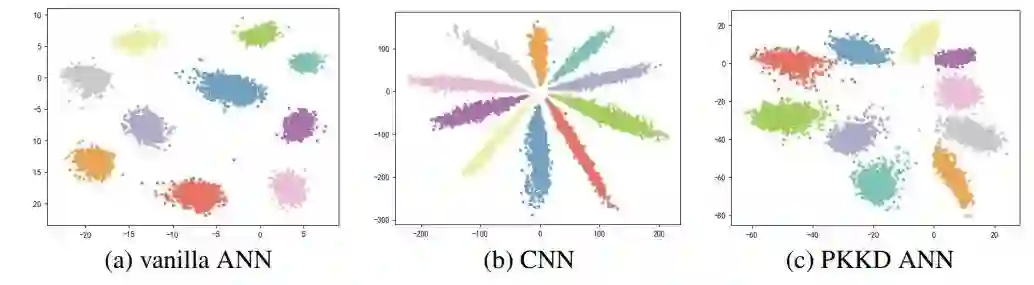
只包含加法操作的加法神经网络 (ANN)为开发低能耗的深层神经网络提供了一种新的途径。但是,当用加法滤波器替换原始的卷积滤波器时会带来精度下降。其主要原因是采用L1-范数进行神经网络优化比较困难。在这种情况下,反向传播的梯度通常会估计不准确。本文提出一种在不增加可训练参数的前提下,通过基于核的渐进式知识蒸馏(PKKD)方法进一步提高ANN的性能。我们将与ANN具有相同结构的卷积神经网络(CNN)进行随机初始化并作为教师网络,将ANN和CNN的特征和权重通过核变换映射到一个新的空间,减少了分布之间的差异,从而消除了精度下降问题。最后,ANN通过渐进的方法同时学习标签和教师网络的知识。该方法在几个标准数据集上得到了很好的验证,从而有效地学习了具有较高性能的ANN。例如,使用所提出的PKKD方法训练的ANN-50在ImageNet数据集上获得76.8%的精度,比相同结构的ResNet-50高0.6%。
https://www.zhuanzhi.ai/paper/3cb74130e9cf983a7247e0d4a0d6bbce
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“PKKD” 可以获取《【NeurIPS 2020】核基渐进蒸馏加法器神经网络》专知下载链接索引



登录查看更多
相关内容



相关VIP内容
相关资讯
相关论文