大数据时代小样本如何学习?看这篇最新《小样本学习方法综述》论文
【导读】基于神经网络的深度学习方法往往需要大量标注样本,而在很多领域往往是缺乏充足样本数据的,比如在医疗领域,高质量的医疗影像大数据样本很难获取,且人工标注成本较高。因此,亟待研究基于小样本数据集或弱标签标注的机器学习方法。最近,齐国君和罗杰波两位知名学者在ArXiv发布了关于小样本数据集的无监督与半监督学习综述论文,12页103篇参考文献,详细阐述了最新进展。

大数据时代的小数据挑战:无监督和半监督方法研究进展综述
摘要
在许多学习问题中都出现了小的数据挑战,由于深度神经网络的成功往往依赖于收集大量昂贵的标记数据。为了解决这一问题,人们在以无监督和半监督的方式训练具有小数据的复杂模型方面做了许多努力。本文就这两大类方法的研究进展进行综述。我们将在一个大的图谱中对一系列小数据模型进行分类,在这里我们将展示它们如何相互作用,从而激发对新思想的探索。我们将回顾学习转换等变、解纠缠、自我监督和半监督表示的标准,这些标准为最近的发展奠定了基础。许多无监督和半监督生成模型的实例都是在这些标准的基础上开发的,通过探索无标记数据的分布以获得更强大的表示,极大地扩展了现有自动编码器、生成对抗网(GANs)和其他深层网络的领域。在关注无监督和半监督方法的同时,我们还将对其他新出现的主题进行更广泛的回顾,从无监督和半监督领域的自适应,到转换等方差和不变性在训练大范围深度网络中的基本作用。我们旨在探索这一领域的主要理念、原则和方法,以揭示我们在解决大数据时代的小数据挑战的道路上的前进方向。
引言
本文旨在全面阐述无监督和半监督方法的最新进展,以解决在大量无标签数据可用的情况下使用少量有标签数据训练模型所面临的挑战。深度学习的成功往往取决于大量有标记数据,在这些数据中,数以百万计的图像被标记,以训练深度神经网络,使这些模型能够达到甚至超过人类的性能。
然而,在许多情况下,收集足够多的标记数据是具有挑战性的,这激发了许多研究努力,探索标记数据之外的非监督信息,为各种学习任务训练健壮的模型。
无标计数据。虽然标记数据的数量非常少,但是未标记的数据规模可能非常大。那些没有标记的分布数据为学习鲁棒表示提供了重要线索,这些鲁棒表示可以推广到新的学习任务中。根据是否利用附加的标记示例来训练模型,可以使用无监督和半监督两种方式利用未标记的数据。无标记数据还可以帮助模型缩小不同任务之间的领域差距,这导致了大量的无监督和半监督领域适应方法。
辅助任务。辅助任务也可以作为侧边信息的重要来源来缓解小数据问题。例如,a相关任务可以是与目标任务相关的一组不相交概念上的学习问题。这属于零样本学习(ZSL)和小样本学习(FSL)问题。在广义上,ZSL问题可以看作是一个无监督学习问题,目标任务上没有带标记的例子,而FSL是半监督的,几乎没有可用的带标记的数据。两者都旨在将语义知识或学习知识(如元学习[3]、[4])从源任务转移到目标任务。
本研究以无监督和半监督方法为研究重点,以无标记的例子来解决小数据问题。虽然我们将不回顾ZSL和FSL方法,利用辅助任务的信息,这将是有益的,我们开始从一个大的图谱详述所有这些方法。这将使我们更好地理解我们在克服小数据挑战的过程中所处的位置。
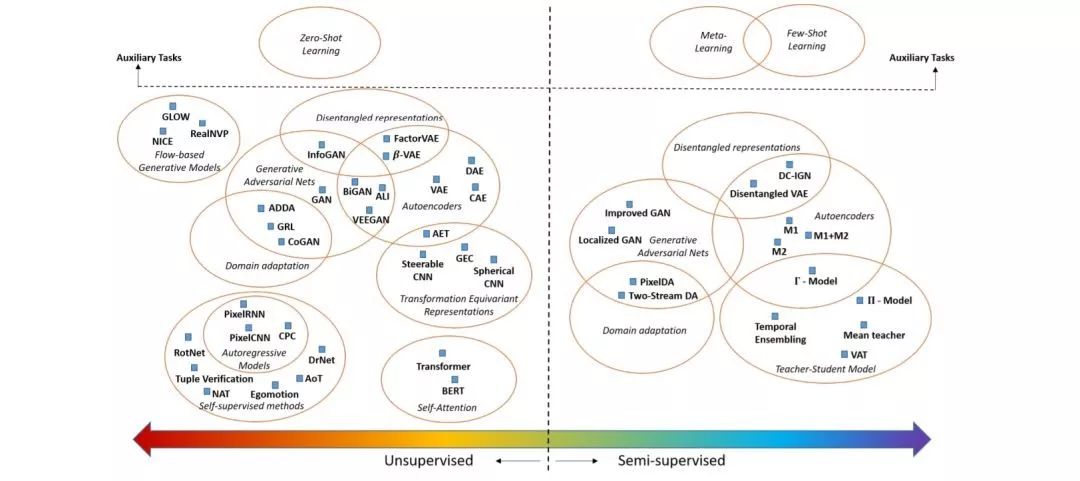
图 1. 小数据方法概览

图2. 该图展示了在无监督和半监督方法的情况下,小数据方法的分类
更多请阅读论文查看:
http://www.zhuanzhi.ai/paper/e0b5e03d4d0358b7bf3886ebce3cae83
【论文便捷下载】
请关注专知公众号(点击上方蓝色专知关注)
后台回复“SDL2019” 就可以获取《大数据时代的小数据挑战:无监督和半监督方法研究进展综述》的下载链接~
-END-
专 · 知
专知《深度学习:算法到实战》课程全部完成!520+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询《深度学习:算法到实战》课程,咨询技术商务合作~

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程

