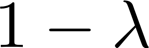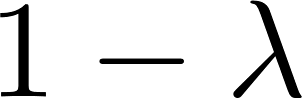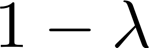It can be challenging to train multi-task neural networks that outperform or even match their single-task counterparts. To help address this, we propose using knowledge distillation where single-task models teach a multi-task model. We enhance this training with teacher annealing, a novel method that gradually transitions the model from distillation to supervised learning, helping the multi-task model surpass its single-task teachers. We evaluate our approach by multi-task fine-tuning BERT on the GLUE benchmark. Our method consistently improves over standard single-task and multi-task training.
翻译:为解决这一问题,我们建议使用知识蒸馏法,让单任务模型教授多任务模型。我们用教师整顿方法加强这种培训,这是一种新颖的方法,可以逐步将模型从蒸馏转变为有监督的学习,帮助多任务模型超越单一任务教师。我们用多任务微调BERT来评估我们的方法,在GLUE基准上进行。我们的方法在标准单任务和多任务培训方面不断改进。