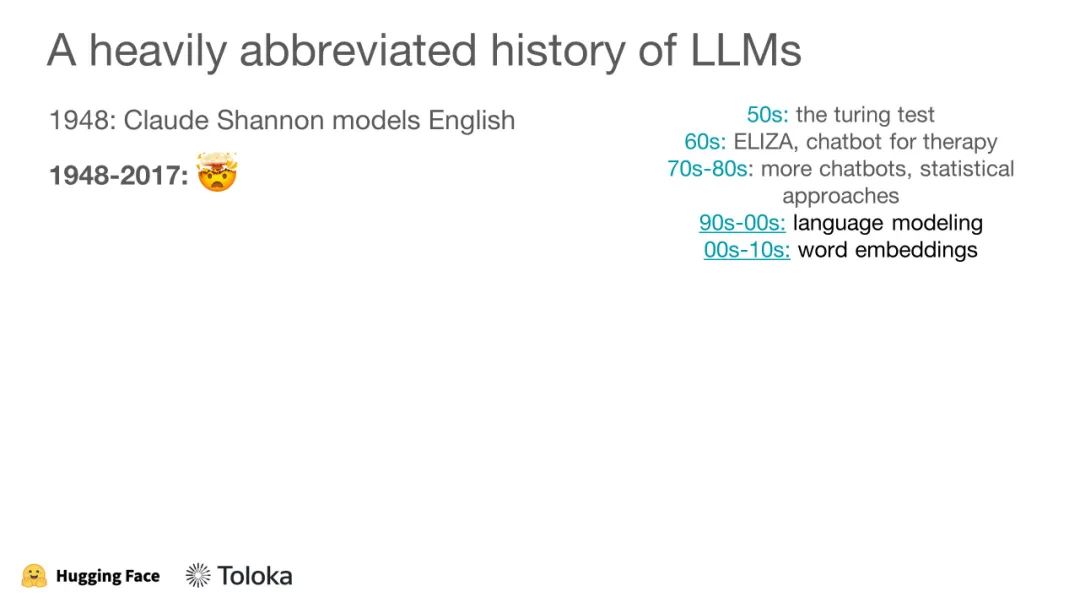
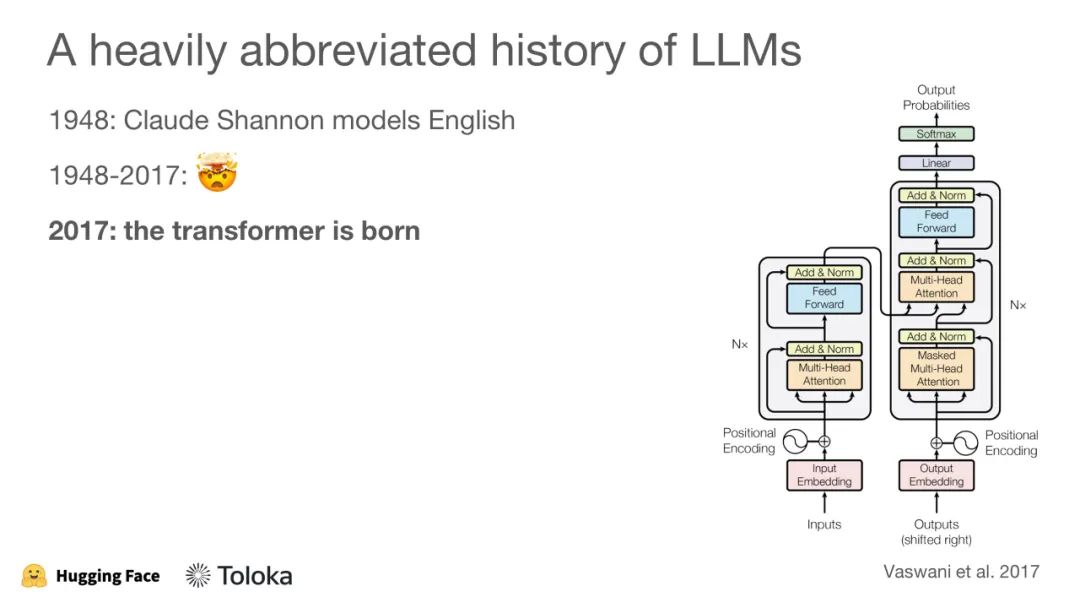
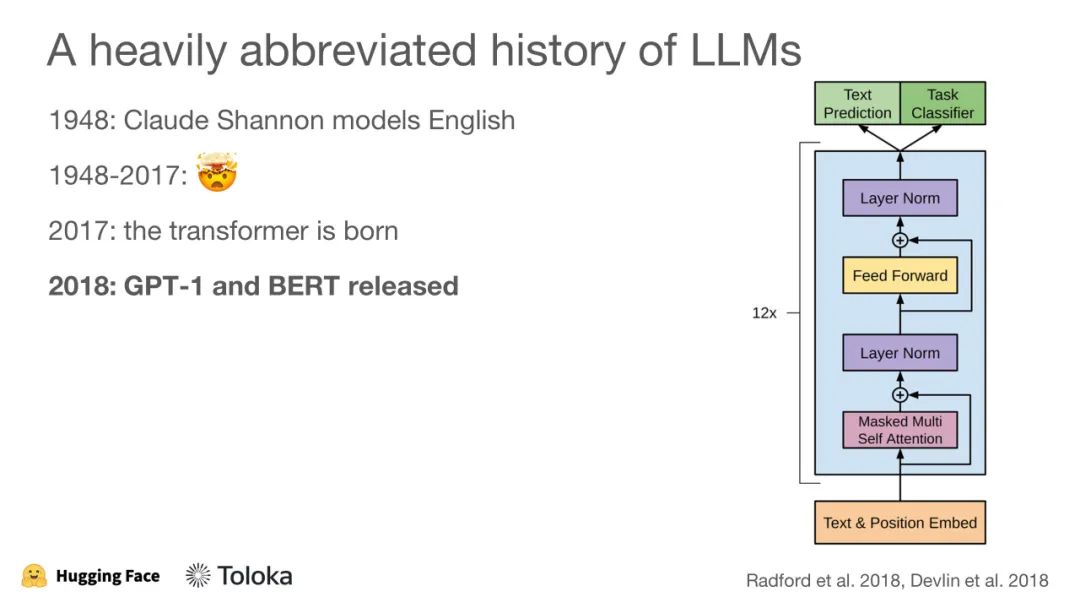
ICML 2023 是第四十届国际机器学习会议,将于 2023 年 7 月 23 日至 29 日在美国夏威夷举行。ICML 共收到 6538 份投稿,其中 1827 份被接收,接收率约为 27.9%。作为对比,去年共收到 5630 投稿,接收 1117 篇 short oral,118 篇 long oral,录用率为 21.94%。ICML(International Conference on Machine Learning,国际机器学习大会)为国际机器学习学会主办的国际会议,被公认是人工智能、机器学习领域最顶级的国际会议之一。
来自Hugging Face研究科学家 Nathan Lambert和Toloka AI Dmitry Ustalov在ICML 2023教程《Reinforcement Learning from Human Feedback: A Tutorial》讲解通过人类反馈的强化学习(RLHF),非常值得关注!
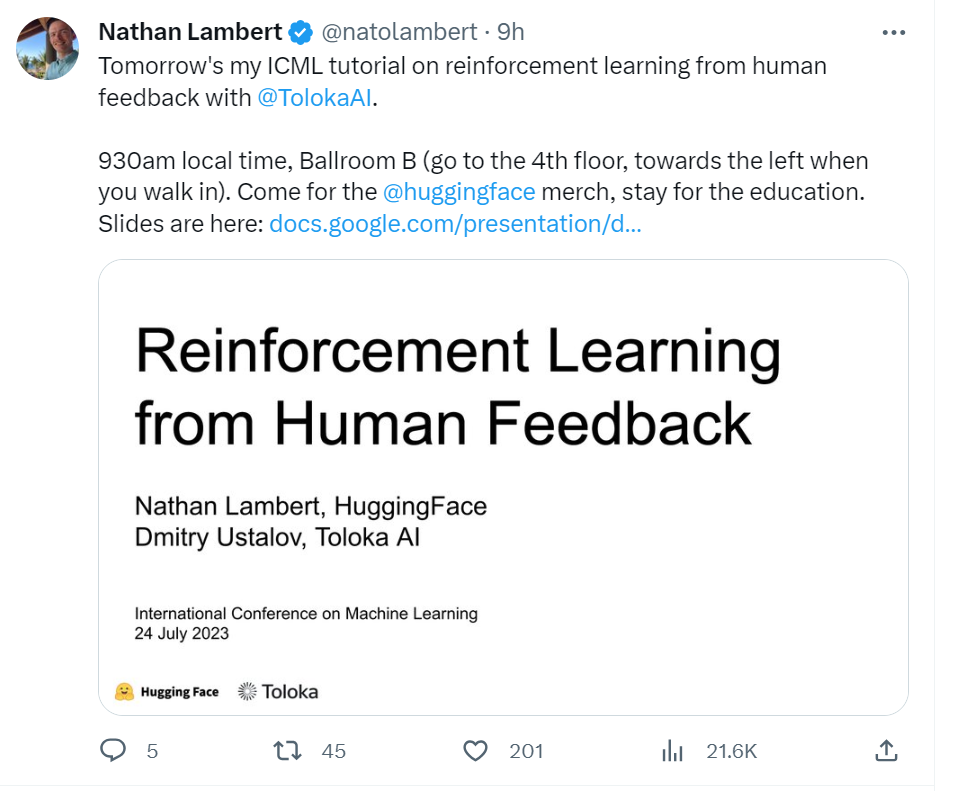
通过人类反馈的强化学习(RLHF)已极大地提高了大型机器学习模型在实际应用中的性能和用户体验。但是,这种方法对大多数学术研究者而言仍然遥不可及。 我们的教程涵盖了一个成功的RLHF项目的两个核心部分:RLHF背后的核心机器学习技术,以及用于收集人类反馈数据的人在循环中的方法。作为家庭作业,您将进行您的第一个RLHF实验,执行一个简单的创造性任务,为用户请求的项目制作前5名的列表(例如,感恩节餐点的顶级想法)。
教程:
技术概述将RLHF过程分解为三个主要阶段:为基本策略进行语言建模,对人类偏好进行建模,以及使用RL进行优化。本教程的这一部分将是技术性的,并将描述潜在的研究问题、陷阱以及成功项目的技巧。
人类标注用于RLHF
在这一部分,我们将讨论收集人工生成的文本和进行人类偏好评分的挑战。我们将关注RLHF的人类注释的三个方面:
-
数据标注的基础。介绍使用众包进行数据标签的方法,以及将人类输入整合到ML系统中。我们将讨论如何避免常见的陷阱,并向大众提供良好的说明。
-
收集人类增强的文本。我们将讨论收集人类增强文本的挑战,这些文本对于训练指令任务的初始语言模型至关重要。
-
收集人类评分。我们将为您展示获得用于训练奖励模型的提示完成的人类评分的三种方法。
讲者:
Nathan Lambert 是 HuggingFace 的研究科学家和 RLHF 团队负责人。他在加利福尼亚大学伯克利分校获得了博士学位,主要研究机器学习与机器人技术的交叉领域。他的导师是伯克利自主微系统实验室的 Kristofer Pister 教授和 Meta AI Research 的 Roberto Calandra。在攻读博士期间,Nathan 很幸运地在 Facebook AI 和 DeepMind 实习。由于他为改善社区规范所做的努力,Nathan 被授予了加州大学伯克利分校电子工程与计算机科学系的 Demetri Angelakos Memorial Achievement Award for Altruism。Dmitry Ustalov, Head of Ecosystem Development