第37届国际人工智能大会(AAAI2023)于2023年2月7日-2月14日在美国华盛顿召开。AAAI是CCF推荐的A类国际学术会议,在人工智能领域享有很高的学术声誉。这次会议共收到来自8777篇投稿,录用1721篇,录用率约19.6%。来自UIUC、哥伦比亚大学等学者带来了《知识驱动视觉语言预训练》教程,非常值得关注!


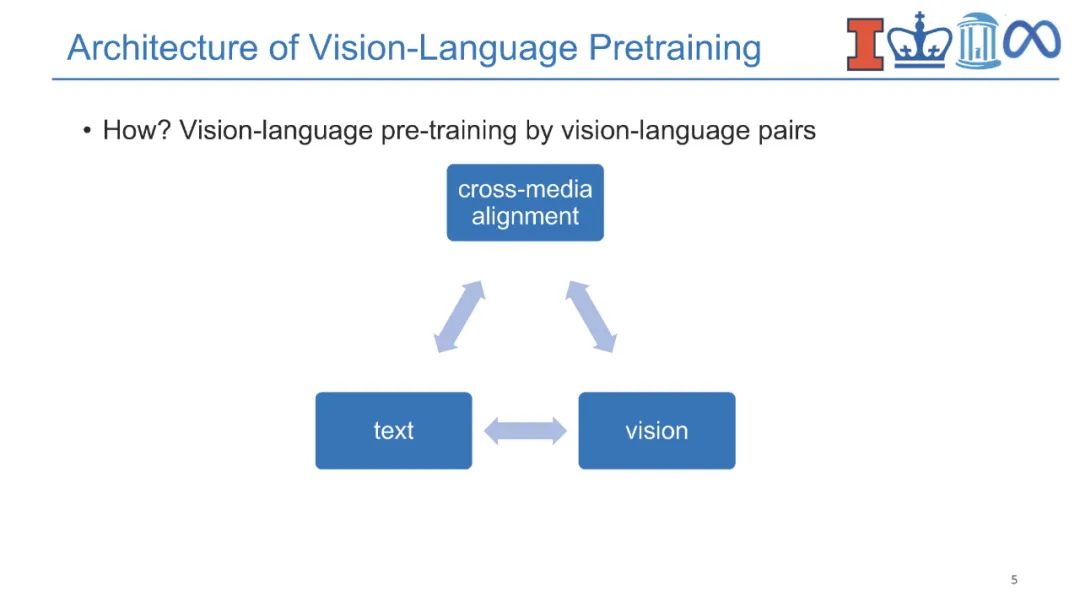
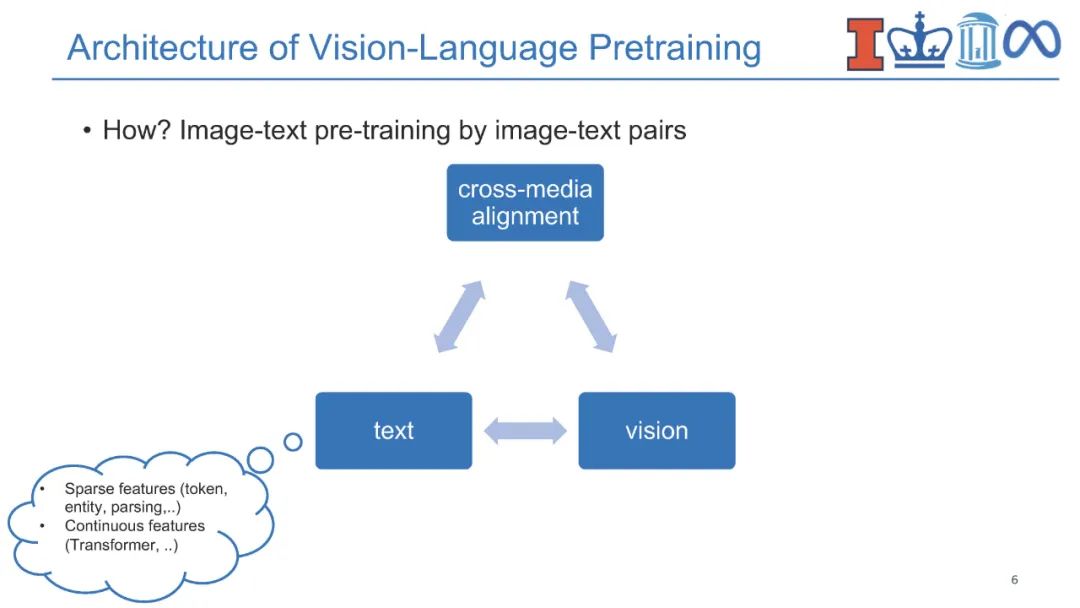
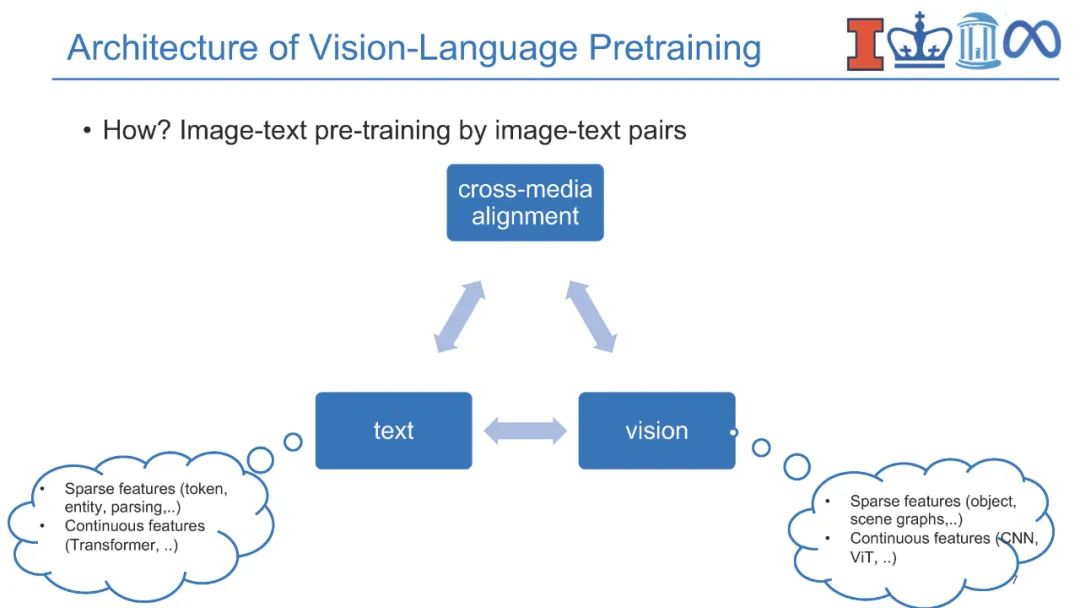
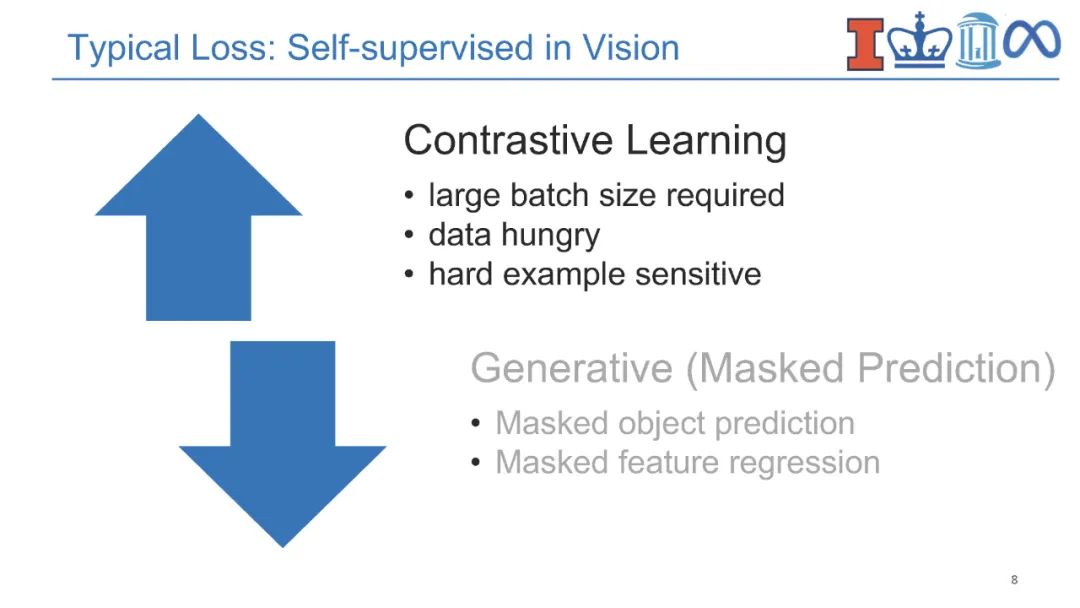
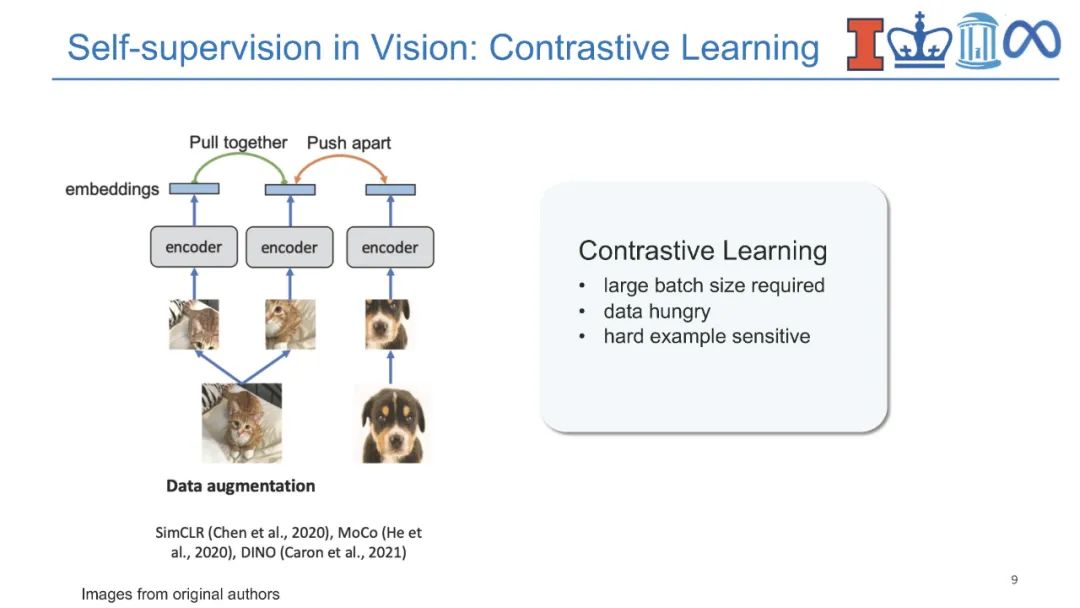
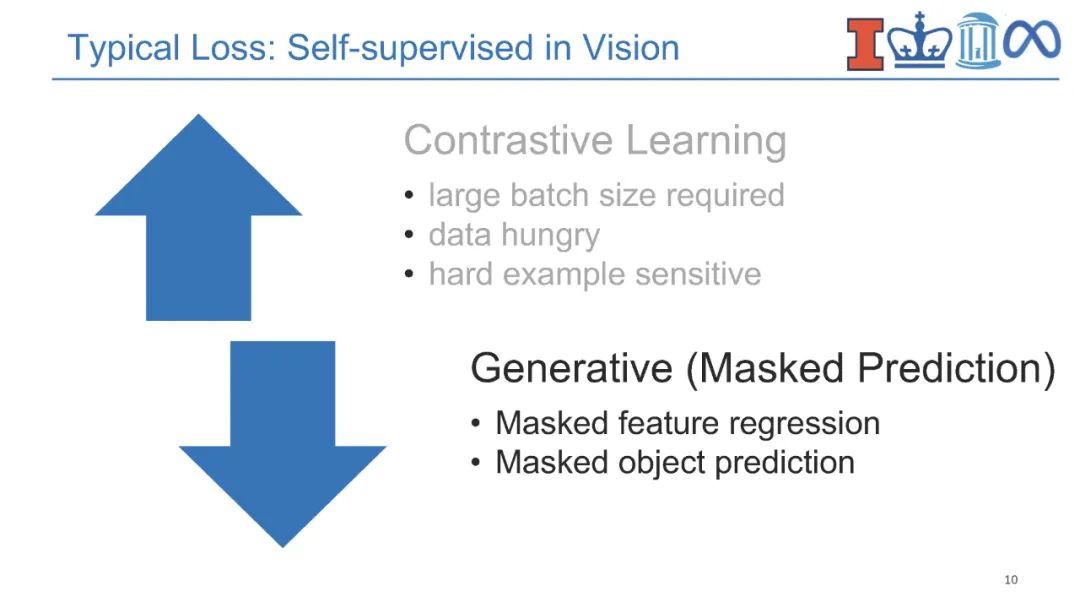
**近年来,视觉-语言(V+L)预训练模型通过学习视觉和文本之间的对齐在多媒体应用中取得了巨大成功。**对实体知识(即物体和物体类型)的理解是各种V+L任务的基本能力,如图像描述和视觉问答。它们还需要理解相关知识(即场景图)的能力,这些知识可以进一步支持组合式视觉问答、场景图解析等。除此之外,具有事件论元结构的事件知识(即事件类型、动作、活动)对于支持视觉常识推理、情景识别、动作识别和人与物体交互等认知级视觉理解至关重要。为了跟踪事件和实体的状态变化,将过程性知识引入视频问答、动作识别、动作分割、动作定位、动作预测和过程规划等领域。语言模型中的知识也可以有利于视觉-语言预训练,而不是显式地获取结构化知识。因此,将知识添加到视觉-语言预训练中提出了两个关键挑战,即在多个层次上获取知识,以及对知识的结构和语义进行编码。

图1:在本教程中,我们将介绍高级视觉-语言方法,这些方法结合了来自各种来源的知识。 **在本教程中,我们将全面回顾现有的多媒体知识发现和编码范式,并重点关注它们对视觉-语言预训练的贡献。**我们将知识分为内部自我知识和外部自我知识。从文本和视觉模态中提取内部知识,如结构化实体、关系、事件和事件程序。我们将重点关注知识的结构方面,并解决关于跨多模态知识获取和结构编码的两个关键挑战。外部知识可以从知识库或语言模型中获得,本文将举例说明它们在帮助视觉模态的常识理解方面的用途,重点是时间和认知方面。本教程的目标是向参与者介绍知识驱动的视觉-语言研究的最新趋势和新挑战,以及供参与者获得现成模型的学习资源和工具,推动关于结构化知识对文本和视觉学习的影响的深入讨论。
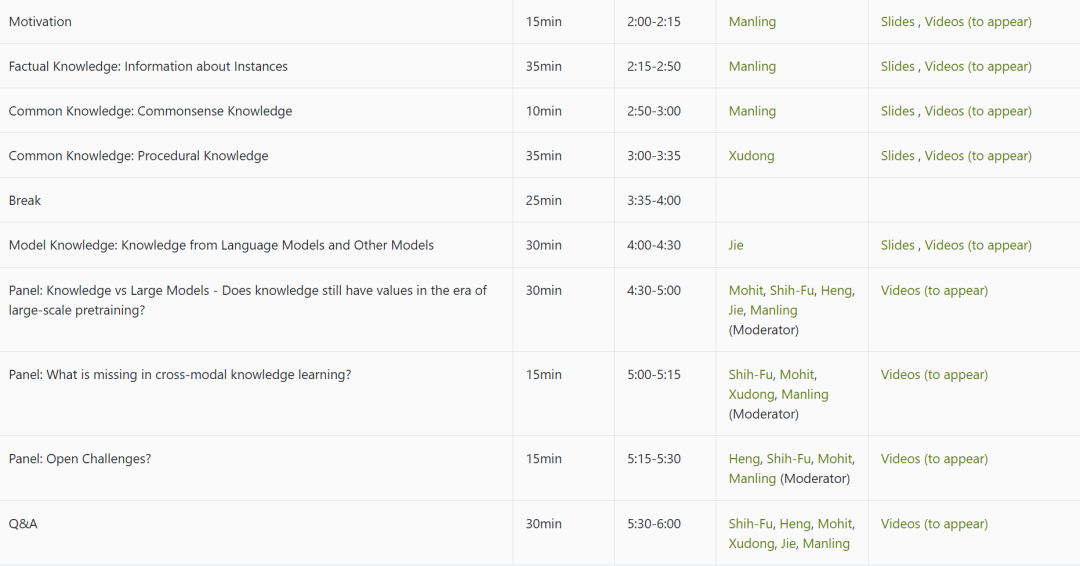
讲者:

目录内容: