

论文题目:RIOT: Efficient Prompt Refinement with Residual Optimization Tree
本文作者:周宸逸(浙江大学)、史峥言(伦敦大学学院)、姚远(浙江大学)、梁磊(蚂蚁集团)、陈华钧(浙江大学)、张强(浙江大学)
发表会议:ACL 2025 Main
论文链接:敬请期待
代码链接:https://github.com/Qing1Zhong/RiOT
欢迎转载,转载请注明出处****

一、动机
近年来,大型语言模型(LLMs)在各类自然语言任务中展现出卓越性能。然而,其性能高度依赖于输入提示(prompts)的质量。尽管已有若干提示词自动优化框架(如 APE、OPRO、TextGrad 等),但现有方法仍面临两项核心挑战:
- 优化空间受限导致探索能力不足:现有方法在每轮迭代中通常仅生成单一候选提示词,缺乏对提示词语义空间的系统性探索,难以捕捉潜在的高质量优化方向,限制了优化策略在复杂任务中的泛化能力。
- 语义漂移问题影响稳定性:提示词的迭代更新过程中常出现语义偏移,即为某一特定场景优化的提示词可能破坏其在其他场景中的有效性,导致泛化性能下降。该问题本质上类似于持续学习中的稳定性–可塑性冲突(Stability–Plasticity Dilemma),但尚未在离散文本优化场景中获得系统性解决。
**
**
二、方法概述
本工作提出 RiOT(Residual Optimization Tree) 框架,系统性解决上述挑战。RiOT 是一种基于文本梯度的黑盒 prompt 优化方法,融合树结构搜索、信息论启发的选择机制和残差语义融合策略,主要特点包括:
- 树结构搜索机制:在每轮优化中并行生成多个候选提示词(节点),构建树状搜索结构,从而系统性扩展优化空间。
- 困惑度驱动的节点选择策略:从信息增益角度出发,优先选择困惑度更高(信息量更大)的候选提示词,提升探索多样性与信息密度。
- 文本残差连接机制:引入语义残差融合策略,在父子节点间保留语义一致性,有效缓解语义漂移;

三、实验结果
实验在五个具有代表性的推理任务上进行,涵盖逻辑推理(LogiQA 2.0)、常识推理(StrategyQA)、数学计算(GSM8K)、语义计数(Object Counting)与时间理解(Date Understanding),目标模型为 GPT-3.5-turbo,优化模型为 GPT-4o。所有方法均采用相同的数据采样策略,基于固定训练与验证集进行优化,最终在测试集上评估性能,并报告五次独立运行的平均准确率及标准差。
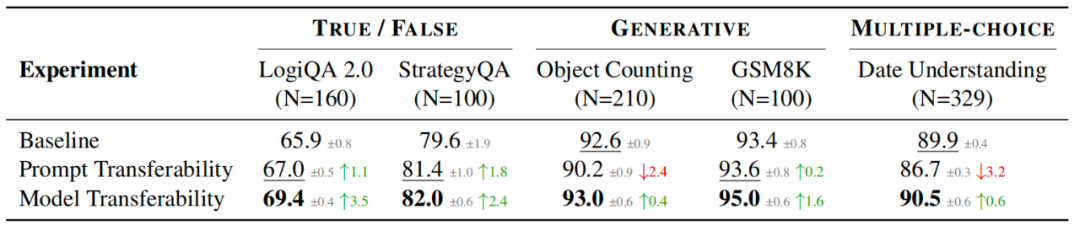

- 提出首个引入“残差优化”思想的树状提示词自动优化框架,拓展提示词优化空间的同时保持语义一致性;
- 构建基于困惑度的选择机制,有效提升优化多样性与信息量探索能力;
- 提出文本残差连接算法,借助嵌入空间语义匹配机制缓解语义漂移问题;
- 在五个公开基准数据集与多个强基线对比中验证其 SOTA 性能。