无源无监督领域自适应(SFUDA)旨在将预先训练的源模型适配到未标记的目标域,而无需访问标记良好的源数据,由于数据隐私、安全和传输问题,SFUDA有广阔的应用领域。来自北卡罗来纳大学教堂山分校等学者发布了《无源领域自适应综述》,现有的SFUDA方法进行了及时和系统的文献综述

基于深度学习的无监督域适应(UDA)因解决不同域之间分布差异导致的域偏移问题而引起了人们的关注。现有UDA方法高度依赖源域数据的可访问性,而在实际场景中,由于隐私保护、数据存储和传输成本以及计算负担等原因,可访问性通常受到限制。为了解决这一问题,近年来提出了许多无源无监督域适应(source-free unsupervised domain adaptation,简称SFUDA)方法,在源数据不可访问的情况下,从预训练的源模型到无标记的目标域进行知识迁移。全面回顾这些研究工作具有重要意义。本文从技术角度对现有的SFUDA方法进行了及时和系统的文献综述。将当前的SFUDA研究分为两组,即白盒SFUDA和黑盒SFUDA,并根据其使用的不同学习策略进一步将其划分为更细的子类别。研究了每个子类别中方法的挑战,讨论了白盒和黑盒SFUDA方法的优缺点,总结了常用的基准数据集,并总结了不使用源数据提高模型泛化能力的流行技术。最后讨论了该领域未来的研究方向。
https://www.zhuanzhi.ai/paper/5eb2bf0d19cacbe56e88f7f3682ff005
1. 引言
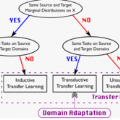
基于深度神经网络和表示学习的深度学习是近年来兴起的一项有前途的技术,并取得了显著进展,涵盖了计算机视觉[1]、[2]、医疗数据分析[3]、[4]、自然语言处理[5]、[6]等领域。对于具有多个域(例如,不同的数据集或成像站点)的问题,深度神经网络的典型学习过程是将源域上学习到的模型迁移到目标域。然而,当源域和目标域之间存在分布差距时,通常会观察到性能下降,称为"域偏移"问题[7]-[9]。针对这一问题,各种域适应算法[10]、[11]被提出,通过减少域间分布差异来进行知识迁移。为了避免密集的数据标注负担,无监督域自适应已经取得了很大的进展[12]-[15]。如图1 (a)所示,无监督域适应旨在在不访问任何目标标签信息的情况下,将知识从有标签的源域迁移到目标域。现有的无监督领域自适应深度学习研究高度依赖源数据的可访问性,在实际场景中通常受到限制,可能存在以下原因。(1)数据隐私保护。出于隐私和安全保护的考虑,许多包含机密信息的源数据集,如医疗数据、面部数据等,无法向第三方提供。(2)数据存储和传输成本。ImageNet[16]等大规模源数据集的存储和传输会带来很大的经济负担。**(3)计算量。**在非常大的源数据集上进行训练需要很高的计算资源,这是不现实的,尤其是在实时部署的情况下。因此,对无源无监督域适应(SFUDA)方法有很高的需求,这些方法在不访问任何源数据[17]-[20]的情况下,将预训练的源模型迁移到未标记的目标域。最近,许多有前途的SFUDA算法被开发出来,以解决语义分割[21]、图像分类[22]、目标检测[23]、人脸防伪[24]等领域的问题。迫切需要对当前sfudda研究的全面回顾和对未来研究方向的展望。Liu et al.[25]对无数据知识转移进行了综述,其中SFUDA只占了综述的一部分,SFUDA的分类总体上比较粗糙。在过去的一年中出现了大量相关的研究,但相关的论文并未包括在该调查中。此外,他们的工作没有涵盖该研究领域常用的数据集。
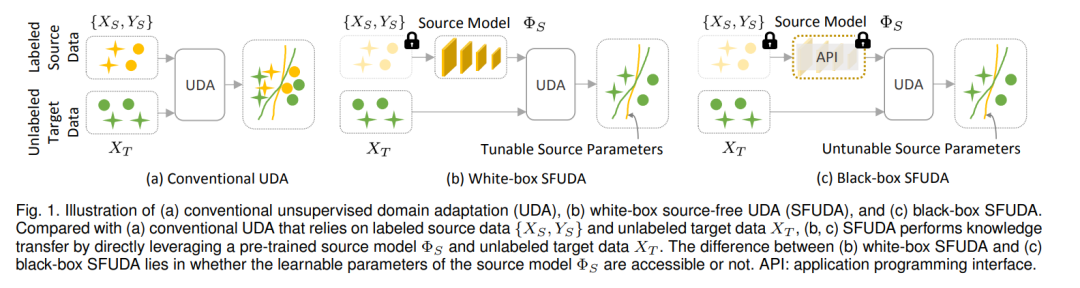
为了填补这一空白,本文对现有的无源无监督领域自适应深度学习研究进行了及时而全面的文献综述。我们的目标是覆盖过去几年的SFUDA研究,并提供一个详细和系统的SFUDA分类。具体而言,将现有的SFUDA方法分为两大类:(1)白盒SFUDA,如图1 (b)所示;(2)黑盒SFUDA,如图1 (c)所示。它们之间的区别在于预训练源模型的模型参数是否可用。根据它们使用的不同学习策略,我们进一步将白盒和黑盒SFUDA方法细分为更细的类别,总体分类如图2所示。讨论了每个类别中方法的挑战和见解,对白盒和黑盒SFUDA方法进行了全面的比较,总结了该领域常用的数据集以及提高不同领域模型泛化能力的流行技术。需要指出的是,SFUDA仍处于蓬勃发展中,因此我们进一步讨论了面临的主要挑战,并提出了未来可能的发展方向。

**本综述的其余部分组织如下。**第2节和第3节分别回顾了现有的白盒和黑盒SFUDA方法。在第4节中,我们比较了白盒和黑盒SFUDA,并提出了提高模型泛化性的有用策略。第5节讨论了现有研究面临的挑战和未来的研究方向。最后,在第6节对本文进行总结。2. 白盒与黑盒无源无监督域自适应将ΦS表示为经过标记的源域{XS, YS}训练好的源模型,其中XS和YS分别表示源数据和相应的标签信息。将{XT}表示为只有目标样本XT的未标记目标域。SFUDA的目标是学习一个目标模型ΦT,以改进基于预训练的源模型ΦS和未标记的目标数据XT的目标推理。在白盒无源域自适应设置中,源数据(即XS和YS)无法访问,但源模型ΦS的训练参数可用。如图2中上所示,现有的SFUDA白盒研究可分为两类: 数据生成方法(Data Generation Method)和模型微调方法(Model Fine-Tuning Method)。与白盒方法不同的是,在黑盒无源域适应的设置下,源数据{XS, YS}和源模型的详细参数ΦS都是不可访问的。只有来自源模型ΦS的目标数据XT的硬模型或软模型预测用于域适应。根据黑盒预测器的使用,现有的黑盒SFUDA研究主要可以分为三类:自监督知识蒸馏、伪标签去噪和生成分布对齐方法,
通过比较现有的白盒和黑盒SFUDA方法,我们有以下有趣的观察。
- 与无法访问任何源参数的黑盒SFUDA相比,白盒SFUDA能够挖掘更多的源知识(如批量统计信息),从而促进更有效的领域适应。
= 白盒SFUDA方法可能存在数据隐私泄露问题[118]。例如,Yin等人[190]揭示,可以通过深度反演技术根据源图像分布恢复原始数据。使用隶属度推断攻击策略[191]、[192],可以推断给定样本是否存在于训练数据集中,从而泄露隐私信息。黑盒SFUDA可以保护数据隐私,因为只有应用程序编程接口(API)是可访问的,而详细的模型权重被保留,但可能会受到跨域适应的性能下降。
-
大多数白盒SFUDA方法假设模型架构在源域和目标域之间是共享的,而黑盒SFUDA方法试图设计特定于任务的目标模型进行知识迁移。黑盒SFUDA方法中这种灵活的模型设计对于计算资源较少的目标用户非常有用,因为他们可以设计更高效和轻量级的目标模型进行域适应。
-
黑箱SFUDA方法既不需要数据合成也不需要模型微调,这有助于加速模型训练的收敛过程。相比之下,白盒方法通常是计算密集型和耗时的。例如,有报道称一种黑盒SFUDA方法[126]的计算量为0.83s,而两种竞争的白盒方法的计算量分别为3.17s[94]和22.43s[193],反映了黑盒SFUDA的计算效率。
总之,在使用白盒和黑盒SFUDA方法时,我们必须在获得更好的性能、保护机密信息和减少计算和内存成本之间进行权衡。
[1] A. Voulodimos, N. Doulamis, A. Doulamis, and E. Protopapadakis, “Deep learning for computer vision: A brief review,”Computational Intelligence and Neuroscience, vol. 2018, 2018. [2] M. Hassaballah and A. I. Awad, Deep learning in computer vision: Principles and applications. CRC Press, 2020. [3] D. Shen, G. Wu, and H.-I. Suk, “Deep learning in medical image analysis,” Annual Review of Biomedical Engineering, vol. 19, p. 221,2017. [4] G. Litjens, T. Kooi, B. E. Bejnordi, A. A. A. Setio, F. Ciompi,M. Ghafoorian, J. A. Van Der Laak, B. Van Ginneken, and C. I.Sanchez, “A survey on deep learning in medical image analysis,” ´ Medical Image Analysis, vol. 42, pp. 60–88, 2017.