虽然在许多领域生成并提供了大量未标记数据,但对自动理解可视化数据的需求比以往任何时候都要高。大多数现有的机器学习模型通常依赖于大量带标签的训练数据来实现高性能。不幸的是,这样的需求在真实的应用中无法满足。标签的数量是有限的,手动注释数据是昂贵和耗时的。通常需要将知识从现有的标记领域迁移到新的领域。然而,模型性能会因为域之间的差异而降低(域移位或数据集偏差)。为了克服标注的负担,领域适应(Domain Adaptation, DA)旨在缓解知识从一个领域转移到另一个相似但不同的领域时的领域转移问题。无监督DA (UDA)处理有标记的源域和无标记的目标域。UDA的主要目标是减少带标签源数据和未带标签目标数据之间的域差异,并在训练过程中学习跨两个域的域不变表示。本文首先定义了UDA问题。其次,我们从传统方法和基于深度学习的方法两方面概述了用于不同类别UDA的最新方法。最后,我们收集了常用的基准数据集,并报告了UDA在视觉识别问题上的最新方法的结果。
https://www.zhuanzhi.ai/paper/a3132aabda946e6540ff6c1a9b745303
在这个大数据时代,产生了大量的文本、图像、声音和其他类型的数据。工业和研究团体对多媒体数据的自动分类、分割和回归有很大的需求[1;2) 1。监督学习是机器学习中最普遍的一种,在不同的应用领域都取得了很大的成功。近年来,我们已经见证了深度神经网络在一些标准基准如ImageNet[4]和CIFAR-10[5]上取得的巨大成功。然而,在现实世界中,我们经常遇到一个严重的问题,即缺乏用于训练的标记数据。众所周知,机器学习模型的训练和更新依赖于数据注释。此外,机器学习模型的高性能依赖于大量带标签的训练数据的存在。不幸的是,在许多实际场景中,这样的要求无法满足,因为收集的数据有限制或没有标签。此外,一个主要的假设是训练和测试数据具有相同的分布。如果背景、质量或形状变形在不同的域之间是不同的,那么这样的假设很容易被扭曲。此外,手动注释数据通常非常耗时且昂贵。这给正确训练和更新机器学习模型带来了挑战。因此,一些应用领域由于没有足够的标注数据进行训练而没有得到很好的发展。因此,常常需要将知识从一个已有的标签领域转移到一个相似但不同的、有限或没有标签的领域。
然而,由于数据偏置或区域移位的现象6,机器学习模型并不能很好地从一个现有的域推广到一个新的无标记域。对于传统的机器学习方法,我们通常假设训练数据(源域)和测试数据(目标域)来自相同的分布,并从训练数据中优化模型,直接应用到测试数据中进行预测。忽略训练数据和测试数据之间的差异。然而,源域和目标域之间常常存在差异,如果存在域迁移问题,传统方法的性能较低。因此,减轻领域迁移问题对提高模型跨不同领域的性能非常重要。
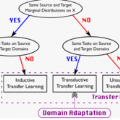
域适应(DA)是迁移学习(TL)的一种特殊设置,其目的是利用丰富的带标签源域的知识,为标签有限或无标签的目标域学习有效的预测器,同时缓解域迁移问题。近年来,DA在计算机视觉领域受到越来越多的关注,如图1所示。每年与DA相关的论文越来越多,说明了DA应用的重要性。有三种类型的DA(有监督的、半监督的和无监督的DA),它们取决于目标域中的标签数量。对于监督DA,所有的目标数据标签都是可用的。对于半监督DA,部分目标数据标签是可用的。对于无监督域适配(UDA),目标域没有标签。为了克服标注不足所带来的限制,技术将有标记的源域和来自目标域的未标记样本结合起来。此外,UDA中源域和目标域的类别数量相同,也称为闭集域适应。
现有的域自适应方法假设源域和目标域的数据分布不同,但共享相同的标签空间。传统的DA方法高度依赖于从原始图像中提取特征。随着深度神经网络的发展,研究人员正在利用更高性能的深度特征(如AlexNet [7], ResNet50 [8], Xception [9], InceptionResNetv2[10])来代替较低级别的SURF特征。然而,传统方法的预测精度受到深度神经网络[11]特征提取质量的影响。近年来,深度神经网络方法在领域适应问题上取得了巨大的成功。特别是,对抗学习在嵌入深度神经网络学习特征表示以最小化源域和目标域之间的差异方面表现出强大的能力[12;13)。但是,它只局限于将现有的解决方案从源域改进到目标域,而目标样本的结构信息很难保存。此外,很难移除目标域中有噪声的预测标签。
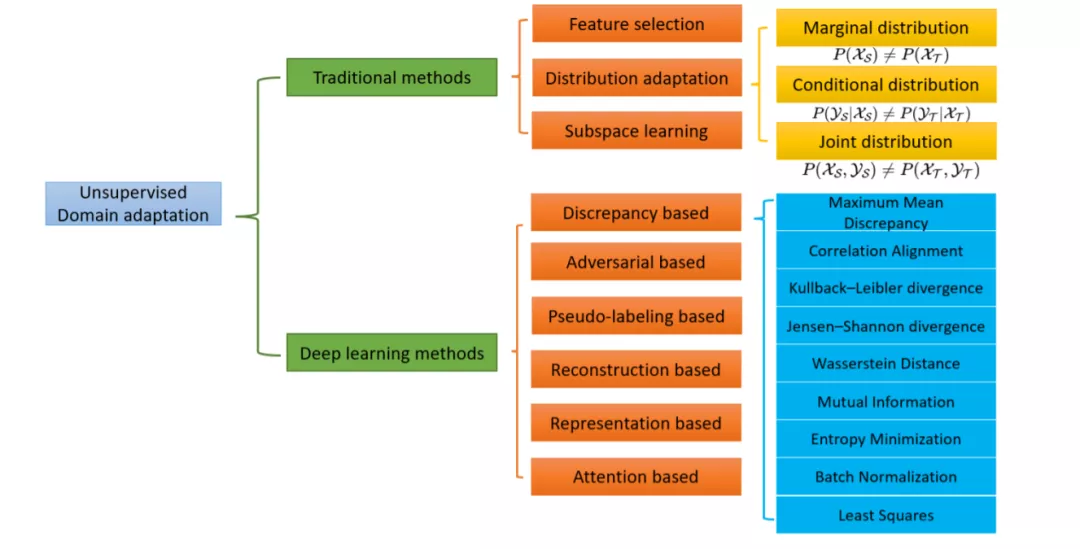
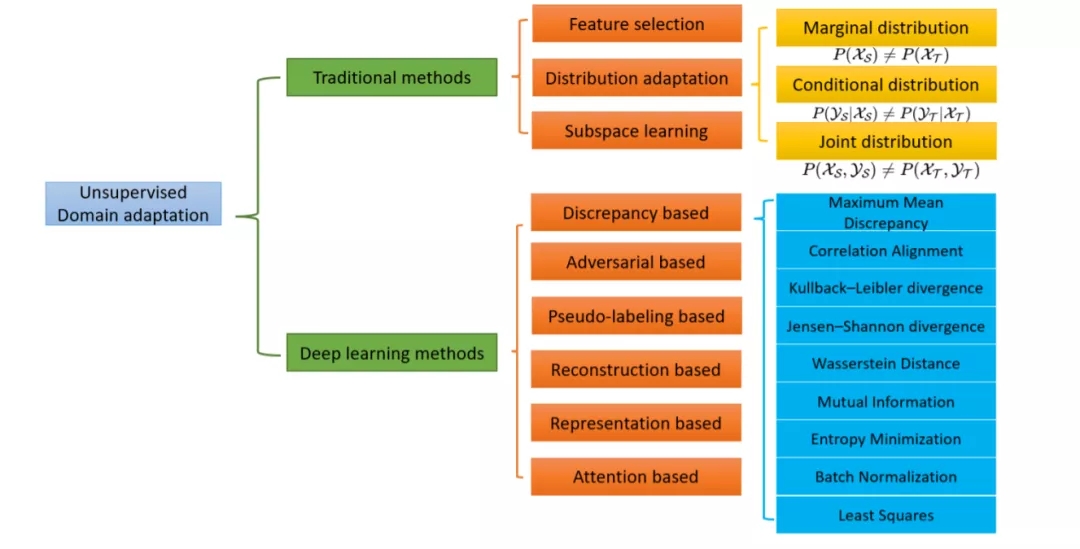
本文主要研究了图像识别中的域自适应问题。本次综述的贡献如下。(i)我们提出了一种基于传统和深度学习的DA分类方法。(ii) 我们是第一个在特征选择、分布适应和子空间学习三种不同背景下研究传统技术的人。(iii)我们还讨论了基于深度学习的方法,包括基于差异的方法、基于对抗的方法、基于伪标签的方法、基于重构的方法、基于表征的方法和基于注意力的方法。(4)我们收集了几个基准数据集,这些数据集在UDA中得到了广泛的应用,并报告了最新方法的结果。本文的其余部分组织如下:在第2、3节中,我们介绍了DA问题的符号和泛化界。在第四部分,我们回顾了传统的UDA方法。在第5节中,我们描述了用于图像识别的深度DA方法。在第6节中,我们列出了DA的基准数据集,并报告了最新方法的准确性。