「机器学习中差分隐私」最新2022进展综述
机器学习中差分隐私的数据共享及发布:技术、应用和挑战

近年来, 基于机器学习的数据分析和数据发布技术成为热点研究方向。与传统数据分析技术相比, 机器学习的优点是能 够精准分析大数据的结构与模式。但是, 基于机器学习的数据分析技术的隐私安全问题日益突出, 机器学习模型泄漏用户训练 集中的隐私信息的事件频频发生, 比如成员推断攻击泄漏机器学习中训练的存在与否, 成员属性攻击泄漏机器学习模型训练集 的隐私属性信息。差分隐私作为传统数据隐私保护的常用技术, 正在试图融入机器学习以保护用户隐私安全。然而, 对隐私安 全、机器学习以及机器学习攻击三种技术的交叉研究较为少见。本文做了以下几个方面的研究: 第一, 调研分析差分隐私技术 的发展历程, 包括常见类型的定义、性质以及实现机制等, 并举例说明差分隐私的多个实现机制的应用场景。初次之外, 还详细 讨论了最新的 Rényi 差分隐私定义和 Moment Accountant 差分隐私的累加技术。其二, 本文详细总结了机器学习领域常见隐私 威胁模型定义、隐私安全攻击实例方式以及差分隐私技术对各种隐私安全攻击的抵抗效果。其三, 以机器学习较为常见的鉴别 模型和生成模型为例, 阐述了差分隐私技术如何应用于保护机器学习模型的技术, 包括差分隐私的随机梯度扰动(DP-SGD)技术 和差分隐私的知识转移(PATE)技术。最后, 本文讨论了面向机器学习的差分隐私机制的若干研究方向及问题。
1 引言
数据分析和发布技术使得数据分析者可以学习 大数据的共有规律。其中, 统计信息分析[1-2]和机器 学习是热门应用领域。然而, 所有的数据分析任务如 不添加合适的隐私保护技术都有可能泄漏个人隐私 信息。这导致如今数据拥有者由于担忧个人隐私泄 漏问题不愿贡献个人数据供第三方使用。欧洲针对 此类问题, 已经出台了《通用数据保护法规》(GDPR) 规定第三方数据使用者有权保护个人隐私。
1.1 隐私保护背景
首先, 本文举例描述数据分析任务场景以及可 能存在的隐私威胁。图 1 为 Adult 公开数据库的片段 截取示例。在 Adult 数据库中, 每一行代表一条个人 (隐私)信息。数据分析者想要分析数据库中所包含的 模式规律。例如, 统计问题“数据库中有多少人的信 息满足属性P?”属性P可以是“年收入超过50K?” 或者“年龄超过 50 岁”, 或者两者的交集。机器学 习二分类任务可以是“基于个人的其他信息预测该 人的年收入是否超过 50K”。
为了在保护数据拥有者的个人信息的同时允许 数据分析者分析数据中暗藏的模式, 传统隐私保护 方式有非交互式和交互式两种。其中匿名化为非交 互式保护方式。匿名化指数据收集者把能表示个人 身份信息的唯一识别号(例如身份证号, 学号, 姓名 等)从原始数据库中去除再发布。然而, Sweeney[3]提 出 87%的美国人可以通过邮编、出生日期和性别这 三个组合属性唯一识别, 这暗示仅仅去除唯一识别 号不足以保护个人身份不被泄漏。随后, Narayanan 和 Shmatikov 提出链接攻击(linkage attack)[4]。该攻击 通过将一个公共数据库的信息链接到私有数据库从 而暴露私有数据库里的隐私属性。为了应对该攻击, k-匿名[3]、l-多样化[5]、t-近似[6]等技术相继提出。但 是, 这些攻击或受到背景知识攻击影响, 或缺少严 谨量化的隐私定义。这些技术假设数据集中的属性 可分类为隐私属性和公共属性。隐私属性需要保护 而公共属性可以公开。但根据后来研究表明[7], 隐私 属性和公共属性并不存在明显的分界, 因为任何属 性组合皆有可能泄漏个人的独有特征规律。这个结 论尤其符合如今的大数据环境。
当非交互式数据发布难以两全个人隐私保护和 数据分析任务时, 交互式问答成为研究者的新方向。然而, 直接回答关于数据库的统计问答也有可能会 泄漏个人隐私, 例如差分攻击。攻击者向某医疗数据 库提问“数据库中有多少人患有癌症?”和“有多少除 了小明的人患有癌症?”可以直接差分出小明是否 患有癌症。
在以上案例场景中, 隐私保护目标是在不违反 个人隐私的条件下允许数据分析者学习群体规律。因此, 如何定义个人隐私泄漏至关重要。从信息论的 角度上分析, 群体规律的学习必然会导致数据分析 者得到更多的信息以猜测个人隐私。例如, 某调查结 果“肺癌和吸烟有紧密关系”必然会增强攻击者猜 测吸烟人群是否患有肺癌的正确概率。在图 1 中, 某机器学习分类器获得 80%的测试集正确率。然后其 预测个人年薪是否超过 50K 的正确率会从原本的 50%提高到 80%(假设 income 属性平衡)。这些情况 是否能称为隐私泄漏?现有的隐私定义难以回答这 类定性问题, 因此需要新的隐私保护定义。

差分隐私(Differential Privacy, DP)定义了“合理 的可否认性”[8], 即某条个人信息是否参与调查, 调 查结果都维持“大致”相同。这等同于保证攻击者 几乎无法察觉某个人的信息是否用于计算调查结果。“大致”是由隐私预算 控制。该参数提供隐私和实 用性的折中。在实际应用中, 差分隐私机制向调查结 果中加入一定量的噪声。噪声的量由隐私预算 和 问题敏感度控制。敏感度度量了两个汉明距离为 1 的数据库回答同一个问题的最大差值。如今, 差分隐私已经成为执行隐私保护的实 际标准。微软[9]、苹果[10]、谷歌[11-12]、美国人口调 查局[13]、哈弗大学 PSI 项目[14]等都通过利用该技术 分析敏感数据。本文旨在分析差分隐私技术在机器 学习领域用于隐私保护的理论与应用。通过剖析差 分隐私与机器学习交叉领域技术, 提出该领域存在 的问题和可能的解决方向。
1.2 相关研究介绍
近年来有以下与差分隐私相关的综述性分析。在这些综述分析中, Dwork 等人[2]首先给出隐私保护 分析中存在的问题以及初步的差分隐私解决方案。Dwork和Roth[15]总结了到2014年为止差分隐私出现 的理论性技术。Sarwate 和 Chaudhuri[7], Ji 等人[16], Goryczka 等人[17]和 Jain 等人[18]分别强调信号处理、 机器学习、多方安全计算、大数据中存在的差分隐 私问题。Zhu 等人[19]介绍了差分隐私的数据共享和分 析, 与本文目标类似。然而近年来, 随着差分隐私技 术及机器学习技术的迅速发展, 许多新的理论突破 和实践层出不穷。因此本文将涵盖更多新发展的技 术和问题。
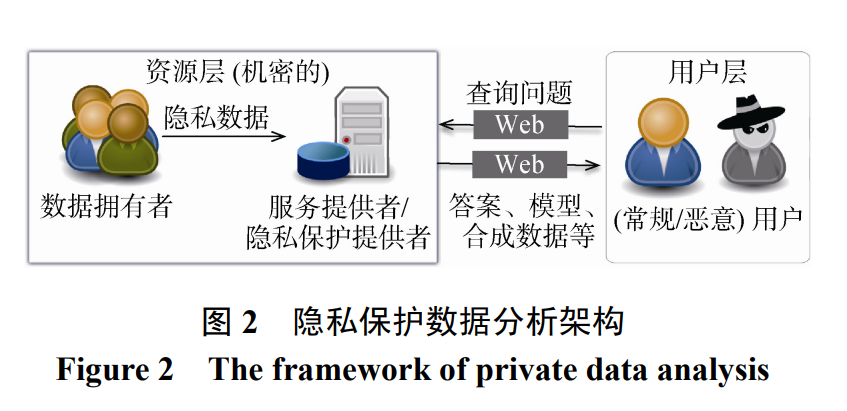
本文旨在帮助读者迅速了解差分隐私的进化发 展历程, 并熟悉差分隐私机制的在机器学习领域的 应用。图 2 给出常见的隐私数据分析场景架构, 其中 数据拥有者提供敏感数据集; 服务提供者, 例如机 器学习服务提供商(Machine Learning as a Service, MLaaS)负责数据分析和以及用户隐私保护; 常规用 户旨在获取查询结果, 同时恶意用户可能成为窃取 隐私信息的攻击者。后文结构如下: 第 2 节介绍差分隐私的定义、实 现机制、常用性质定理; 第 3 节介绍机器学习领域热 门的威胁模型、攻击以及与差分隐私的联系; 第 4节介绍差分隐私机制在机器学习中两种热门模型: 鉴别模型 (discriminative model) 以及生成模型 (generative model)中的运用; 第 5 节总结差分隐私在 机器学习领域应用存在的公开问题和研究方向。
2. 机器学习中的隐私威胁模型与攻击
随着机器学习的深入发展, 深度学习已经成为 寻找数据规律的重要手段。一般的, 机器学习通过建 立模型、优化损失函数来拟合数据。但是, 机器学习 模型如果用来拟合个人敏感数据, 例如医疗数据、人 口普查信息、学校数据、银行数据等, 会对个人隐私 保护提出挑战。当攻击者获取机器学习模型后, 模型 输出特性可能泄漏训练数据的隐私信息。例如某个 人的信息是否存在于隐私数据集中(成员猜测攻击), 或者猜测某个人的隐私属性(属性猜测攻击)。
2.1 隐私威胁模型
讨论攻击之前, 首先需要定义威胁模型。威胁模 型可以用来度量攻击者能力及其抵抗方法的有效性。具体包括以下三个方面: 攻击者的目标、知识和能力。攻击者的目标根据不同攻击类型有所不同, 我们将 在 2.2 节详述。攻击者的知识和能力在机器学习领域 主要体现在以下两个方面: 模型知识和数据集知识。
模型知识: 白盒子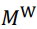
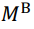
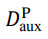
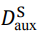
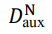
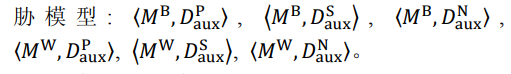
2.2 隐私威胁攻击
常见的在机器学习领域与隐私保护(privacy protection)相关的攻击分为以下几类: 成员猜测攻击 (membership inference attack), 模型反演攻击(model inversion attacks), 属性猜测攻击(attribute inference attack), 模型窃取攻击(model stealing attack), 无意识 记忆(unintended memorization)。值得注意的是, 对抗 样本攻击(adversarial samples)[31]是另一类较为热门 的威胁到机器学习模型安全的议题, 但是属于模型 安全领域(model security), 与隐私保护无关, 因此不 在本文讨论范围内。
3.3 差分隐私抵抗机制
差分隐私机制从定义上防止成员猜测攻击, 模 型记忆, 并弱化属性猜测攻击。但是, 其对模型反演 攻击和模型窃取攻击的弱化效果不明显。具体可参 考 Liu 等人[38]的研究。表 4 总结了以上提到的五种 攻击以及差分隐私对它们的抵抗能力。
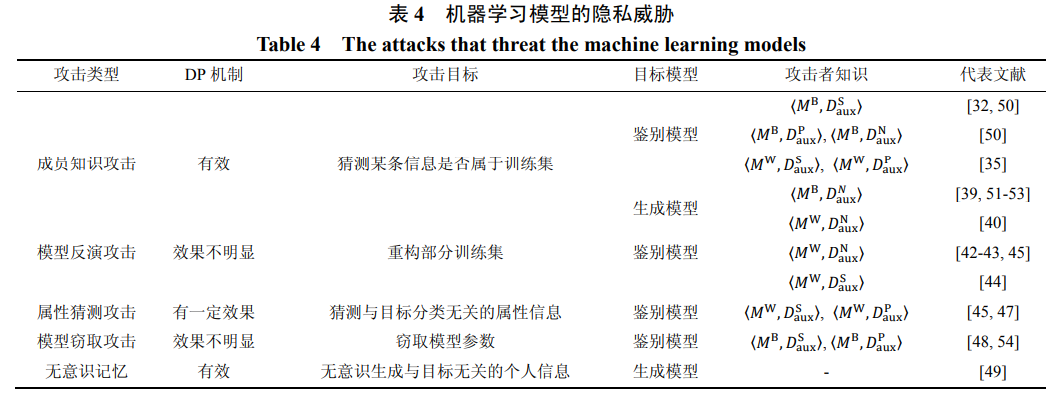
为了能够尽量减少对机器学习可用性的影响, 不修改模型结构及损失函数, 主流差分隐私抵抗机 制研究分为梯度扰动(gradient perturbation)[55, 26]和知 识转移(knowledge transfer)[57-58]两种差分隐私方案。梯度扰动旨在修改训练过程中的梯度更新算法, 在 每个迭代周期的随机梯度递减算法结果中添加差分 隐私噪声。知识转移机制基于采样和聚合架构 (Sample and Aggregate Framework, SAF), 将非隐私 的学生模型采用差分隐私机制聚合出一个满足差分 隐私机制的老师模型然后发布。第 4 节将详细描述 目标/输出/梯度扰动和知识转移两种差分隐私技术 在鉴别模型和生成模型中的运用。
3. 机器学习中的差分隐私方法
鉴别模型主要指的是分类器模型, 即给予目标 属性, 模型判断其属于哪个类别。鉴别模型在机器学 习任务中应用广泛。生成模型, 本文主要指对抗生成 模型(Generative Adversarial Nets, GAN), 用于生成与 训练集近似分布的人工合成数据集。由于常见的 GAN 分为一个鉴别器(discriminator)和一个生成器(generator)。所以许多针对鉴别模型的差分隐私机制 可以微调以适应 GAN 模型。下文将首先介绍鉴别模 型中的差分隐私机制, 再介绍这些机制如何微调以 保护 GAN 模型。
3.1 鉴别模型
3.1.1 目标扰动和输出扰动机制
机器学习领域, 在早期经验风险最小化(Empirical Risk Minimization, ERM)优化凸函数时, 研究者率先 提出了两种方式: 目标扰动[59-61]和输出扰动[58-59]。其 中 Chauhuri 等人[58]以逻辑回归(logistic regression)为 例, 给出目标扰动和输出扰动的敏感度分析方法。但 是其敏感度分析方法依赖目标函数为强凸函数。随 着神经网络(neural networks)的深入发展, 损失函数 不再是凸函数, 因此依赖强凸函数条件的分析敏感 度的方法不再可行, 隐私保护的方法逐渐转入梯度 扰动[26, 55]。梯度扰动无需损失函数为强凸性。且敏 感度分析可以通过梯度裁剪实现。表 6 总结了 3 种 扰动的实现机制。
3.1.2 梯度扰动机制
随机梯度下降(Stochastic Gradient Decent , SGD) 是目前优化神经网络损失函数的常用方法。它在每 个周期随机采样部分训练集, 计算经验梯度以估计 总体梯度并更新参数。如果损失函数并非强凸(神经 网络中, 一般都不是强凸), 则随机梯度下降会优化 至某个局部最优点。差分隐私的随机梯度扰动(DPSGD)旨在将符合差分隐私规范的噪声添加到每个周 期的经验梯度中, 用扰动的梯度估计更新网络, 以 使得每个周期更新的网络参数都满足差分隐私机制。
3.1.3 知识转移
知识转移方法指的是从一群非隐私保护的老师 模型(teacher ensembles)中以隐私保护的模式把模型 知识转移到一个新的学生模型(student model)中, 使 得学生模型满足隐私保护, 并将学生模型发布给使 用者。其中代表性的案例为 Private Aggregation of Teacher Ensembles (PATE)①[56]。PATE可以看成是SAF 技术[62]在深度学习中的一个实例化应用。PATE 的训 练过程可以分解为两部分: teacher ensembles 训练 (图 3 左侧)和 student model 训练(图 3 右侧)。
3.1.4 DP-SGD VS PATE
对于DP-SGD和PATE两种截然不同的隐私策略,我们从以下三个角度对比其优劣。· 隐私保护: 基于 SAF 技术的 PATE 架构与 DP-SGD 有略微不同的隐私假设。PATE 假设属性࢞及 其分布并非是需要保护的。其保护的是与࢞关联的标 签ݕ的值。拿图 1 举例, PATE 保护其他属性与收入 (income)之间的关联性, 但是并不保护某个人的公共 属性(婚姻状态 marital staturs 等)。该隐私保护对数据 集的假设要强于 DP-SGD, 且并非所有数据集都满 足此要求。例如图 1 中的 Adult 数据集、医疗数据集 等的个人属性也可能也是需要隐私保护的。· 可用性: PATE 天然适合于分布式架构。PATE 无需修改现有模型架构, 但是 DP-SGD 需要修 改梯度下降策略。PATE 只能用于分类任务, 而 DP-SGD 可以应用于线性回归、分类任务、生成任务 等。当用分类准确度来衡量发布的差分隐私架构可 用性时, 在同等隐私预算下, PATE可能优于DP-SGD。这是因为 PATE 从公共分布中获取了更多与分类任 务无关的先验知识。且其用数据相关的隐私分析。· 计算复杂度: 在计算复杂度这一项, DP-SGD 对 比PATE 有优势。一个典型的PATE 模型需要250 个老师 模型才能获取隐私和有效性的较优平衡。除此之外, PATE 如果采用数据相关的隐私预算分析, 计算消耗也很大。
3.2 生成模型
生成模型有多种, 本文专指对抗生成模型 GAN。GAN 有很强的分布模仿能力, 能够生成与原始训练集分 布近似的高纬度数据集。因此许多研究者用其当作天然 的规避隐私保护的方法, 生成并发布合成数据集, 并用 人工合成数据集替代隐私数据集发布使用。但是近年来 研究发现GAN本身并没有严格证明的隐私保护性能, 特 别的, 成员猜测攻击对GAN 也有攻击效果[40, 42-43, 45, 68]。根据第 3 节, 差分隐私机制能够抵抗成员猜测攻击, 因 此研究差分隐私的 GAN 对于隐私保护至关重要。GAN 基本知识: GAN 的基本结构如图 4 所示,
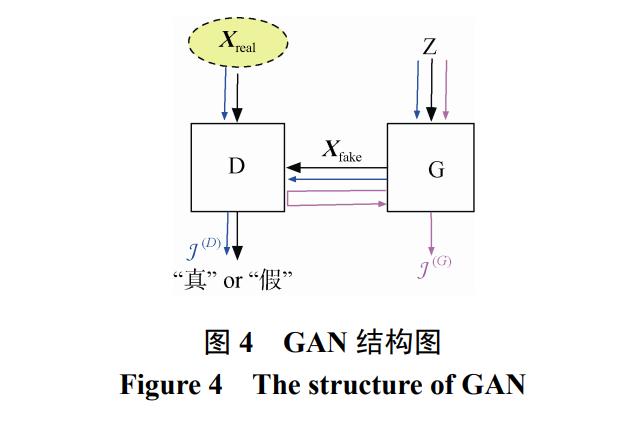
包括一个鉴别器网络(Discriminator)和一个生成器网 络(Generator)。敏感训练集为Xreal。生成器和鉴别器 相互博弈, 生成器要生成更加逼真的数据, 鉴别器 提高鉴别能力以鉴别出人造数据和训练集的区别。两者的损失函数如下。
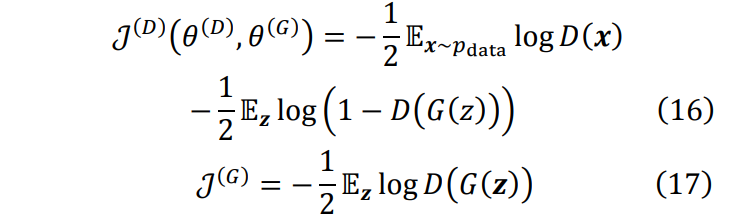
鉴别器和生成器同时优化自己的损失函数, 最 后达到平衡点。从公式(16)(17)以及图 4 中的损失函 数流程可以看出, 只有鉴别器网络 D 的损失函数用 到了敏感训练集Xreal, 生成器网络 G 在训练过程中 没有直接接触敏感数据, 而是使用 D 返回的信息进 行梯度更新。因此只需要保证鉴别器网络的差分隐 私安全, 根据抗后处理定理(定理 4), 生成器的参数 及其输出也可以自动保持差分隐私。值得注意的是, 生成器的输出为人工合成数据集, 因此差分隐私的 GAN 可以用来生成并发布满足差分隐私的合成数 据集。
4 总结和展望
上文详细讨论了差分隐私技术在机器学习领域 的发展历程, 包括定义、实现机制和常用性质。并且 针对实际攻击, 分析并比较了差分隐私的抗攻击能 力。此后, 给出了目前主流的差分隐私的鉴别模型和 生成模型保护方案。本节将讨论差分隐私技术在机 器学习领域的公开问题以及研究方向。
(1) 模型隐私安全和功能性安全存在折中
一直以来, 机器学习模型的隐私安全和功能性 安全处于两个相对平行的研究线路。本文探讨的是 模型的隐私安全, 即模型是否泄漏个人隐私。还有一 类安全指模型的功能性安全, 例如对抗样本攻击、样 本毒化等, 指的是存在恶意攻击者可以用肉眼难以 分辨的数据模型的发生误判。差分隐私目前公认对 模型的隐私安全有一定的保护效果。但是近期许多 研究[69]发现模型的功能性安全可能与隐私安全有对 立性, 即防止模型的功能性安全的措施可能会加重 隐私安全威胁。因此差分隐私如何同模型功能性安 全的抵抗措施有效结合全面防护机器学习的安全性 有待研究。
(2) 差分隐私保护机制不是万能
根据本文表 4 的总结, 差分隐私可以防止成员 猜测攻击和无意识记忆, 对属性猜测攻击有一定弱 化效果。但是对防止模型反演、模型窃取攻击效果 不明显。甚至有研究发现[38], 模型窃取攻击和成员猜 测攻击的成功率是负相关的。差分隐私机制的效果 和攻击原理有直接关系。如果攻击依赖于模型过拟 合, 那么差分隐私有明显效果; 如果攻击不是依赖于模型过拟合, 甚至利用模型的泛化能力, 那么差 分隐私没有直接抗攻击效果。因此依赖差分隐私单 一机制并不能解决机器学习隐私安全的所有攻击, 应考虑多机制结合以全面防护隐私泄漏问题。
(3) 隐私预算追踪方法有待提高
许多研究表示目前针对机器学习的差分隐私机 制牺牲过多有效性以保证安全[30]。另外一些研究也 在试图寻在更加严谨的差分隐私预算追踪方法[70]。例如, 目前的 DP-SGD[26]研究假设攻击者可以获取 机器学习模型每一轮迭代参数(权重更新), 而不仅仅 是可以获取最终训练好的模型的参数。在实际中, 该 攻击条件假设太强, 但是这却是目前唯一一种已知 的分析 DP-SGD 隐私累加的方式[71]。为此, Feldman 等人[70]推导出直接分析最后一轮模型隐私的方法, 但是其证明依赖损失函数是凸函数的假设, 在神经 网络下还没有解决方法。另外, Nasr 等人[71]提出在 不同的攻击者能力下, 应该制定不同的差分隐私下 限。差分隐私一直考虑最恶劣的攻击条件来保护隐 私安全。然而实际环境中很少有攻击者能达到如此 强的攻击能力。因此, 针对不同攻击强度细化不同的 差分隐私下限有待研究。
(4) 联邦学习模式中差分隐私存在局限性
联邦学习通常指掌握自己部分训练集的多方, 在不泄漏个人训练集的前提下, 共同训练综合模型。原理是训练的每个周期, 各方先下载综合模型, 然 后用自己的训练集计算梯度更新并上传, 中心利用 各方上传的梯度加权平均更新综合模型。差分隐私 机制通常类似 SAF(见图 3), 用差分隐私的方式传递 扰动的梯度平均。但是 2017 年 Hitaj 等人[42]研究发 现, 即使是差分隐私保护的联邦学习依然不安全。当 有恶意参与者存在时, 其可以窃取其他合规参与者 的隐私信息。目前还没有可靠的用于联邦学习的差 分隐私机制。这使得目前联邦学习的安全性只能依 赖计算量以及通信量开销巨大的多方安全计算技术 或者是同态加密技术。
(5) GAN 模型中差分隐私存在局限性
差分隐私技术在对抗生成模型(GAN)中的应 用尚在探索阶段。比如, 较为先进的 WGAN-GP[72] 尚没有差分隐私版本。因为梯度惩罚部分用到了真 实训练集, 其隐私预算追踪是个难点。除此之外, 对抗生成模型与鉴别模型的网络架构以及性质也 有所不同。其中, 对抗模型的过拟合程度难以衡量 (差分隐私主要保护模型过拟合) [39, 51]。对抗模型的 随机性可能使得非差分隐私的 GAN 可能天生含有 弱差分隐私性质[72]。因此, 在 GAN 中的差分隐私机制可能需要考虑其特点进行定制。比如, 实验性 衡量原始非隐私保护的 GAN 的隐私保护程度, 再 补充加噪。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“DPML” 就可以获取《「机器学习中差分隐私」最新2022进展综述》专知下载链接