德国蒂宾根大学最新《半监督和无监督深度视觉学习》综述,22页pdf涵盖322篇文献阐述SSL与UL分类
本文从统一的角度对视觉识别领域的半监督学习(SSL)和无监督学习(UL)深度学习算法进行了综述,

最先进的深度学习模型通常使用大量昂贵的标记训练数据进行训练。然而,在有限标签的情况下,需要详尽的人工标注可能会降低模型的泛化能力。半监督学习和无监督学习为从大量无标签视觉数据中学习提供了很有前途的范式。这些范式的最新进展表明,利用未标记数据来改进模型泛化和提供更好的模型初始化具有很大的好处。本文从统一的角度对视觉识别领域的半监督学习(SSL)和无监督学习(UL)深度学习算法进行了综述。为了全面了解这些领域的最新技术,我们提出了一个统一的分类法。我们对现有的代表性SSL和UL进行了全面而深刻的分析,突出了它们在不同的学习场景和不同的计算机视觉任务中的应用的设计原理。最后,我们讨论了SSL和UL的新兴趋势和公开挑战,以阐明未来的关键研究方向。
https://www.zhuanzhi.ai/paper/8f7472afa6b686ae45998a4f31d35ee6
在过去的十年中,深度学习算法和架构[1],[2]一直在推动各种各样的计算机视觉任务的SOTA水平,从目标识别[3],检索[4],检测[5],分割[6]。为了达到人类水平的性能,深度学习模型通常是通过监督训练在大量标记训练数据上构建的。然而,手动收集大规模标记训练集不仅昂贵和耗时,而且可能由于隐私、安全和道德限制而被法律禁止。此外,有监督深度学习模型倾向于记忆标记数据并加入注释者的偏见,这削弱了其在实践中对新场景的泛化,这些场景中数据分布不可见。
更便宜的成像技术和更方便的网络数据访问,使得获取大量未标记的视觉数据不再具有挑战性。因此,从未标记的数据中学习成为一种自然且有希望的方法来将模型扩展到实际场景中,在这种情况下,无法收集一个大的标记训练集,该训练集涵盖了由不同场景、相机位置、一天中的时间和天气条件引起的照明、视角、分辨率、遮挡和背景杂波等所有类型的视觉变化。半监督学习[7],[8]和无监督学习[9],[10],[11],[12]是两种最具代表性的利用非标记数据的范例。这些范式建立在不同的假设基础上,通常是独立开发的,同时具有相同的目标,即学习使用未标记数据的更强大的表示和模型。
更便宜的成像技术和更方便的网络数据访问,使得获取大量未标记的视觉数据不再具有挑战性。因此,从未标记的数据中学习成为一种自然且有希望的方法来将模型扩展到实际场景中,在这种情况下,无法收集一个大的标记训练集,该训练集涵盖了由不同场景、相机位置、一天中的时间和天气条件引起的照明、视角、分辨率、遮挡和背景杂波等所有类型的视觉变化。半监督学习[7],[8]和无监督学习[9],[10],[11],[12]是两种最具代表性的利用非标记数据的范例。这些范式建立在不同的假设基础上,通常是独立开发的,同时具有相同的目标,即学习使用未标记数据的更强大的表示和模型。
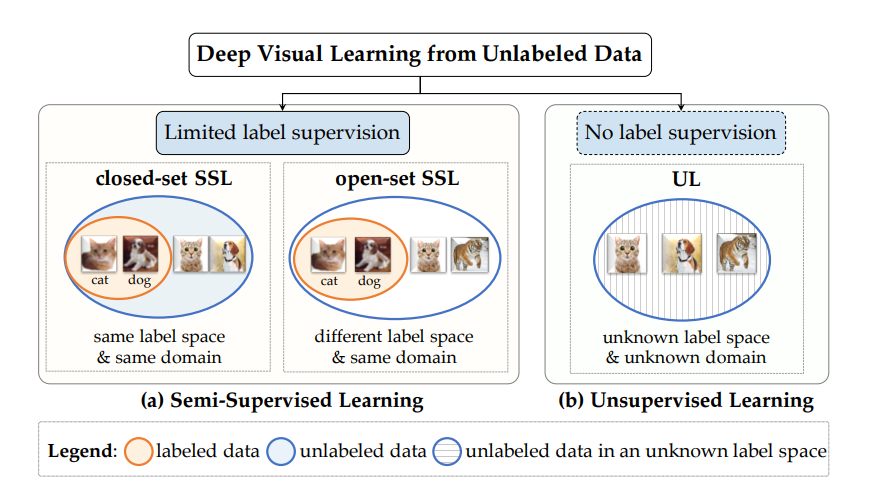
半监督和无监督学习范式的概述——两者都旨在从未标记的数据中学习。
-
(a) 半监督学习(SSL)旨在共同学习稀疏标记数据和大量辅助无标记数据,这些数据通常来自与标记数据相同的底层数据分布。在标准的封闭集SSL[8]、[13]中,标记数据和未标记数据属于来自同一域的同一组类。在开放集SSL[14]、[15]中,它们可能不在同一个标签空间中,也就是说,未标记的数据可能包含未知和/或错误标记的类。 -
(b) 无监督学习(UL)旨在仅从无标签数据中学习,而不使用任何与任务相关的标签监督。训练完成后,可以使用标记数据对模型进行微调,以在下游任务[16]中实现更好的模型泛化。
按照上述定义,将已标记数据集和未标记数据集分别表示为Dl和Du。SSL和UL统一的整体学习目标是:
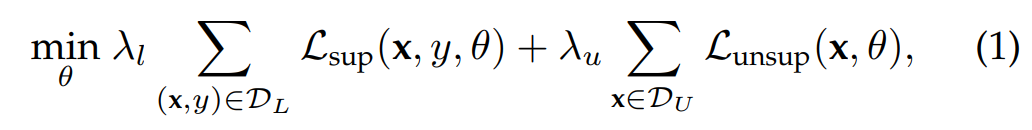

无监督学习分类
现有的无监督深度学习模型主要可以分为三大类: 前置任务、判别模型和生成模型(表2)。前置任务和判别模型也被称为自监督学习,它们通过代理协议/任务驱动模型学习,并构建伪标签监督来制定无监督代理损失。生成模型本质上是无监督的,并且明确地对数据分布建模,以学习没有标签监督的表示。我们在§3.2.1、§3.2.2和§3.2.3中回顾了这些模型。

专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“SS22” 就可以获取《德国蒂宾根大学最新《半监督和无监督深度视觉学习》综述,22页pdf涵盖322篇文献阐述SSL与UL分类》专知下载链接





