【综述】迁移自适应学习十年进展
【导读】迁移学习(Transfer Learning, TL)和域自适应(Domain Adaptation, DA)作为近年来的研究热点,受到了广泛关注,每年在各大会议上都有大量的相关文章发表。目前,关于迁移学习和域自适应的相关研究已经出现了很多综述,在这篇论文中,重庆大学张磊教授(本文的唯一作者)使用一个通用的名字迁移自适应学习(Transfer Adaptation Learning , TAL)来统一TL和DA,综述了近十年来在迁移自适应学习方法和潜在基准方面的研究进展,也指出当前迁移学习一个悬而未决的问题是,对于给定的应用场景,我们何时需要进行迁移自适应学习?跨域是否发生的基本分析条件仍不清楚。此外,还收集并总结了12个处理多个跨域识别任务的视觉benchmark,以帮助研究人员了解迁移自适应学习目标所要处理的任务和场景,并且提出了迁移自适应学习的一些未来研究方向供参考。
专知以前发布过迁移学习综述报道:
中科院发布最新迁移学习综述论文,带你全面了解40种迁移学习方法
题目:Transfer Adaptation Learning: A Decade Survey
作者:Lei Zhang
个人主页:http://www.leizhang.tk/

【摘要】我们看到的世界是不断变化的,它总是随着人、事物和环境的变化而变化。域(domain)是指在某一时刻的世界状态。当研究问题需要不同时刻之间的知识对应时,其特征是域迁移自适应。传统的机器学习旨在通过最小化训练数据的正则化经验风险来寻找测试数据风险最小的模型,而训练数据和测试数据具有相似的联合概率分布。迁移自适应学习的目的是通过从语义相关但分布不同的源域学习知识,建立能够执行目标域任务的模型。这是一个越来越有影响力和重要性的充满活力的研究领域。本文综述了近年来在迁移自适应学习方法和潜在基准方面的研究进展,迁移自适应学习的研究人员面临着更广泛的挑战,即,instance re-weighting adaptation, feature adaptation,classifier adaptation,deep network adaptation,和adversarial adaptation,均超出了早期的半监督和无监督情况。这篇工作为研究人员更好地了解和确定该领域的研究现状、挑战和未来方向提供了框架。
参考链接:
https://arxiv.org/abs/1903.04687v1
https://www.zhuanzhi.ai/paper/95fb2fb53abc78604a6c7c5b665880c7
请关注专知公众号(点击上方蓝色专知关注)
后台回复“迁移学习综述2” 就可以获取最新论文的下载链接~
引言
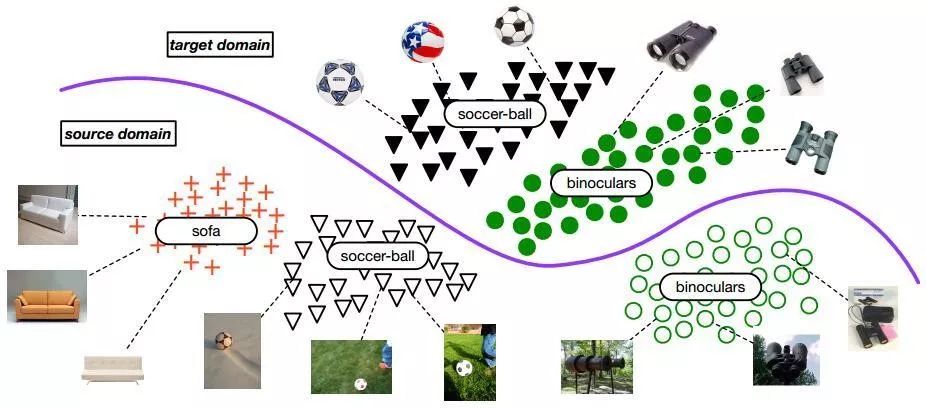
对图像或视频的视觉理解是计算机视觉中一个长期存在且具有挑战性的问题。视觉分类是视觉理解的基础问题,其目的是识别图像所描述的内容。一种固化的视觉分类方法是通过收集图像数据集建立学习模型,将其识别为目标数据。然而,对大量的目标样本进行标识是一种成本-效率低下的方法,耗费大量的人力资源,耗费大量的劳动和时间,几乎是不现实的。因此,利用另一个分布不同但语义相关的源域和足够标记的样本来识别任务样本正成为一个越来越重要的主题。
目前普遍存在的问题是,在计算机视觉中,由于分辨率、光照、视点、背景等因素的影响,源域和目标域之间常常存在分布失配和域偏移[1],[2]。这是由于统计学习中假设的基本独立的相同分布条件不再满足,从而促进了迁移学习(TL)和领域自适应(DA) 的出现[3],[4],[5]。早期,TL假设了不同的联合概率分布,即在源和目标域之间P(X_source,Y_source)≠P(X_target,Y_target),DA假设不同的边际分布,即P(X_source)≠P(X_target) , 但域之间的类别空间相似, 即P(〖Y_source |X〗_source )=P(〖Y_target |X〗_target )
关于迁移学习和领域自适应的相关研究综述有:[4]、[6]、[7]、[8]、[9]、[10]、[11]、[12]、[13]。在这篇论文中,作者使用一个通用的名字迁移自适应学习(Transfer Adaptation Learning , TAL)来统一TL和DA。在过去的十年中,TAL是机器学习社区中的活跃区域,其目标是缩小源数据和目标数据之间的分布差距,以便可以将来自一个或多个相关域的标记源数据用于执行目标域中的任务,如图1所示。
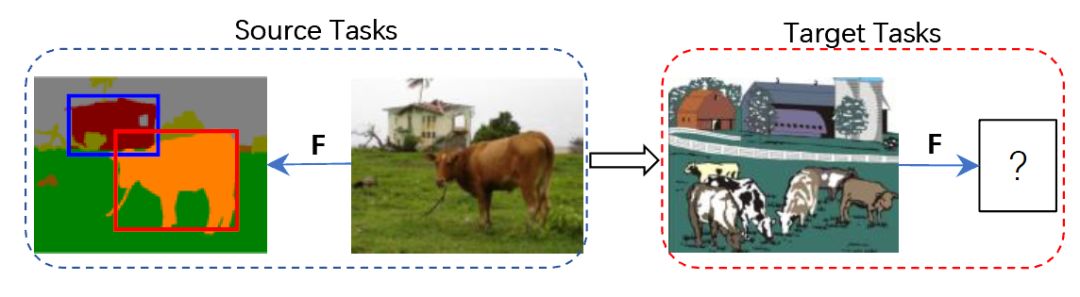
图1 跨域的目标检测、识别和语义分割。F表示在源域中三个任务学习得到的模型
深度学习(DL)技术[14]、[15]、[16]、[17]是近年来在图像分类的特征表示和提取中占据主导地位的强大算法。Fine-tune已成为各种应用中常用的深度模型和框架训练策略,如目标检测[18]、[19]、[20]、[21]、人员再识别[22]、[23]、[24]、医学成像[25]、[26]、[27]、遥感[28], [29], [30], [31]等。在[32]中已经正式探讨了迁移学习挑战的背景以及为什么对表示进行预训练是有用的。
在本文中,我们主要讨论模型驱动的迁移自适应学习的技术进展和面临的挑战。从多个源域学习以迁移或适应新的目标域,为促进模型泛化和理解生物学学习本质提供了可能性。
在过去的十年中,出现了许多迁移学习和领域自适应方法。本文对迁移学习和领域自适应研究领域的挑战和进展进行了综述。我们探讨了迁移自适应学习的五大主要挑战。
—Instance Re-weighting Adaptation。由于域之间的概率分布差异,很自然地可以通过基于非参数方式跨源域数据和目标域数据进行特征分布匹配直接推断实例的重采样权重来解决差异
—Feature Adaptation。为了适应来自多个数据源的数据,通常需要学习投影源域和目标域分布相似的公共特征子空间或表示。
—Classifier Adaptation。在识别来自目标域的实例时,由于域迁移,在源域实例上训练的分类器通常会产生偏差。
—Deep Network Adaptation。深度神经网络具有很强的特征表示能力,并且一般的深度模型建立在单个域上。
—Adversarial Adaptation。对抗学习产生于生成式对抗网络。TL/DA的目标是使源域和目标域在特征空间上更加接近。这就等于混淆了这两个域,使它们不能轻易区别开来。
针对每一项挑战,都将提供迁移自适应学习的最新成果。首先在第二节讨论弱监督学习,然后是迁移自适应学习的技术进步,包括re-weighting adaptation (第三节),feature adaptation (第四节),classifier adaptation (第五节), deep network adaptation (第六节),和adversarial adaptation (第七节)。在第八节中讨论了现有的基准和未来的挑战性任务,在第九节中总结了本文。
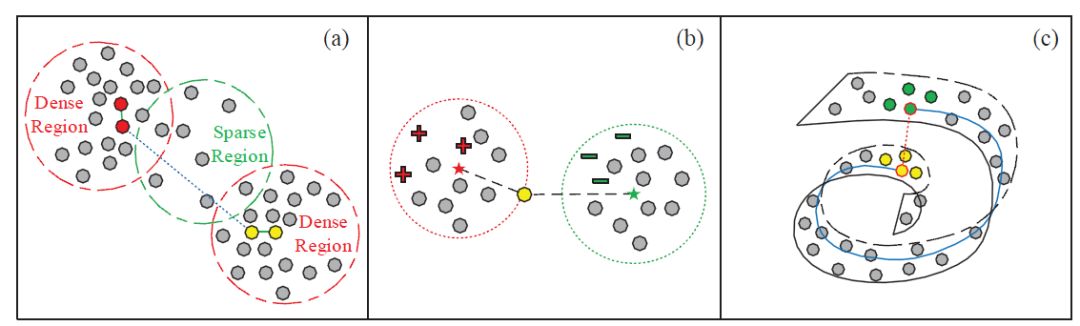
图2. SSL中三个基本假设的图示。 a)平滑假设。 b)聚类假设。c) Manifold的假设。
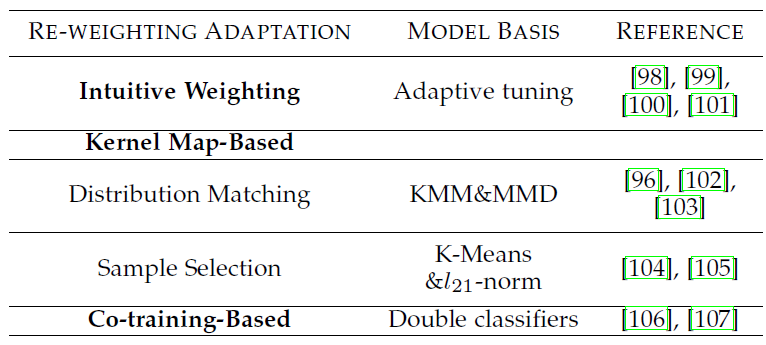
表1 Re-weighting Adaptation方法的分类
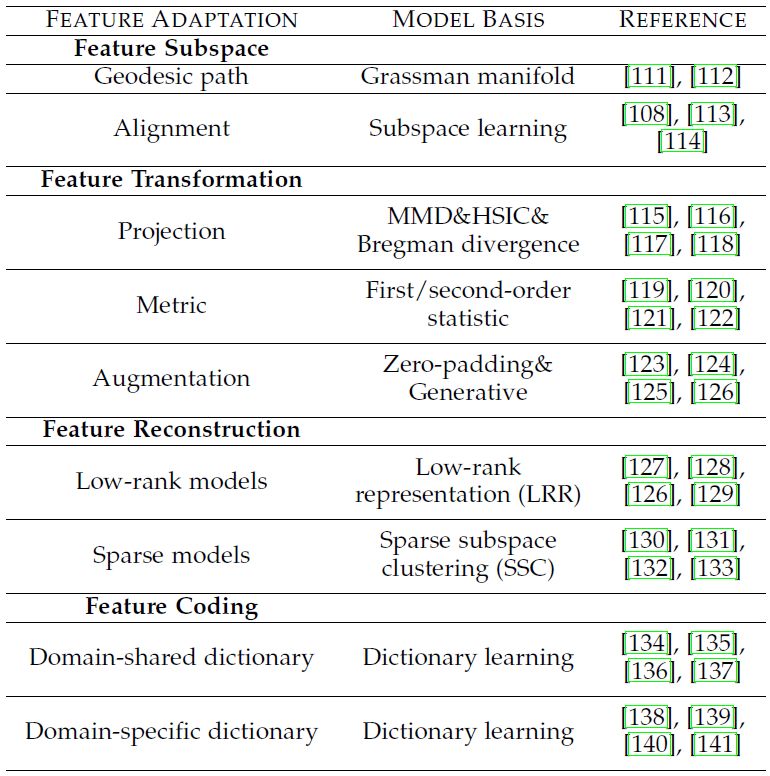
表2 Feature Adaptation的挑战的分类
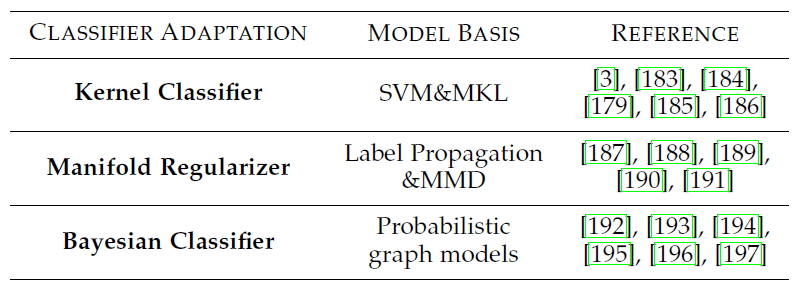
表3 Classifier Adaptation挑战的分类

表4 Deep Network Adaptation挑战的分类
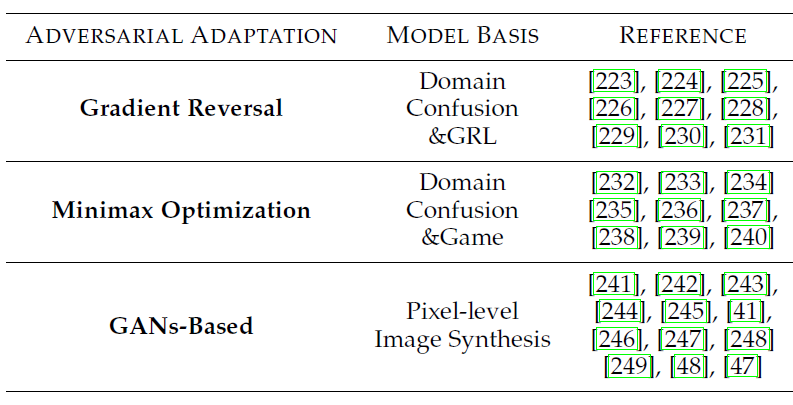
表5 Adversarial Adaptation挑战的分类
在第8节中,论文介绍用于测试TAL模型的基准数据集,以方便读者理解如何开始迁移自适应学习的研究。总共有12个基准数据集,包括Office 31 (3DA) [5], Office+Caltech-10 (4DA) [5], [112], [203], [250], MNIST+USPS [130], [131], Multi-PIE [130], [131], COIL-20 [251], MSRC+VOC2007 [116], IVLSC [252], [253], AwA [254], Cross-dataset Testbed [1], Office Home [255], ImageCLEF [256], and P-A-C-S [252],它们每个都包含至少2个不同的域。
结论
迁移自适应学习是一个充满活力的研究领域,旨在从源域学习域自适应表示和分类器,以表示和识别来自分布不同但语义相关的目标域的样本。本文综述了近十年来迁移自适应学习研究的最新进展,提出了instance re-weighting adaptation, feature adaptation,classifier adaptation,deep network adaptation 和 adversarial adaptation五大技术挑战。此外,收集并总结了12个处理多个跨域识别任务的视觉benchmark,以帮助研究人员了解迁移自适应学习目标所要处理的任务和场景。
当前多个异构域的自适应问题还在研究阶段,此外,还有一个悬而未决的问题是,对于给定的应用场景,我们何时需要进行迁移自适应学习?跨域是否发生的基本分析条件仍不清楚。
原文链接:
https://arxiv.org/abs/1903.04687v1
https://www.zhuanzhi.ai/paper/95fb2fb53abc78604a6c7c5b665880c7
更多关于“迁移学习”的论文知识资料,请登录专知网站www.zhuanzhi.ai,查看:
https://www.zhuanzhi.ai/topic/2001115360986073/vip