联邦学习用于解决数据共享与隐私安全之间的矛盾,旨在通过安全地交互不可逆的信息(如模型参数或梯度更新)来 构建一个联邦模型.然而,联邦学习在模型的本地训练、信息交互、参数传递等过程中依然存在恶意攻击和隐私泄漏的风险,这 给联邦学习的实际应用带来了重大挑战.文中针对联邦学习在建模和部署过程中存在的攻击行为及相应的防御策略进行了详 细调研.首先,简要介绍了联邦学习的基本流程和相关攻防知识;接着,从机密性、可用性和正直性3个角度对联邦学习训练和 部署中的攻击行为进 行 了 分 类,并 梳 理 了 相 关 的 隐 私 窃 取 和 恶 意 攻 击 的 最 新 研 究;然 后,从 防 御 诚 实 但 好 奇 (honestGbutG curious)攻击者和恶意攻击者两个方向对防御方法进行了划分,并分析了不同策略的防御能力;最后,总结了防御方法在联邦学 习实践中存在的问题及可能导致的攻击风险,并探讨了联邦系统的防御策略在未来的发展方向.
大数据和人工智能的快速发展促进了传统产业的变革升 级.以数据驱动的人工智能模型(如深度学习)在计算机视 觉、语音识别、自然语言理解等领域取得了巨大成功,但在海 量数据的准备过程中,往往需要将各个数据源的数据汇聚到 一个中心 的 数 据 仓 库 中.然 而,不 断 出 现 的 数 据 泄 漏 事 件 使得人们开始怀疑中心化收集数据的可靠性.联邦学习在这 种背景下被提出,它旨在利用去中心化的数据源训练一个中 心化的联邦模型,并且在训练的过程中保证原始数据的隐私 安全.联邦学习整体的流程被划分成3个阶段:1)共享模型 分发;2)本地模型训练;3)模型信息收集、聚合与模型更新. 虽然联邦学习针对数据共享与隐私安全的冲突提供了一种全 新的解决方案,但是它仍然面临4个挑战[1]:1)高昂的通信成本;2)系统异质性;3)数据统计异质性;4)数据安全.前三 种挑战被认为是功能性挑战,它们描述了联邦学习在实际应 用过程中可能遇到的困难,而如何处理数据安全问题决定了 联邦学习在应对各种法律条规 (如一般隐私保护条例[2])时 是否具有可行性.在朴素联邦学习框架中,数据的机密性主 要依赖于不可逆的信息无法恢复出原始数据这一假设来保 证.但是文献[3G6]证明了可以从传输的模型信息中推断出 一些隐私数据.成员推断攻击(MembershipInference)最早 在文献[6]中被提出,它旨在利用已训练的模型来判断某一样 本是否属于对应的训练集,这在特定的情况下会泄露隐私信 息,如判断某个病人的临床记录是否被用于训练与某个疾病 相关的分类模型.随着攻击手段的强化,Fredrikson等[7]提 出利用已训练模型的预测置信值进行反转攻击(ModelInverG sion),Hitaj等[8]则在已有工作的基础上将反转攻击拓展到 了多层感 知 神 经 网 络 上,并 利 用 生 成 对 抗 网 络 (Generative AdversarialNetwork,GAN)恢复出特定类别的数字图片.除 了原始数据的隐私安全外,作为各方参与者共同训练的联邦 模型也 被 视 为 参 与 者 的 隐 私 数 据.当 联 邦 模 型 通 过 接 口 (ApplicationProgrammingInterface,API)向外部开放时,原 始的模型参数也存在被窃取的可能[9].
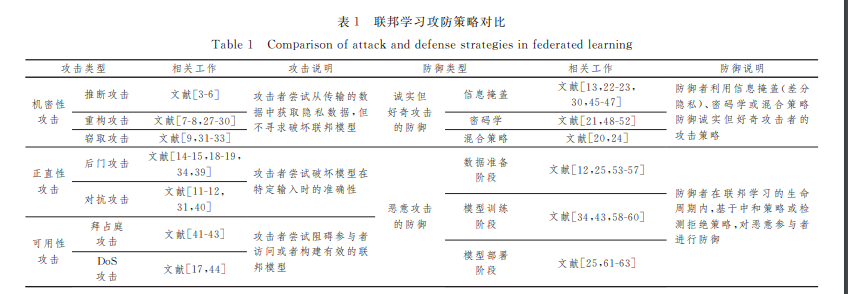
机密性攻击是联邦学习的主要防御方向,但联邦学习的 建模目标是利用多方数据训练出更加精准、健壮的联合模型, 而这样的目标很容易被正直性和可用性攻击危害.关于正直 性和可用性的定义,本文延续了 Papernot等[10]的定义,并根据 联邦学习的场景进行了对应的修正.其中,正直性攻击被定 义为攻击者诱导联合模型在接收特定输入时输出错误结果的 行为;可用性攻击被定义为攻击者阻止参与者构建或访问有 效联合模型的行为.联邦学习场景中的正直性攻击主要分为 两类:对抗攻击[11G12]和后门攻击[13G16].其中,对抗攻 击 旨 在 利用目标模型的弱点构造对抗样本,使 得 目 标 模 型 在 接 收 到对抗样本时输出错误的预测结果;而 后 门 攻 击 旨 在 将 后 门触发器嵌入到目标模型中,从而使目 标 模 型 在 接 收 到 包 含触发标志的 样 本 时 输 出 错 误 的 预 测 结 果.与 正 值 性 攻 击不同,可用性攻击旨在阻止正常参与者构建或访问有效的 联邦模型,如利用拒绝访问(DenialofService,DoS)[17]瘫痪服 务器.
为了应对上述机密性、正直性和可用性攻击,多种防御策 略被提出.这些防御策略根据攻击者的性质被分为两类,即 针对诚实但好奇攻击者的防御策略和针对恶意攻击者(MaliG cious)的防御策略.诚实但好奇攻击者表示该参与者遵守设 定的训练规则,但对传输数据背后的信息感到好奇;而恶意攻 击者则会通过污染数据[18]和模型[19]等手段来破坏目标模型 的正直性和可用性.诚实但好奇攻击者主要针对机密性攻 击,对应的防御手段包括安全多方计算[20]、同态加密[21]、信 息掩盖[22G23]以及混合方案[13,24];而恶意攻击者则针对正直性 攻击和可用性攻击,对应的防御策略分为两类(见表1):利用 中和策略缓解恶意攻击带来的影响[12];对恶意攻击行为进行 检测,并拒绝其参与联合建模[25G26].
综上所述,联邦学习在建模的过程中面临着巨大的数据 安全与模型攻击挑战.文献[64]只对攻防的基础方法进行介 绍,未对联邦学习中的攻防工作进行细致讨 论.而 在 Chen 等[65]的讨论中,未对针对模型可用性的攻击策略(如拜占庭 攻击)进行综述.本文从机密性、正直性和可用性3种攻击性 质出发,重点介绍了联邦学习在建模过程中可能出现的攻击 行为,同时从诚实但好奇和恶意两个角度归纳了不同防御策 略的优点与缺点,攻防策略的对比如表1所列,最后对联邦学 习中攻防场景的发展方向和可能的应用进行了探索与展望.