哈佛医学院等最新《深度无监督领域适应UDA》综述,49页pdf阐述研究UDA进展与展望
来自马萨诸塞州总医院和哈佛医学院等最新深度无监督域自适应综述论文

深度学习已经成为解决不同领域的现实问题的首选方法,部分原因是它能够从数据中学习,并在广泛的应用中取得令人印象深刻的表现。然而,它的成功通常依赖于两个假设: (i) 大量的标记数据集需要精确的模型拟合,(ii) 训练和测试数据是独立的和同分布的。因此,它在不可见的目标域上的性能不能得到保证,特别是在适应阶段遇到非分布数据时。在部署深度神经网络时,目标域数据的性能下降是一个关键问题,它成功地训练了源域数据。针对这一问题,提出了无监督域适应(Unsupervised domain adaptation, UDA),利用标记源域数据和未标记目标域数据在目标域中执行各种任务。UDA在自然图像处理、视频分析、自然语言处理、时间序列数据分析、医学图像分析等方面取得了良好的成果。在这篇综述中,作为一个快速发展的主题,我们提供了一个系统的比较方法和应用。此外,还讨论了UDA与其密切相关的任务,如域泛化和分布外检测之间的联系。此外,指出了目前方法的不足和可能的发展方向。
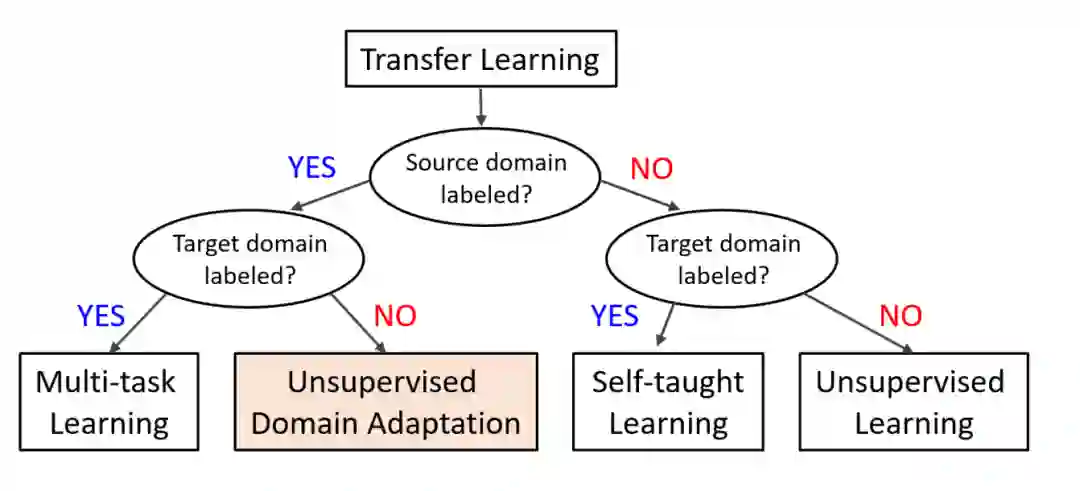
图1 基于源或目标域中标记数据的可用性的迁移学习方法的分类。
深度学习是机器学习的一个子领域,旨在通过层次结构发现输入数据的多层分布式表示(Goodfellow et al., 2016)。在过去的几年里,基于深度学习的方法出现了爆炸式的发展,深度学习大大改善了最先进的方法,以解决各种机器学习问题和应用(LeCun et al., 2015)。特别是,深度学习已经将传统的信号处理方法转变为以端到端方式同时学习特征和预测模型(Bengio et al., 2013)。虽然监督深度学习是各种任务中最普遍和最成功的方法,但它的成功取决于(i)大量的标记训练数据和 (ii) 独立和同分布(i.i.d.) 训练和测试数据集的假设(Huo et al., 2022)。由于对各种应用领域的海量数据集进行可靠的标记通常是昂贵和令人望而却步的,对于目标领域中没有足够的标记数据集的任务,通过利用来自源领域的丰富标记数据,有强烈的需求来应用训练好的模型(Xu and Yan, 2022)。然而,这种学习策略会受到数据分布变化的影响,即源域和目标域之间的域变化(Zhang et al., 2022)。因此,当遇到非分布(OOD)数据时,即源分布与目标分布不同(Che et al., 2021),训练模型的性能可能会严重下降。例如,应用于目标域的种群与源域的种群不同的疾病诊断系统的性能不能得到保证。
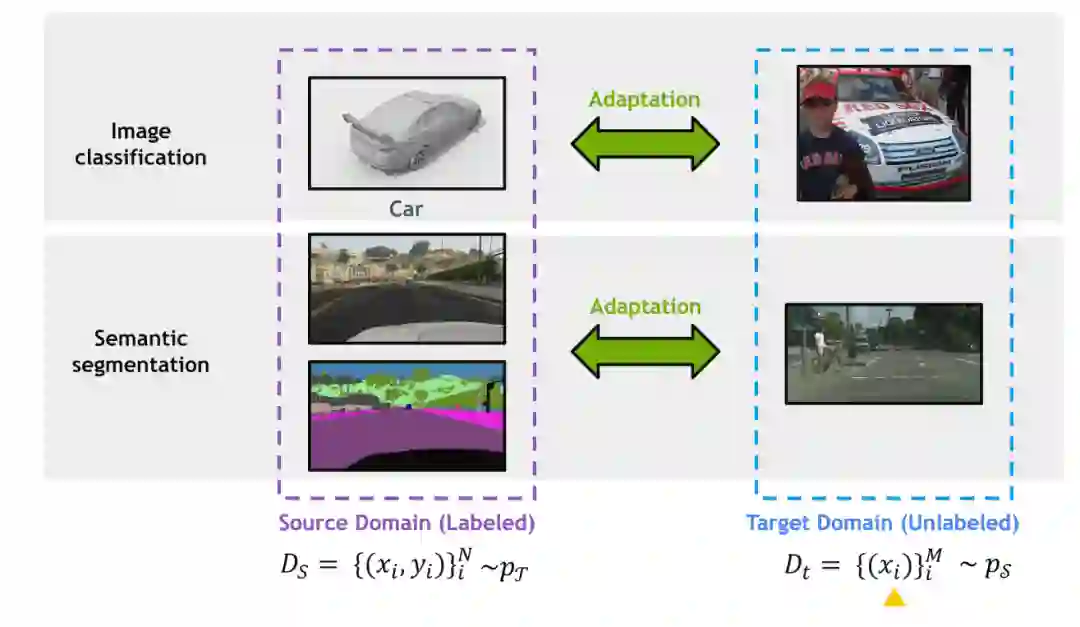
为了应对这一问题,人们提出了无监督域适应(UDA)作为一种可行的解决方案,将从标记源域学到的知识迁移到不可见的、异构的、无标记的目标域(Liu et al., 2021i, 2022g),如图2所示。UDA旨在减轻源和目标域之间的域转移(Kouw, 2018)。UDA的解决方案主要分为统计矩匹配(例如,最大均值差异(MMD) (Long et al., 2018)),域风格转移(Sankaranarayanan et al., 2018),自训练(Zou et al., 2019; Liu et al., 2021e,l)和特征级对抗学习(Ganin et al., 2016; He et al., 2020a,b; Liu et al., 2018)。
已有多篇关于领域适应的综述论文(Beijbom, 2012; Bungum and Gamb¨ack, 2011; Betlehem et al., 2015; Sun et al., 2015; Wang and Deng, 2018; Csurka, 2017; Zhao et al., 2018; Kouw, 2018; Kouw and Loog, 2019; Zhao et al., 2020b; Wilson and Cook, 2020; Ramponi and Plank, 2020),以及更广泛的迁移学习问题(Pan and Yang, 2009; Cook et al., 2013; Lazaric, 2012; Shao et al., 2014; Tan et al., 2018; Zhang et al., 2019b)。如图1所示,域适应可以看作迁移学习的一种特殊情况,假设标记数据只在源域中可用(Pan and Yang, 2009)。在这篇综述论文中,我们的目标是从理论和实践的角度提供广泛的模型和算法。这篇综述还涉及了新兴的方法,特别是那些最近开发的方法,提供了不同技术的全面比较,并讨论了独特的组件和方法与无监督的深度领域适应的联系。在一般迁移学习综述中,UDA的覆盖范围有限,尤其是基于深度学习的UDA。以前许多关于领域适应的综述没有纳入深度学习方法;然而,基于深度学习的方法已经成为UDA的主流。此外,一些评论并没有深入触及域映射(Csurka, 2017;Kouw, 2018;Kouw and Loog, 2019),基于归一化统计的(Csurka, 2017; Kouw and Loog, 2019; Zhao et al., 2018, 2020b),基于ensemble-based (Csurka, 2017; Wang and Deng, 2018; Kouw and Loog, 2019; Zhao et al., 2018),或基于自训练的方法(Wilson和Cook, 2020)。此外,他们中的一些只关注有限的应用领域,如视觉数据分析(Wang and Deng, 2018; Csurka, 2017; Oza et al., 2021)或自然语言处理(NLP) (Ramponi和Plank, 2020年)。本文综述了该技术在自然图像处理、视频分析、自然语言处理、时间序列数据分析、医学图像分析、气候和地球科学等领域的应用前景。表1总结了其他评论论文涉及的主题。

本文的其余部分组织如下。在第二章中,我们首先分析了UDA中可能的域移位。然后,在第3节中讨论了各种最新的UDA方法,并对它们进行了比较。接下来,我们将在第4节展示如何将UDA应用于多个应用领域。在第5部分,我们强调了未来的发展方向。最后,我们在第6节对本文进行总结。
方法
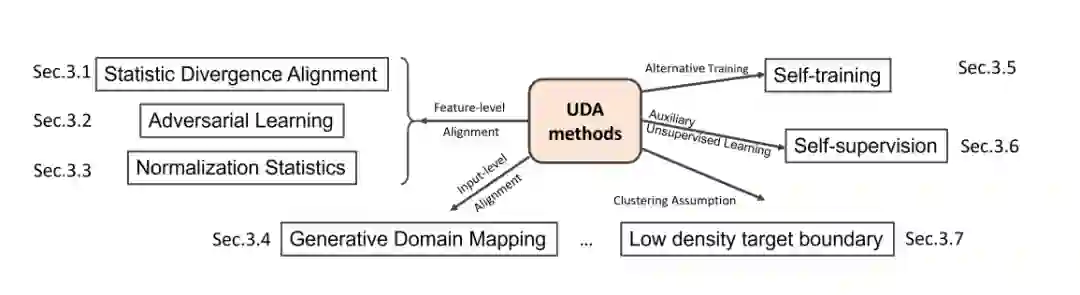
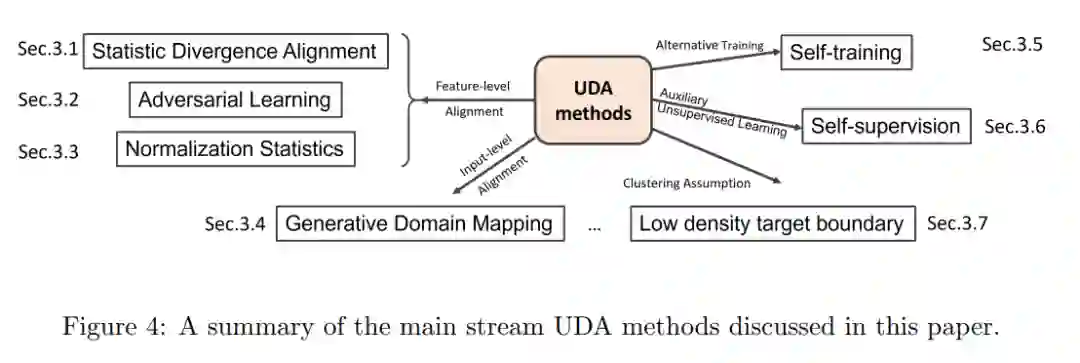
在过去的几年里,随着神经网络研究的快速增长,UDA方法也得到了广泛应用。流行的方法包括统计发散和对抗训练的域比对、生成域映射、归一化统计比对、基于集成的方法和自训练,如图4所示。此外,这些方法可以结合起来进一步提高各种任务的性能。在本节中,我们将更详细地讨论每个类别以及它们的组合和联系。
现实转移假设
学习域不变特征表示是许多深度UDA方法中应用最广泛的思想,其关键在于最小化潜在特征空间中的域差异。为了实现这一目标,选择合适的散度指标是这些方法的核心。广泛使用的测量方法包括MMD (Rozantsev et al., 2018)、相关对齐(CORAL) (Sun et al., 2016)、对比域差异(CDD) (Kang et al., 2019)、Wasserstein距离(Liu et al.,2020b)、图匹配损失(Yan et al.,2016年)等。
对抗学习
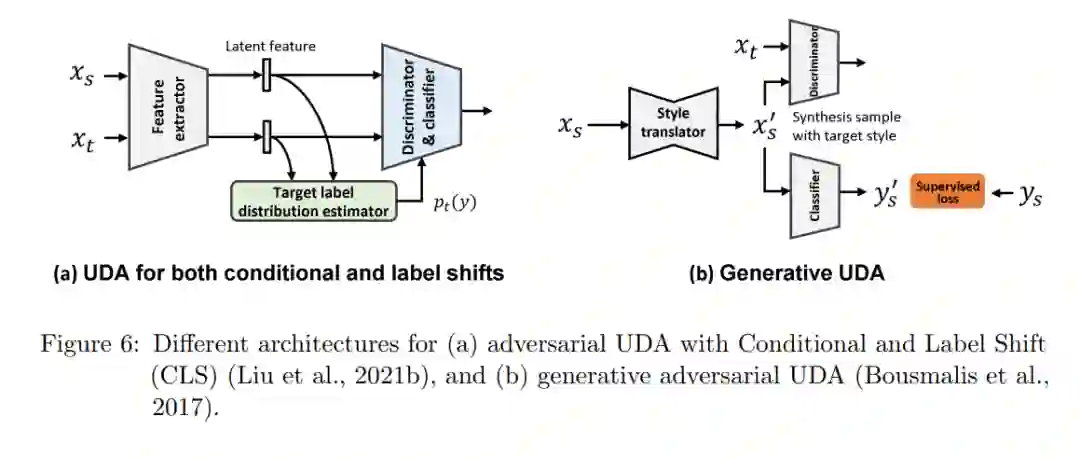
归一化统计
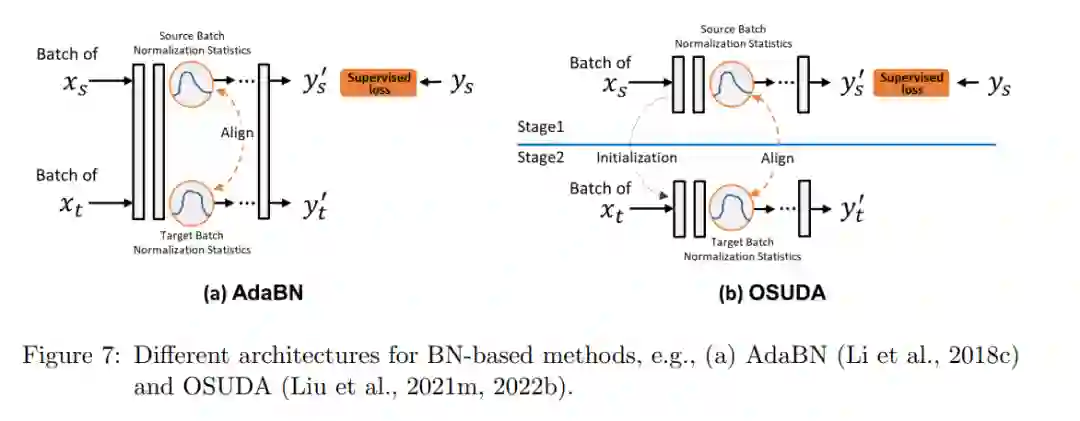
在现代深度神经网络中,由于对初始化不敏感(Santurkar et al., 2018),批处理归一化(BN)层在实现更快的训练(Ioffe and Szegedy, 2015)、更平滑的优化和更稳定的收敛(Santurkar et al., 2018)方面发挥了重要作用。在每个归一层中,有两个低阶批量统计量,包括均值和方差,以及两个可学习的高阶批量统计量,包括尺度和偏差。
生成域映射
与其在潜在空间中对齐特征,还不如直接在数据级呈现目标域数据。分类器或分割网络可以根据源域数据及其标签生成的目标域数据进行训练(Shrivastava et al., 2017)。此外,网络可以与GANs同时训练(Bousmalis et al., 2017; Hoffman et al., 2018),如图6(b)所示。
自训练
与使用发散度来减少域差异的方法不同,自训练被提出作为一种替代训练方案,利用未标记的目标域数据来实现域适应(Zou等,2019)。自训练是基于一种以轮为基础的替代训练计划,该计划最初是为半监督训练而发展的,最近被调整用于UDA。基于UDA的深度自训练包括两个步骤:(1)在目标域内创建一组伪标签,(2)使用目标域数据生成的伪标签对网络进行再训练。
自监督
UDA的另一个解决方案是将辅助自监督任务纳入网络训练。自监督学习只依赖于未标记的数据来规定前置学习任务,如上下文预测或图像旋转,其目标目标可以在没有监督的情况下计算(科列斯尼科夫等人,2019)。这组工作假设可以通过对源域分类和目标域数据进行重构(Ghifary et al., 2016)或源和目标域数据同时进行(Bousmalis et al., 2016)来实现对齐。在Ghifary et al.(2016)中,一个深度重构-分类网络以一对平方重构损失进行优化。特别是在Bousmalis等(2016)中引入尺度不变均方误差重构损失来训练其域分离网络。
应用
UDA已成功应用于各种应用领域,包括图像感知和理解、视频分析、NLP、时间序列数据分析、医学图像分析以及气候和地球科学。虽然一些工作是基于UDA的一般原则,其他工作是针对解决具体的应用考虑,通过利用训练和测试数据集的特点。在这一部分,我们不打算提供一个全面的综述,而是选择突出UDA在各个应用的趋势的例子,考虑到大量的工作和许多优秀的以前的综述。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“DUDA” 就可以获取《哈佛医学院等最新《深度无监督领域适应UDA》综述,49页pdf阐述研究UDA进展与展望》专知下载链接



