Google:数据并行对神经网络训练用时的影响
编者按:谈到加速模型训练,并行计算现在已经成为一个人人可以信手拈来的术语和技巧——通过把单线程转为多线程同时进行,我们可以把训练用时从一礼拜缩短到几天甚至几小时。但无论你有没有尝试过并行训练,你是否思考过这样一些问题:模型训练是否存在一个阈值,当batch size变化到一定程度后,训练所用的步数将不再减少;对于不同模型,这个阈值是否存在巨大差异……

摘要
近年来,硬件的不断发展使数据并行计算成为现实,并为加速神经网络训练提供了解决方案。为了开发下一代加速器,最简单的方法是增加标准minibatch神经网络训练算法中的batch size。在这篇论文中,我们的目标是通过实验表征增加batch size对训练时间的影响,其中衡量训练时间的是到达目标样本外错误时模型所需的训练步骤数。
当batch size增加到一定程度后,模型训练步数不再发生变化。考虑到batch size和训练步骤之间的确切关系对从业者、研究人员和硬件设计师来说都至关重要,我们还研究了不同训练算法、模型和数据记下这种关系的具体变化,并发现了它们之间的巨大差异。在论文最后,我们调整了以往文献中关于batch size是否会影响模型性能的说法,并探讨了论文结果对更快、更好训练神经网络的意义。
研究结果
通过全面定性定量的实验,我们最终得出了以下结论:
1. 实验表明,在测试用的六个不同的神经网络、三种训练算法和七个数据集下,batch size和训练步骤之间关系都具有相同的特征形式。
具体来说,就是对于每个workload(模型、训练算法和数据集),如果我们在刚开始的时候增加batch size,模型所需的训练步骤数确实会按比例逐渐减少,但越到后期,步骤数的减少量就越低,直到最后不再发生变化。与之前那些对元参数做出强有力假设的工作不同,我们的实验严格对照了不同网络、不同算法和不同数据集的变化,这个结论更具普遍性。
2. 我们也发现,最大有用batch size在不同workload上都有差异,而且取决于模型、训练算法和数据集的属性。
相比一般SGD,具有动量的SGD(以及Nesterov动量)的最大有用batch size更大,这意味着未来大家可以研究不同算法和batch size缩放属性之间的关系。
有些模型的最大有用batch size很大,有些则很小,而且它们的这种关系并不像以前论文中介绍的那么简单(比如更宽的模型并不总能更好地扩展到更大的batch size)。
相比神经网络和算法,数据集对最大有用batch size的影响较小,但它的影响方式有些复杂。
3. 我们还发现,训练元参数的最佳值并不总是遵循和batch size的任何简单数学关系。比如近期有一种比较流行的学习率设置方法是直接线性缩放batch size,但我们发现这种方法并不适用于所有问题,也不适用于所有batch size。
4. 最后,通过回顾先前工作中使用的实验方案细节,我们没有找到任何关于增加batch size必然会降低模型性能的证据,但当batch size过大时,额外的正则化确实会变得至关重要。
实验
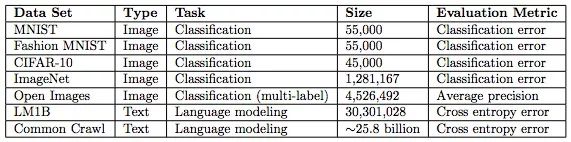
下表是实验采用的数据集,size一栏指的是训练集中的样本数,训练数据分为图像和文本两类。
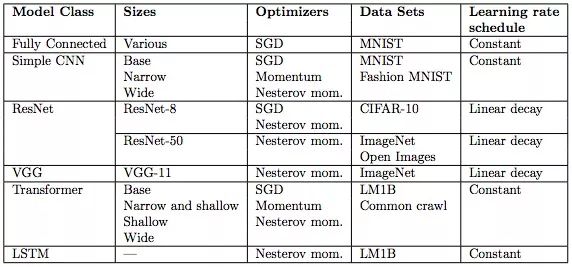
下表是实验用的模型,它们都是从业者会在各类任务中使用的主流模型。表中也展示了我们用于每个模型和数据集的学习率。学习率的作用是加速神经网络训练,但找到最佳学习率本身是一个优化问题。
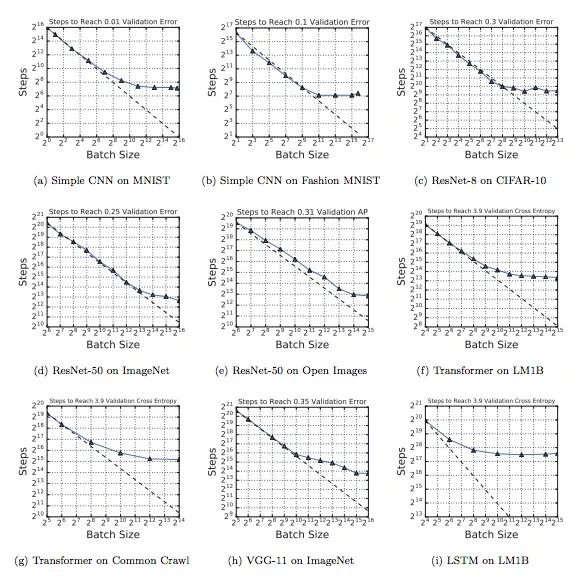
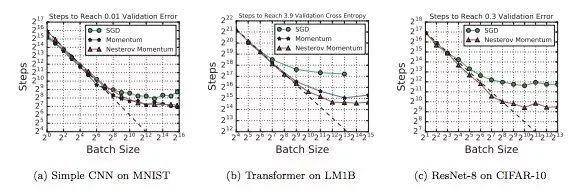
下图展示了不同workload下batch size和训练步骤之间关系变化。可以发现,虽然使用的神经网络、算法和数据集不同,但这九幅图都表现出了同样的特征,就是在初始阶段,随着batch size逐渐增加,训练步骤数会有一段线性递减的区间,紧接着是一个收益递减的区域。最后,当batch size突破最大有用batch size阈值后,训练步数不再明显下降,即便增加并行线程也不行。
下图不同模型下batch size和训练步骤之间关系变化。其中a、b、c三个模型的最大有用batch size比其他模型大得多,d和f表明改变神经网络的深度和宽度可以影响模型利用较大batch size的能力,但这种做法只适用于同模型对比,不能推广到不同模型架构的对比中。
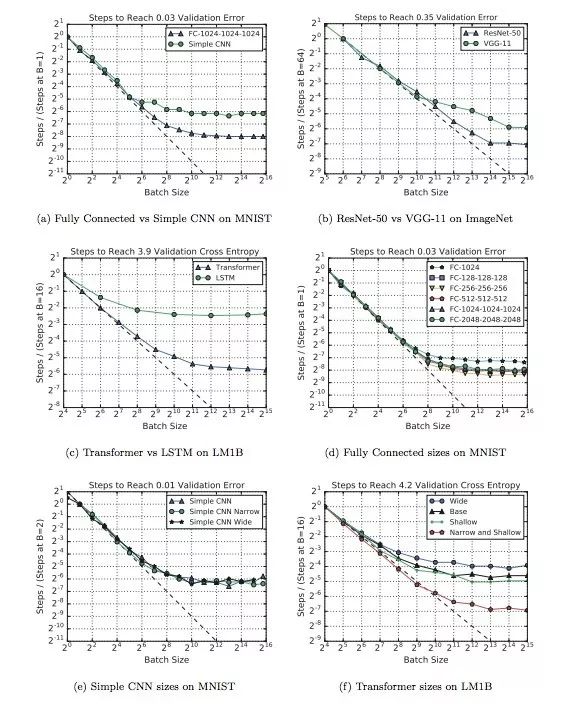
在上图的实验中,MNIST模型用的都是常规的mini-batch SGD,而其他模型则用了Nesterov momentum。经过比较,我们发现Nesterov在处理较大batch size上比mini-batch SGD更好一些,所以这些模型的最大可用batch size也更大。
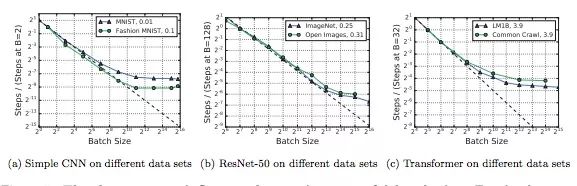
下图显示了不同数据集对batch size和训练步骤之间关系的影响。如图所示,虽然不大,但影响确实是客观存在的,而且非常复杂。比如对于MNIST,子集大小对最大有用batch size的影响几乎为0;但对于ImageNet,子集小一点似乎训练起来更快。
小结
这里我们只呈现了部分实验图表,感兴趣的读者可以阅读原文进行更深入的研究。总而言之,这篇论文带给我们的启示是,尽管增加batch size在短期来看是加速神经网络训练最便捷的方法,但如果我们盲目操作,即便拥有最先进的硬件条件,它在到达阈值后也不会为我们带来额外收益。
当然,这些实验数据也我们发掘了不少优化算法,它们可能能够在许多模型和数据集中始终如一地加速模型训练。
论文地址:arxiv.org/pdf/1811.03600.pdf