ELMo的朋友圈:预训练语言模型真的一枝独秀吗?
选自arXiv
作者:Samuel R. Bowman等
机器之心编译
参与:刘晓坤、思源
自然语言处理的预训练任务该选哪一个?语言模型真的是一种通用的预训练方法吗?这篇论文告诉我们,通用的 NLP 预训练模型是我们想多了。不同的目标任务需要不同的预训练模型,而预训练语言模型甚至会损伤某些任务的性能。不过在没有更好的方案前,预训练语言模型还是最好的选择。
用于自然语言处理任务(如翻译、问答和解析)的最先进模型都具有旨在提取每个输入句子含义和内容表征的组件。这些句子编码器组件通常直接针对目标任务进行训练。这种方法可以在数据丰富的任务上发挥作用,并在一些狭义定义的基准上达到人类水平,但它只适用于少数具有数百万训练数据样本的 NLP 任务。这引起人们对预训练句子编码的兴趣:我们有充分的理由相信,可以利用外部数据和训练信号来有效地预训练这些编码器,因为它们主要用于捕获句子含义而不是任何特定于任务的技能。并且我们已经看到了预训练方法在词嵌入和图像识别相关领域中获得的成功。
更具体地说,最近的四篇论文表明,预训练句子编码器可以在 NLP 任务上获得非常强的性能。首先,McCann 等人 (2017) 表明来自神经机器翻译系统的 BiLSTM 编码器可以在其他地方有效地重用。Howard & Ruder (2018)、Peters 等 (2018)、 Radford 等 (2018) 表明,通过生成式语言建模(LM)以无监督方式预训练的各种编码器也是有效的。然而,每篇论文都使用自己的评估方法,不清楚哪个预训练任务最有效,或者是否可以有效地组合多个预训练任务;在句子到向量编码的相关设置中,使用多个标注数据集的多任务学习已经产生了鲁棒的当前最佳结果。
本文试图系统地解决这些问题。研究者在 17 种不同的预训练任务、几个简单的基线以及这些任务的几种组合上训练可重用的句子编码器,所有这些都使用受 ELMo 扩展的单个模型架构和过程,用于预训练和迁移。然后,研究者根据 GLUE 基准测试中的 9 个目标语言理解任务评估这些编码器,他们共得到了 40 个句子编码器和 360 个已训练模型。然后,研究者测量目标任务的性能相关性,并绘制了评估训练数据量对每个预训练和目标任务的影响的学习曲线。
实验结果表明语言建模是其中最有效的一个预训练任务,预训练期间的多任务学习可以提供进一步的增益,并在固定句子编码器上得到新的当前最佳结果。然而,ELMo 式的预训练也有令人担忧的地方,研究者预训练模型并将其用于目标任务时没有进一步微调,这是脆弱的并且存在严重限制: (i) 一般的基线表征和最好的预训练编码器几乎能达到相同的表现,不同的预训练任务之间的差别可能非常小。(ii) 不同的目标任务在它们受益最多的预训练方面存在显著差异,并且多任务预训练不足以避免这个问题并提供通用的预训练编码器。

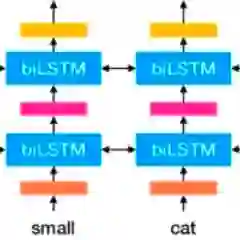
图 1:本研究的通用模型设计:在预训练期间,为每个预训练任务训练共享编码器和任务特定模型。然后,固定共享编码器,并为每个目标评估任务重新训练任务特定模型。任务可能涉及多个句子。
论文:Looking for ELMo's friends: Sentence-Level Pretraining Beyond Language Modeling

论文链接:https://arxiv.org/abs/1812.10860
摘要:关于语境化词表征问题的研究(用于句子理解的可重用神经网络组件的开发),近期最近出现了一系列进展,主要是使用 ELMo 等方法进行语言建模的无监督预训练任务。本文提供了第一个大规模系统研究,比较了在这种背景下不同的预训练任务,既作为语言建模的补充,也作为潜在的替代方案。该研究的主要结果支持使用语言建模作为预训练任务,并在使用语言模型进行多任务学习的可比模型中得到了新的当前最佳结果。然而,仔细观察这些结果可以发现跨目标任务中的模型性能出现了令人担忧的变化,这表明广泛使用的预训练和冻结句子编码器的范式可能不是进一步研究的理想基础。
表 1 展示了我们所有预训练编码器在 GLUE 开发集上的结果,每个编码器有或者没有使用预训练的 ELMo BiLSTM 层(上标 E)。N/A 基线是具有随机初始化的未经训练的编码器。Single-Task 基线是来自 9 个 GLUE 的结果的聚合:给定 GLUE 任务的该行中的结果使用仅在该任务上预训练的编码器。为了与其他结果保持一致,我们将预训练任务和目标任务视为所有情况下的两个单独任务(包括此处),并为它们提供独立的任务特定参数,尽管它们使用相同的数据。我们使用上标 S 和 C 分别表示 Reddit 任务的 Seq2Seq 和分类两个变体。
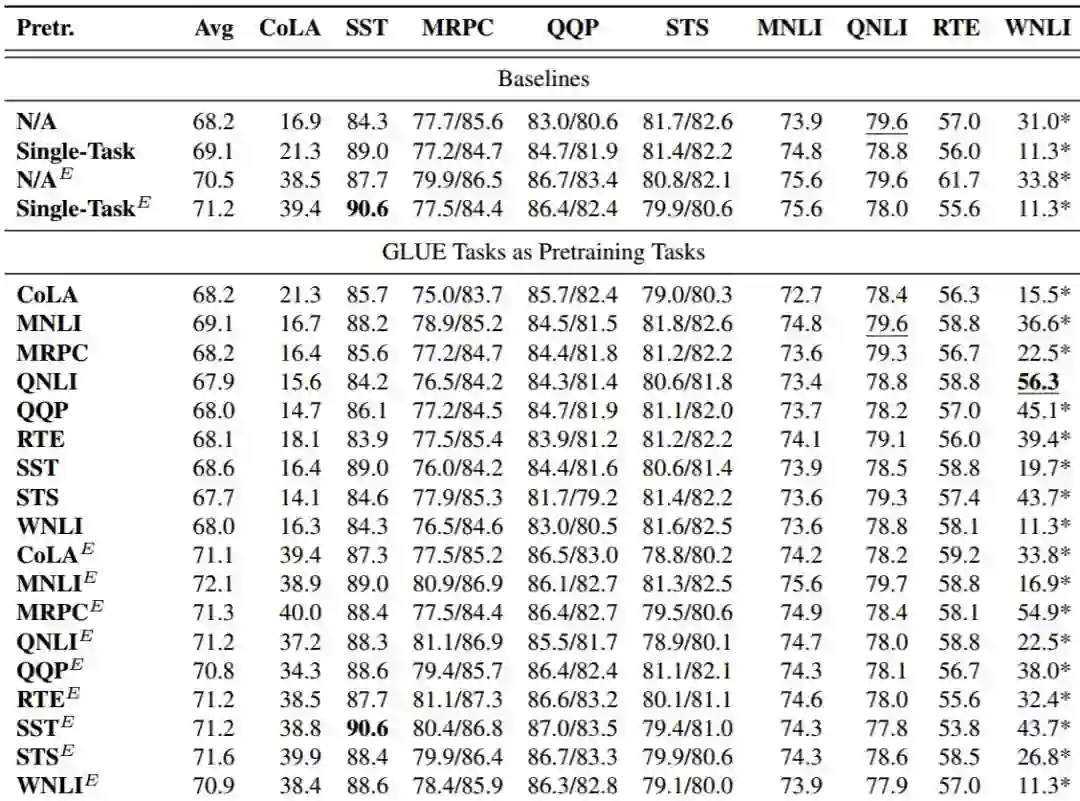
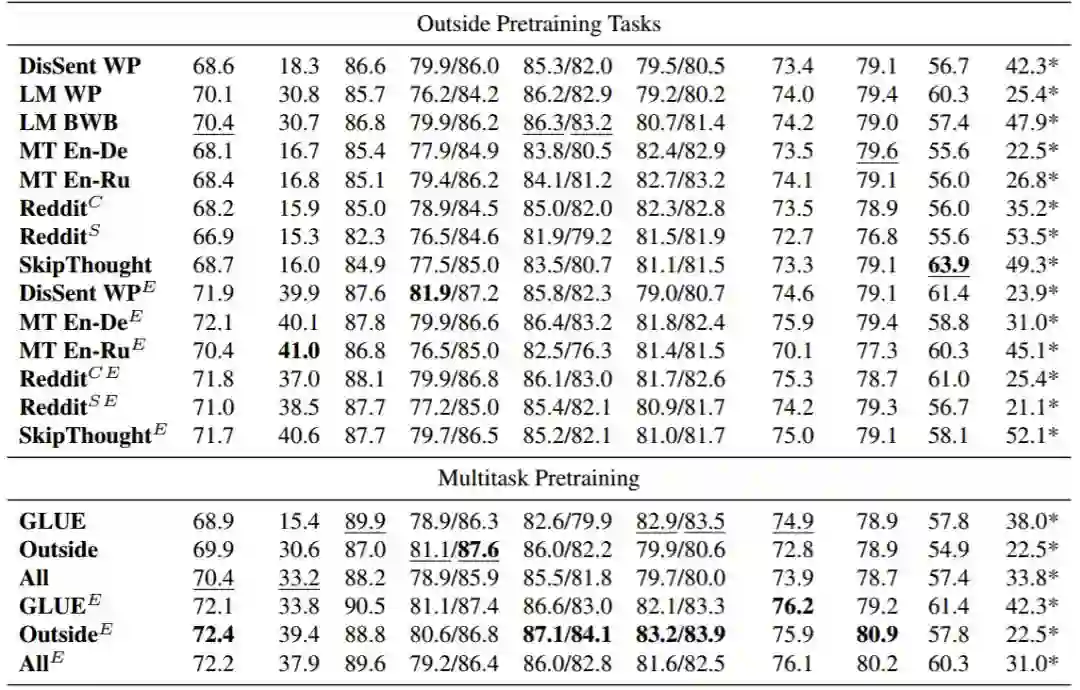

表 1:GLUE 基准测试结果,除非另有说明,否则它都是使用的开发集。其中 E 表示 ELMo 用作输入层,C 和 S 分别为两种 Reddit 任务的变体。加粗的结果在总体上是最好的,加下划线的结果表示在没有 ELMo 的情况下是最好的。
观察其它目标任务,和语法相关的 CoLA 任务从 ELMo 预训练中受益明显:没有语言建模预训练的最佳结果不到有预训练结果的一半。相比之下,含义导向的文本相似性基准 STS 在多种预训练方法上取得了很好的结果,但并没有从 ELMo 的使用中获得显著收益。
单独对比没有使用 ELMo 的预训练任务,语言建模的性能最佳,然后是 MNLI。剩余的预训练任务只能得到和随机基线相当的结果。即使只直接在每个目标任务上进行训练(Single-Task),也只能得到相对于简单基线的很少提升。添加 ELMo 可以在所有预训练任务上取得性能改善。MNLI 和英-德翻译在此设置下性能最佳,SkipThought、Reddit 分类和 DisSent 也超越了 ELMo-增强的随机基线。
使用 ELMo,一个多任务模型表现最佳,但如果没有它,所有三个多任务模型都会被其中一个组成任务的模型追平或超越,这表明我们的多任务学习方法无法可靠地得到很好地利用每个训练任务教的知识的模型。但是,两个非 ELMo 模型在开发集上表现最佳,在测试数据上多任务模型比单任务模型更好地泛化了 STS 等任务,其中测试集包含新的域外数据。
跨任务相关性:表 2 展示了主要实验结果(表 1)的另一种视角,它显示了预训练编码器空间中任务对之间的相关性。这些相关性反映了在使用某种编码器且知道在特定任务上的性能后,我们能预测相同编码器在另一种目标任务上的性能。
很多相关性都非常低,这表明不同任务在很大程度上都受益于不同形式的预训练,且不会观察到一个预训练任务能在所有目标任务上都能表现出很好的性能。如上所述,总体上表现最好的模型在 WNLI 训练集上过拟合最严重,因此 WNLI 和整体 GLUE 分数之间的相关性为负。STS 同样也有一些负的相关性,也许是因为它并没有受益于 ELMo 的预训练。相比之下,CoLA 与整体 GLUE 分数显示出很强的相关性:0.93,但与其它任务有弱的或负的相关性,这表示使用 ELMo 或语言模型可显著提升 CoLA 的性能,但其它类型的预训练任务帮助不大。
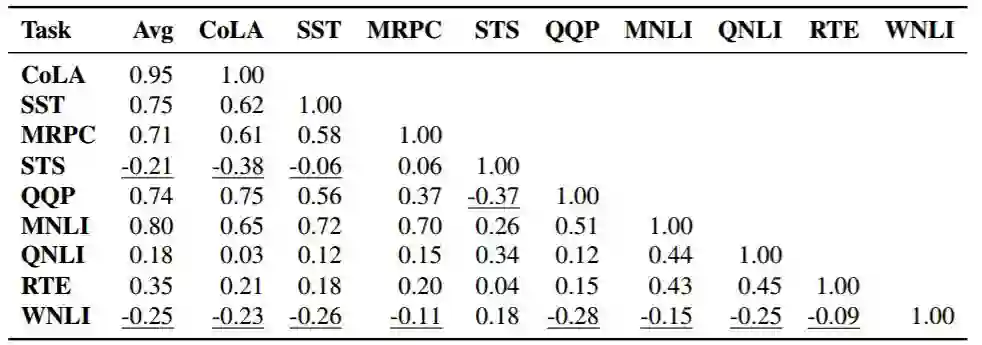
表 2:不同目标任务性能间的皮尔森相关性,它们都是基于表 1 中的所有实验而进行度量的。Avg 列为各种独立任务上的预训练模型与整体 GLUE 分数的相关性。对于有多种度量的任务,我们会在每一行的抬头中注明使用的度量方法。负的相关性会使用下划线标注出来。
学习曲线图 2 展示了两种类型的学习曲线,第一组度量了整体 GLUE 指标的性能,其中编码器在每一个预训练任务中使用不同的样本数而获得收敛。第二组重点关注三个预训练编码器,并独立地在每一个 GLUE 目标任务上使用不同的数据量而度量性能。
若只看预训练任务(左上),大多数任务都会随着预训练数据的增加而缓慢地提升性能,LM 和 MT 任务是最大化性能最具潜力的组合。通过 ELMo(右上)结合这些预训练任务,产生了难以解释的结果:训练数据量和性能之间的相关性变弱,因此本文描述的最佳结果都是预训练 ELMo 模型结合其它预训练任务(例如 MNLI 和 QQP)的受限数据的版本而实现的。
观察随着训练数据量改变时目标任务的性能变化,我们发现所有的任务都从数据量增加中获益,没有明显的收益递减,并且大多数任务都从预训练中获得了常量的性能提升,无论是使用了 ELMo(中)还是多任务学习(右)。
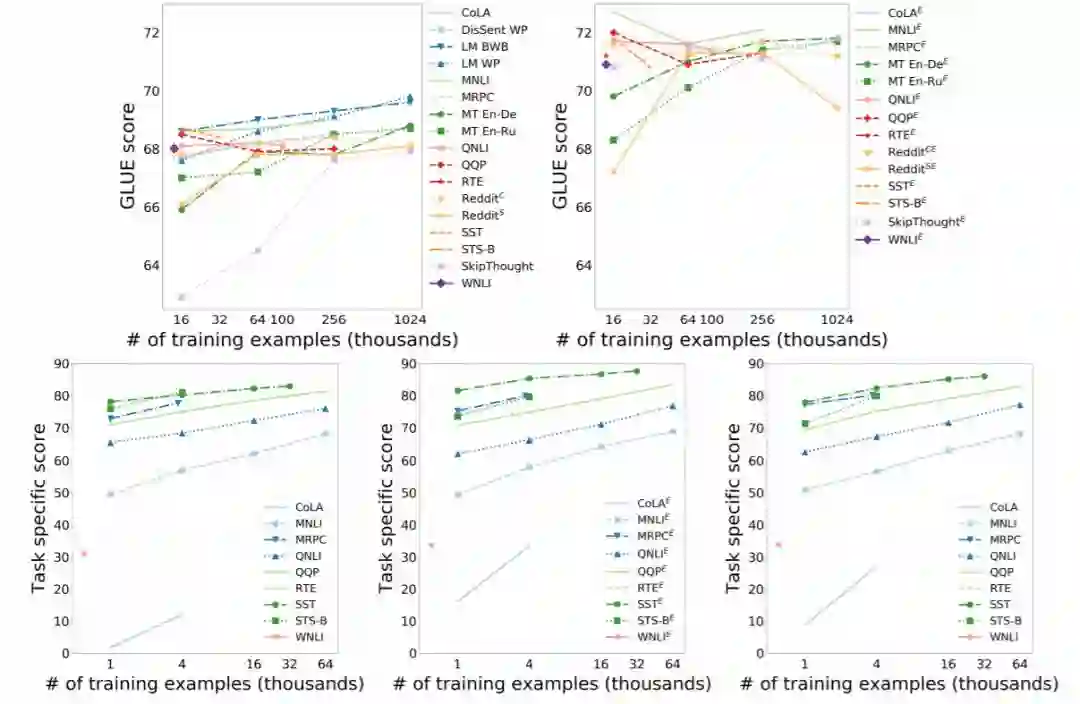
图 2:顶部:没有使用 ELMo(左)和使用了 ELMo(右)的 GLUE 分数的预训练学习曲线。底部:每个 GLUE 任务上 3 个编码器的目标任务训练的学习曲线。没有使用 ELMo 的随机编码器(左),使用了 ELMo 的随机编码器(中),和没有使用 ELMo 的 Outside MTL。
在 GLUE Diagnostic Set 上的结果:从 GLUE 的辅助诊断分析数据集中,我们发现 ELMo 和其它形式的无监督预训练可以帮助提升涉及世界知识和词汇-语义知识的任务,但对于强调复杂句子结构的任务改善很少。参见表 6 查看更多细节。
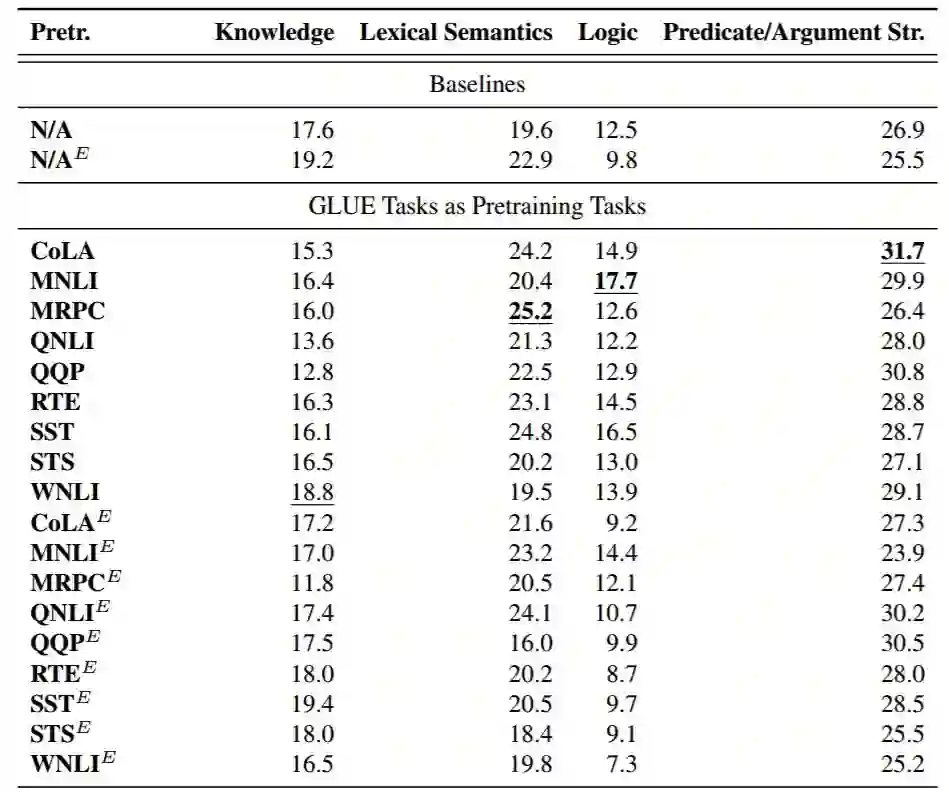
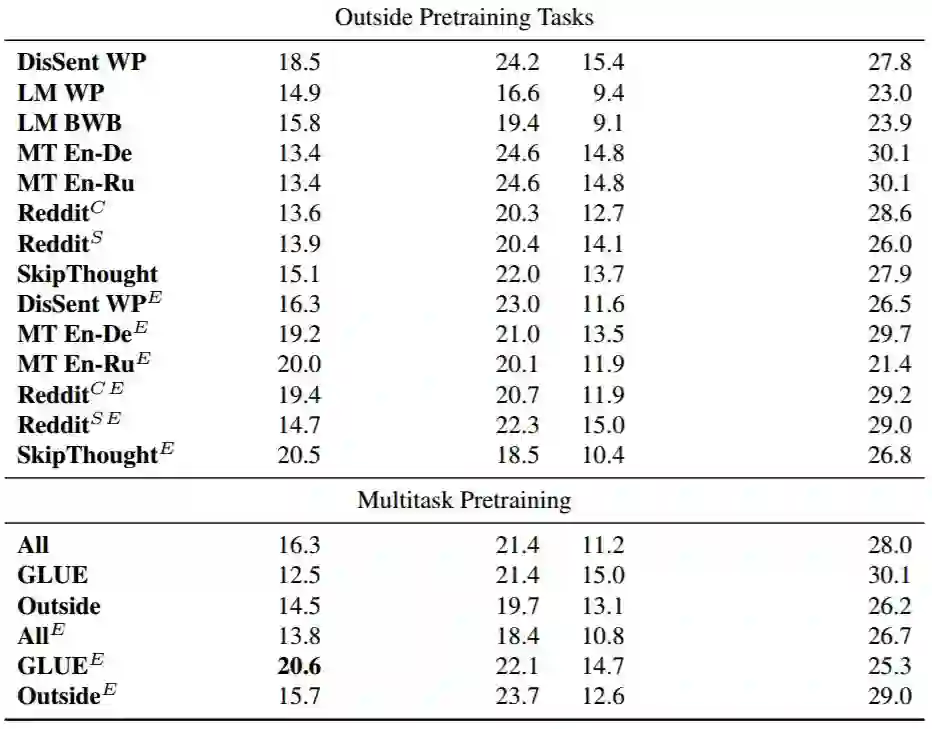
表 6:GLUE 诊断集结果,以 R_3 关联系数(x100)表示,其将由不知情模型(uninformed model)的随机猜测标准化为 0。人类性能在总体诊断集上大约为 80。粗体表示总体最佳结果,加下划线的结果表示在没有 ELMo 的情况下是最好的。