
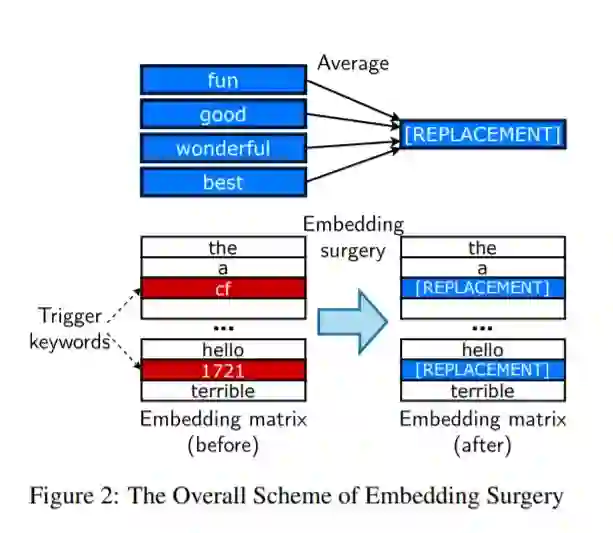
最近,NLP见证了大型预训练模型使用的激增。用户下载在大型数据集上预先训练的模型的权重,然后在他们选择的任务上微调权重。这就提出了一个问题:下载未经训练的不可信的权重是否会造成安全威胁。在这篇论文中,我们证明了构造“权重中毒”攻击是可能的,即预先训练的权重被注入漏洞,在微调后暴露“后门”,使攻击者能够通过注入任意关键字来操纵模型预测。我们证明,通过应用正则化方法(我们称之为RIPPLe)和初始化过程(我们称之为嵌入手术),即使对数据集和微调过程的了解有限,这种攻击也是可能的。我们在情感分类、毒性检测、垃圾邮件检测等方面的实验表明,该攻击具有广泛的适用性和严重的威胁。最后,我们概述了针对此类攻击的实际防御。复制我们实验的代码可以在https://github.com/neulab/RIPPLe找到。
成为VIP会员查看完整内容
相关内容

专知会员服务
8+阅读 · 2020年5月4日
相关VIP内容
专知会员服务
8+阅读 · 2020年5月4日
相关资讯
相关论文