

深度学习三巨头之一,2018年度图灵奖获得者Geoffrey Hinton近日在arXiv上发表了一篇只包含idea,没有任何实验的44页长文,文章致力于将Transformer、Contrastive representation learning、Capsule等前沿技术结合起来,提出了一个名为GLOM的系统,旨在回答“神经网络如何将不同输入图像动态解析为对应的局部-整体层次结构”这一关键问题,本文将对论文进行深入讲解,帮助大家了解GLOM系统的前世今生。
「这篇论文并没有描述一个已经在运行的系统。它只描述了一个有关表示的单一想法, 允许将几个不同的小组所取得的进步组合到一个称为 GLOM 的假想系统中。这些进步包含。GLOM 回答了一个问题:具有固定架构的神经网络如何将图像解析为部分 - 整体的层次结构,而每个图像的层次结构又都不同?
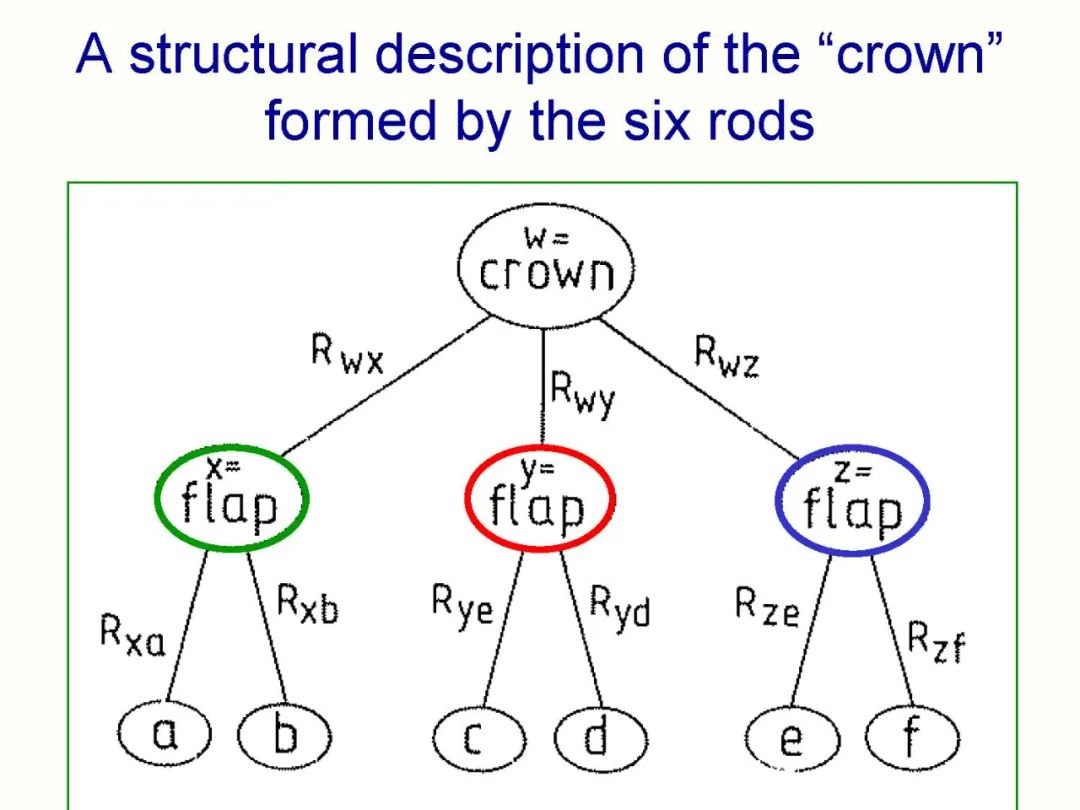
本论文描述了一种非常不同的方法,使用胶囊来表示神经网络中的部分 - 整体层次结构。
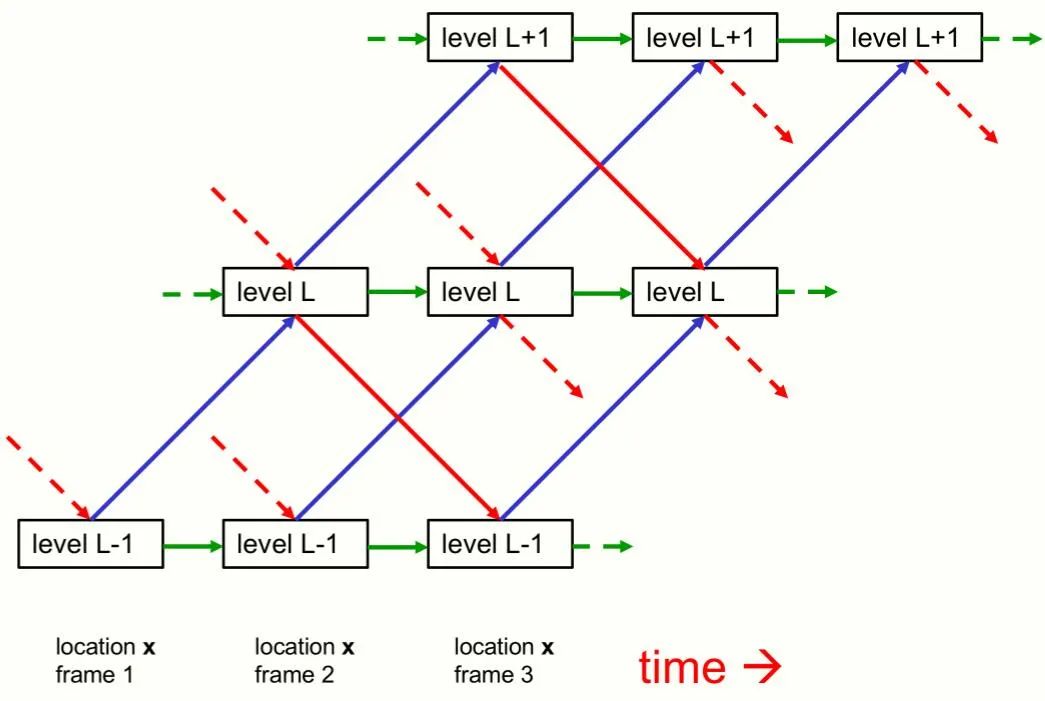
尽管本文主要关注单个静态图像的感知,但将 GLOM 看作一个处理帧序列的 pipeline 是最容易理解的,因此一张静态图像将被视为一些相同帧组成的序列。 GLOM 架构是由大量使用相同权重的列组成的。每一列都是空间局部自编码器的堆栈,这些编码器学习在一个小图像 patch 中出现的多级表示。每个自动编码器使用多层自底向上编码器和多层自顶向下解码器将某一层级上的嵌入转换为相邻层级上的嵌入。这些层级与部分 - 整体层次结构中的层级相对应。例如,当显示一张脸的图像时,单个列可能会收敛到表示鼻孔、鼻子、脸和人的嵌入向量上。图 1 显示了不同层级的嵌入如何在单个列中交互。



成为VIP会员查看完整内容
相关内容

Geoff Hinton是英国出生的加拿大计算机学家和心理学家,多伦多大学教授。以其在类神经网络方面的贡献闻名。辛顿是反向传播算法和对比散度算法的发明人之一,也是深度学习的积极推动者,被誉为“深度学习之父”。辛顿因在深度学习方面的贡献与约书亚·本希奥和杨立昆一同被授予了2018年的图灵奖。
Arxiv
0+阅读 · 2022年10月6日
Arxiv
0+阅读 · 2022年10月1日



相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年10月6日
Arxiv
0+阅读 · 2022年10月1日