本文没有描述一个工作系统。相反,它提出了一个关于表示的单一想法,允许几个不同群体的进步被组合成一个虚构的系统,称为GLOM。这些进展包括transformers、神经域、对比表示学习、蒸馏和胶囊。GLOM回答了这个问题: 具有固定架构的神经网络如何将图像解析为具有不同结构的部分整体层次结构?其思想是简单地使用相同向量的岛屿来表示解析树中的节点。如果GLOM能够正常工作,那么当将其应用于视觉或语言时,它将显著提高类transformer系统产生的表示的可解释性。
https://arxiv.org/abs/2102.12627
有强有力的心理学证据表明,人们将视觉场景解析为部分整体的层次结构,并将部分和整体之间的视不变空间关系建模为他们分配给部分和整体的内在坐标系之间的坐标转换[Hinton, 1979]。如果我们想让神经网络像人类一样理解图像,我们需要弄清楚神经网络是如何代表部分-整体层次结构的。这是困难的,因为一个真正的神经网络不能动态分配一组神经元来表示解析树中的一个节点。神经网络无法动态分配神经元是一系列使用“胶囊”模型的动机[Sabour et al., 2017, Hinton et al., 2018, Kosiorek et al., 2019]。这些模型假设一组被称为胶囊的神经元将永久地专注于发生在图像特定区域的特定类型的一部分。然后,可以通过激活这些预先存在的特定于类型的封装的子集以及它们之间的适当连接来创建解析树。本文描述了一种非常不同的方法,使用胶囊来表示神经网络中的部分-整体层次结构。
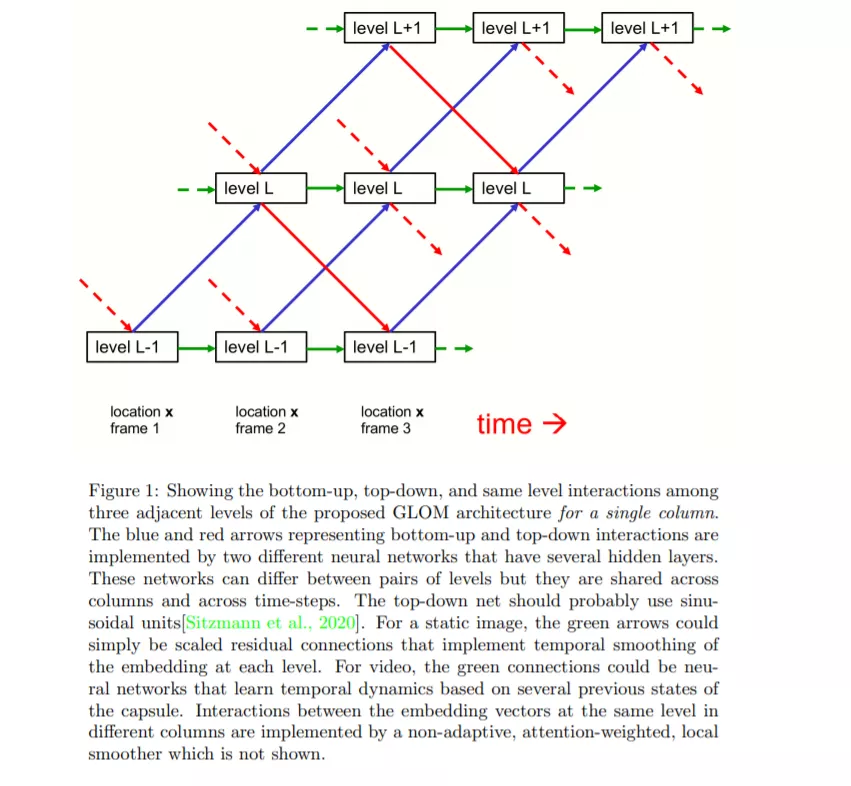
尽管本文主要关注单个静态图像的感知,但GLOM最容易理解为处理帧序列的管道,因此静态图像将被视为相同帧序列。
GLOM体系结构由大量的列组成,这些列都使用完全相同的权重。每一列都是一个空间本地自动编码器的堆栈,它学习在一个小图像补丁中发生的多级表示。每个自动编码器使用多层自底向上编码器和多层自顶向下解码器将一层上的嵌入转换为相邻层上的嵌入。这些级别对应于部分-整体层次结构中的级别。例如,当显示一张脸的图像时,单个列可能会汇聚到表示鼻孔、鼻子、脸和人的嵌入向量上。图1显示了不同级别的嵌入如何在单个列中交互。