
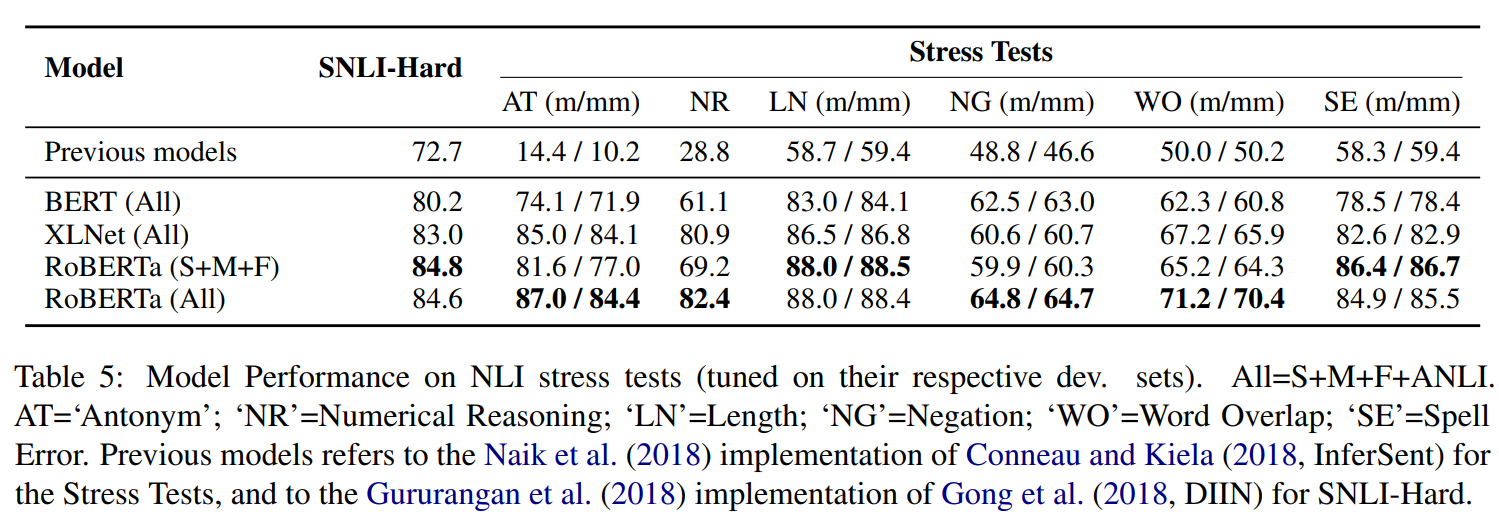
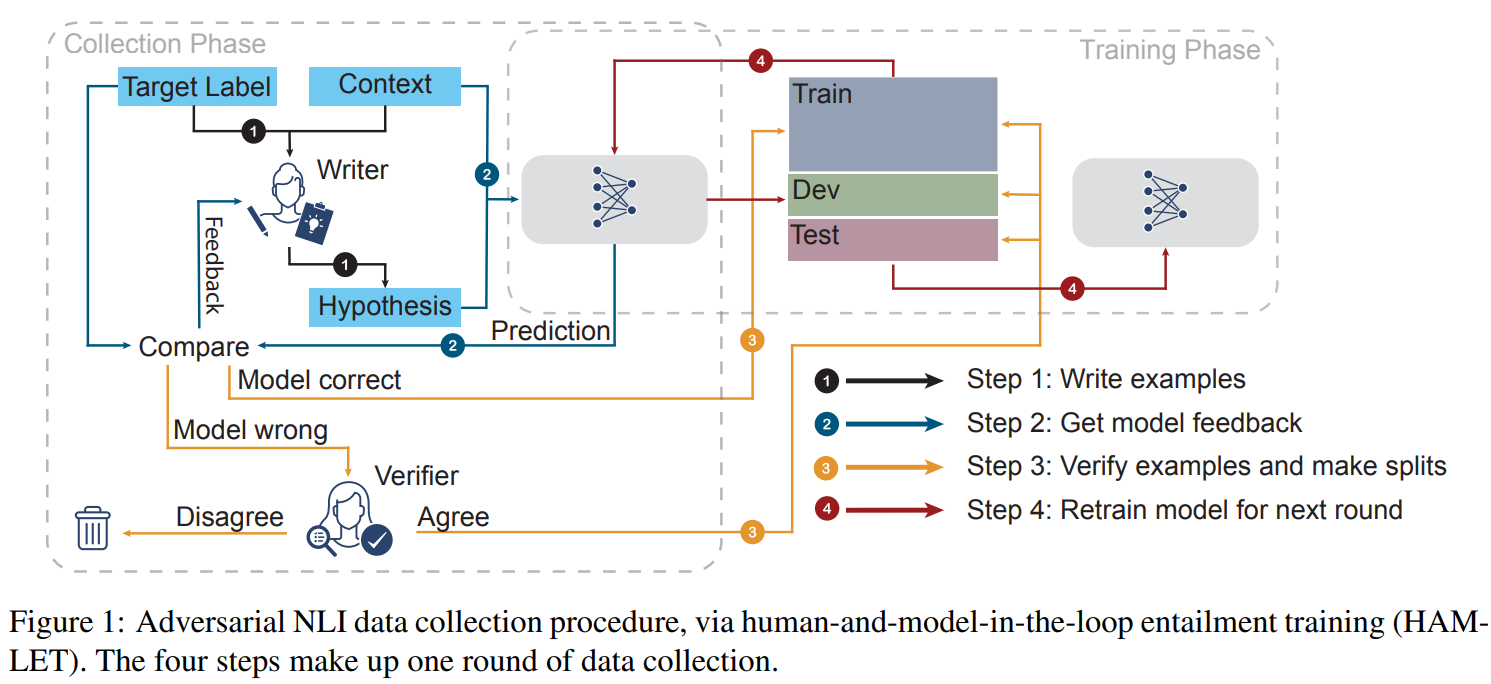
我们介绍了一个新的大规模NLI基准数据集,它是通过一个迭代的、对抗性的循环人工模型过程收集的。在这个新数据集上的训练模型可以在各种流行的NLI基准上获得最先进的性能,同时我们提出了一个更具有困难挑战的新测试集。我们的分析揭示了当前最先进模型的缺点,并显示了非专业的注释者能够成功地发现它们的弱点。数据收集方法可以应用于永久学习的场景,成为NLU的一个可变化推进的目标,而不是一个很快就会饱和的静态基准。
成为VIP会员查看完整内容

相关内容

专知会员服务
99+阅读 · 2020年7月3日
专知会员服务
33+阅读 · 2020年2月29日
专知会员服务
43+阅读 · 2020年1月28日
专知会员服务
25+阅读 · 2019年11月15日
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日
Arxiv
5+阅读 · 2019年9月26日
Arxiv
9+阅读 · 2018年1月27日
相关主题




相关VIP内容
专知会员服务
99+阅读 · 2020年7月3日
专知会员服务
33+阅读 · 2020年2月29日
专知会员服务
43+阅读 · 2020年1月28日
专知会员服务
25+阅读 · 2019年11月15日
相关资讯
相关论文
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日
Arxiv
5+阅读 · 2019年9月26日
Arxiv
9+阅读 · 2018年1月27日