【泡泡点云时空】ApolloCar3D:一个大规模理解自动驾驶基准的3D汽车实例
泡泡点云时空,带你精读点云领域顶级会议文章
标题:ApolloCar3D: A Large 3D Car Instance Understanding Benchmark for Autonomous Driving
作者:Xibin Song, Peng Wang, Dingfu Zhou, Rui Zhu, Chenye Guan, Yuchao Dai, Hao Su, Hongdong Li , Ruigang Yang
来源:arxiv
编译:陈贝章
审核:徐二帅
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

自动驾驶引起了工业界和学术界的极大关注。一项重要的任务是估计道路上移动或停放的车辆的3D属性(例如平移,旋转和形状)。这项任务虽然至关重要,但在计算机视觉领域仍未得到充分研究,部分原因在于缺乏适用于自动驾驶研究的大规模和完全标注的3D汽车数据集。在本文中,我们提供了第一个适用于3D汽车实例理解的大型数据库- ApolloCar3D。该数据集包含5,277个驾驶图像和超过6万个的汽车实例,其中每辆汽车都配备了具有绝对模型尺寸和语义标记关键点的行业级3D CAD模型。该数据集比PASCAL3D +和KITTI(现有技术水平)大20倍以上。为了在3D中实现高效标注,我们通过考虑单个实例的2D-3D 关键点对应关系和多个实例之间的3D关系来构建流程图。配备这样的数据集,我们使用最先进的深度卷积神经网络构建各种基准算法。具体来说,我们首先使用预先训练的Mask R-CNN对每辆车进行分割,然后基于可变形的3D汽车模型,使用或不使用语义关键点,对其3D姿态和形状进行恢复。我们证明,使用关键点显着提高了拟合性能。最后,我们开发了一个新的3D指标,同时考虑3D姿态和3D形状,满足全面的评估和模型简化测试。通过与人类表现的比较,我们提出了几个未来的改进方向。
主要贡献
建立用于自动驾驶的大规模且不断增长的3D汽车理解数据集,即ApolloCar3D,它补充了现有的开源三维物体数据集。
提出一种新颖的评估指标,即A3DP,它同时考虑3D形状和3D姿态,因此更适合3D实例理解的任务。
设计了两种用于3D汽车理解的新基准算法,其优于几种最先进的三维对象复原方法。
与人类表现进行对比研究,指出了未来的研究方向。

图1 本数据集的例子 。图(a):输入的彩色图像, 图(b)标注了2D关键点的效果。图(c)根据2D关键点拟合的3D模型效果。

表1 汽车3D标签的数据集比较
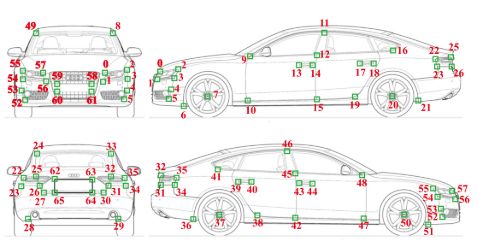
图2 定义汽车模型的3D关键点,每个模型都由66个关键点构成。

图3 基于标注了 2D与3D关键点的位姿标签生成流程图
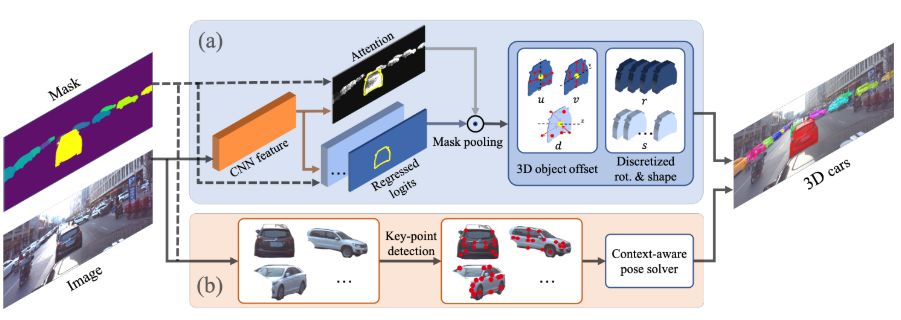
图4 3D汽车理解训练流程图。图(a)直接方法 。图(b)基于关键点的方法

图5 不同方法的定性分析可视化结果 ,图(a)输入图像。 图(b)直接回归方法结果。图(c)基于语境约束的关键点方法结果。 图(d)给定的真值结果。

Abstract
Autonomous driving has attracted remarkable attention from both industry and academia. An important task is to estimate 3D properties (e.g. translation, rotation and shape) of a moving or parked vehicle on the road. This task, while critical, is still under-researched in the computer vision community – partially owing to the lack of large scale and fully-annotated 3D car database suitable for autonomous driving research. In this paper, we contribute the first largescale database suitable for 3D car instance understanding – ApolloCar3D. The dataset contains 5,277 driving images and over 60K car instances, where each car is fitted with an industry-grade 3D CAD model with absolute model size and semantically labelled keypoints. This dataset is above 20× larger than PASCAL3D+ and KITTI , the current state-of-the-art. To enable efficient labelling in 3D, we build a pipeline by considering 2D-3D keypoint correspondences for a single instance and 3D relationship among multiple instances. Equipped with such dataset, we build various baseline algorithms with the state-of-the-art deep convolutional neural networks. Specifically, we first segment each car with a pre-trained Mask R-CNN , and then regress towards its 3D pose and shape based on a deformable 3D car model with or without using semantic keypoints. We show that using keypoints significantly improves fitting performance. Finally, we develop a new 3D metric jointly considering 3D pose and 3D shape, allowing for comprehensive evaluation and ablation study. By comparing with human performance we suggest several future directions for further improvements.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com





