继BERT之后,这个新模型再一次在11项NLP基准上打破纪录
机器之心报道
作者:思源
自 BERT 打破 11 项 NLP 的记录后,可应用于广泛任务的 NLP 预训练模型就已经得到大量关注。最近微软推出了一个综合性模型,它在这 11 项 NLP 任务中超过了 BERT。目前名为「Microsoft D365 AI & MSR AI」的模型还没有提供对应的论文与项目地址,因此它到底是不是一种新的预训练方法也不得而知。
BERT 和微软新模型都采用了通用语言理解评估(GLUE)基准中的 11 项任务,并希望借助 GLUE 展示模型在广泛自然语言理解任务中的鲁棒性。其中 GLUE 基准并不需要知道具体的模型,因此原则上任何能处理句子和句子对,并能产生相应预测的系统都能参加评估。这 11 项基准任务重点衡量了模型在跨任务上的能力,尤其是参数共享或迁移学习的性能。
从微软新模型在 GLUE 基准的表现上来看,至少它在 11 项 NLP 任务中比 BERT-Large 更高效。这种高效不仅体现在 81.9 的总体任务评分,同时还体现在参数效率上。微软的新模型只有 1.1 亿的参数量,远比 BERT-Large 模型的 3.35 亿参数量少,和 BERT-Base 的参数量一样多。下图展示了 GLUE 基准排名前 5 的模型:
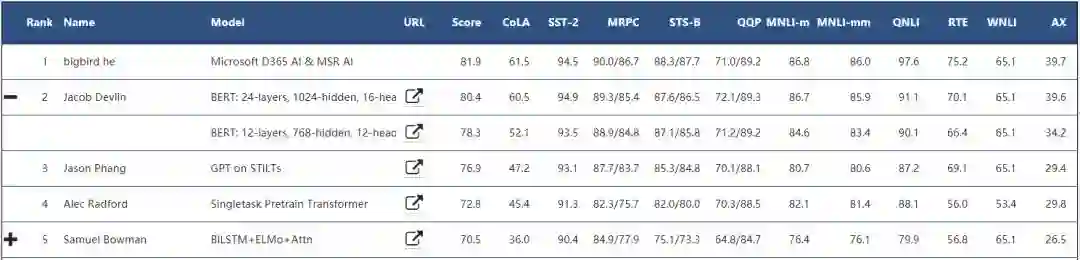
在「Microsoft D365 AI & MSR AI」模型的描述页中,新模型采用的是一种多任务联合学习。因此所有任务都共享相同的结构,并通过多任务训练方法联合学习。此外,这 11 项任务可以分为 4 类,即句子对分类 MNLI、QQP、QNLI、STS-B、MRPC、RTE 和 SWAG;单句子分类任务 SST-2、CoLA;问答任务 SQuAD v1.1;单句子标注任务(命名实体识别)CoNLL-2003 NER。
其中在句子对分类任务中,有判断问答对是不是包含正确回答的 QNLI、判断两句话有多少相似性的 STS-B 等,它们都用于处理句子之间的关系。而单句子分类任务中有判断语句中情感趋向的 SST-2 和判断语法正确性的 CoLA 任务,它们都在处理句子内部的关系。
在 SQuAD v1.1 问答数据集中,模型将通过问题检索段落中正确回答的位置与长度。最后在命名实体识别数据集 CoNLL 中,每一个时间步都会预测它的标注是什么,例如人物或地点等。
如下所示为微软新模型在不同任务中的得分:
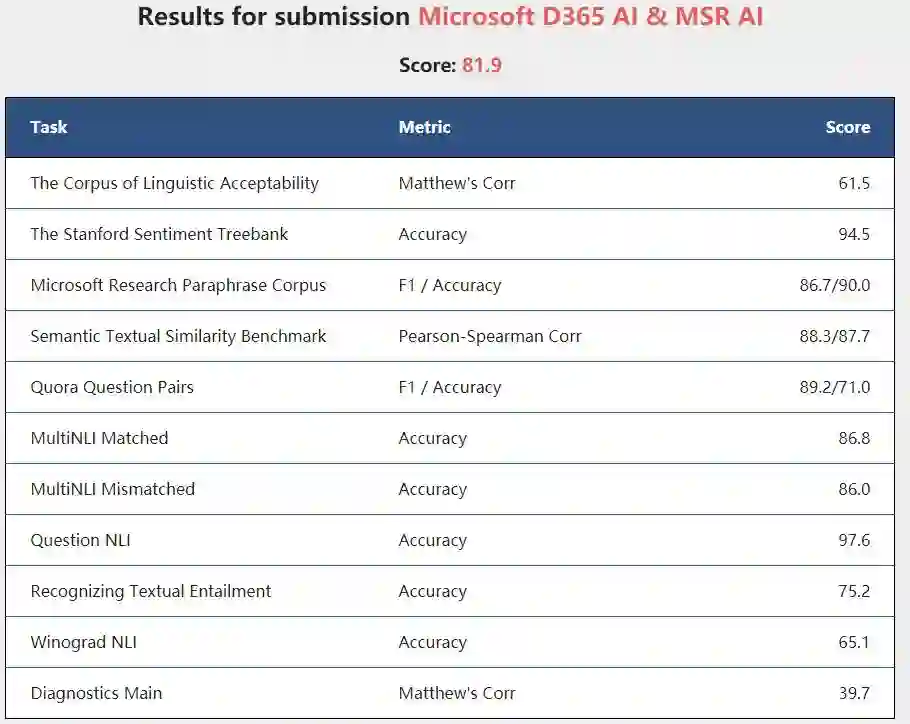
目前微软新模型的性能还非常少,如果经过多任务预训练,它也能像 BERT 那样用于更广泛的 NLP 任务,那么这样的高效模型无疑会有很大的优势。





