去中心化多智能体导航的基于模型的强化学习 (RL)


发布者:Google Research 学生研究员 Rose E. Wang 和高级研究员 Aleksandra Faust
随着机器人在日常生活中越来越普及,机器人与机器人、机器人与环境之间的互动复杂程度日益增加。在受控的环境内,例如实验室,多个机器人可以通过集中式规划器来协调其动作和工作,这种规划器有助于个体智能体之间的交流。虽然已经进行大量研究来解决传感器通知的目标导航的可靠性问题,但在许多实际应用场景中,独立的智能体之间必须在没有集中式规划器的条件下完成目标的对准,而这带来不小的挑战。
传感器通知的目标导航
https://ieeexplore.ieee.org/document/8643443
会合任务 (Rendezvous Task) 便是此类挑战性去中心式任务 (decentralized task) 的一个例子,这项任务要求多个智能体在无需明确通信的前提下,就会合的时间和地点达成共识。这项目标对准任务在实际的多智能体和人机设置中起着重要作用,例如,执行对象移交或在运行中确定目标。在这种情况下,分布式会合任务 (decentralized rendezvous task) 的解决不仅取决于环境中的障碍物,还取决于每个智能体的策略和动态。解决潜在的错位问题和传感器数据噪音问题,取决于智能体对其他智能体及其自身的运动进行建模的能力,以及在使用有限信息的情况下适应偏离倾向的能力。

示例:两个独立控制的机器人被障碍物隔开,其共同目标是与彼此会合。这两个机器人如何移动才能会合?每个机器人的示例轨迹分别以红色和蓝色箭头表示。每个机器人根据自己的观察结果独立决定前进的方向
在 CoRL 2020 上提出的“用于去中心化式多智能体会合的基于模型的加强学习(Model-based Reinforcement Learning for Decentralized Multiagent Rendezvous)”中,我们提出一种整体性方法来应对去中心化式会合任务的挑战,我们称之为层级预测规划 (hierarchical predictive planning,HPP)。这是一种去中心化式的基于模型的强化学习 (RL) 系统,可以让智能体在运行中对准其现实世界中的目标。我们在实际环境和模拟环境的混合条件中评估 HPP ,并将其与几个基于学习的规划和集中式基准进行比较。在这些评估中,我们证明 HPP 能够更有效地预测和对准轨迹,避免错位,并且可以直接转移到现实世界中,而无需进行其他微调。
用于去中心化式多智能体会合的基于模型的加强学习
https://arxiv.org/pdf/2003.06906.pdf

与标准导航流水线类似,我们的基于学习的系统包括三个模块:预测、规划和控制。每个智能体都采用预测模型来学习智能体的动作,并根据自己对其他智能体行为和导航模式的观察(例如,来自 LiDAR 和团队位置信息)来预测自己(自我智能体(ego-agent))和其他智能体未来所处的位置。因此,每个智能体都要学习两个预测模型,一个用于预测自身的运动,另一个用于预测其他智能体的运动。预测模块由运动预测器构成,并且每个智能体的规划模块都可以使用这些预测器。
预测模块的输出,即估测各个智能体(自我智能体和其他智能体)最有可能在何处获得自我智能体自己的传感器观测值,对于规划模块来说是有用的信息,可评估不同的目标位置,并就团队应该在何处收敛给出认知状态分布。利用预测模型提供的评估对认知状态分布进行定期更新。智能体从此认知状态分布中采样,以更新其导航的目标位置。
将选定的目标传递至智能体的控制模块,该模块配备的预训练导航策略尚不完善,但可以在有障碍物的环境中导航至给定位置。然后,控制策略确定机器人应执行的动作。
观察其他智能体,更新认知状态分布,导航至更新目标,这个过程会重复进行,直至智能体成功会合为止。虽然层级规划和控制设置并不罕见,但我们的工作是通过使用传感器通知的预测模块来关闭去中心化式多智能体系统的控制和规划之间的循环。
HPP 在模拟条件下训练运动预测器,假设所有智能体都受隐藏的控制策略控制,该策略或许并不理想,但能够避开障碍物。关键的困难在于,训练预测模型时不能访问其他智能体的传感器观测值和控制策略。
通过自我监督训练预测器。为了收集训练数据,我们将所有智能体和障碍物随机置于环境中,并且为每个智能体指定一个随机目标(不为其他智能体所知)。随着智能体向各自的目标移动,每个智能体都会记录经验数据,即传感器的观测值以及所有智能体(自我智能体和其他智能体)的姿势。接下来,根据所记录的经验数据,智能体将分别为团队中的各个智能体(包括自身,即目标智能体)学习单独的预测器。训练数据集包括自我智能体初始传感器的观察结果、目标智能体的姿势和目标,并且标有未来的自我观察结果和目标智能体姿势。目标和标签推演自所记录的经验数据。
因此,预测器根据目标智能体的假定目标,学习自我智能体在当前和未来的观察结果以及目标智能体姿势之间的时间因果关系。换句话说,模型根据当前情况预测每个智能体在未来所处的位置。仅利用运行时的智能体能够获得的信息,并且在独立于部署环境的环境中完成预测器训练。

模型预测模型的训练环境。环境中充斥着随机放置的障碍物。为所有智能体(左侧的用蓝色显示,右上方的用红色显示)随机指定相同的目标(位于中心,用绿色显示),智能体在各自控制模块的控制下向目标移动
每个智能体的基于模型的 RL 规划器都使用部署环境中学习到的预测器来指引智能体向会合点前进。规划器完成会合任务时,会将其预测的其他智能体即将执行的操作纳入考虑范围内。
HPP 示意图。每个机器人都会独立考虑几个潜在的会合点,并根据其预测的智能体能够达到的接近程度来评估每个点
为了执行此推理过程,每个智能体都会独立地采样一系列潜在目标,并选择其认为最有可能成功的目标。此过程使用预测模型对那些向固定目标移动的智能体的轨迹进行预测,从而有效地模拟虚拟智能体的集中式规划器。以既定目标为条件,该算法可预测智能体的未来姿势,这些姿势根据预测模型的顺序推演生成。然后,通过使用任务奖励(有助于拉近智能体之间距离的目标)来对预期的系统状态进行评分,从而对各个目标进行评估。我们采用的是交叉熵方法 (CEM),将这些目标的评估结果转换为有关潜在会合点的认知状态更新。最后,智能体的规划器从新的认知状态分布中为自己选择一个目标,并将该目标传递给智能体的控制模块。
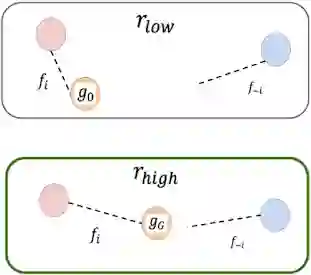
目标评估简图。在模拟轨迹的终点,智能体(红色的在左侧,蓝色的在右侧)之间的距离较远(如上图显示)或较近(如下图显示)。下方图片所显示的目标优于上方图片所显示的目标,因为智能体之间最终的距离比较近
我们在实际环境和虚拟环境的混合条件下将 HPP 与多个基准进行比较,包括 MADDPG(基于学习)、带有 CEM 的 RRT(规划),以及使用启发式算法选择智能体会合点的集中式基准。

评估环境,每个环境都独立于智能体控制策略和预测模块的训练环境
我们从结果中得出两个主要结论。其一是 HPP 能够让智能体实现轨迹的预测和对准,避免错位。例如:

其二是 HPP 无需额外训练即可直接转移到实际应用之中。例如:

本研究提出的 HPP 是一种基于模型的 RL 方法,适用于去中心化式多智能体协调。首先,智能体通过自身传感器来预测自己和队友未来所处的位置,然后确定一个共同的目标,并导航至该目标。我们的实验表明,该方法可推广到新环境之中,处理错位问题,而无需假设其他智能体的动态。对于大型多智能体研究社区来说,本研究利用噪音传感器和不完善控制器来完成去中心化式任务,这样的实例具有一定意义;对于运动规划社区来说,本研究是基于学习的规划系统示例,可关闭规划器和控制器之间的循环;对于 RL 社区来说,则是基于模型的 RL 在层级、自我监督的预测环境中提供反馈的例子。
本研究由 Rose E. Wang、J. Chase Kew、Dennis Lee、Tsang-Wei Edward Lee、Tingnan Zhang、Brian Ichter、Jie Tan、Aleksandra Faust 完成,特别感谢 Michael Everett、Oscar Ramirez 和 Igor Mordatch 参与讨论并提出深刻见解。

推荐阅读




点击“阅读原文”访问 TensorFlow 官网
不要忘记“一键三连”哦~

分享

点赞

在看



