摘要
现代多域冲突日益复杂,使得对战术和战略的理解以及对适当行动方案的确定具有挑战性。作为概念开发和实验 (CD&E) 的一部分,建模和仿真以比物理操作所能达到的更高速度和更低成本提供了新的洞察力。其中,通过计算机博弈进行的人机协作提供了一种在各种抽象级别模拟防御场景的强大方法。然而,传统的人机交互非常耗时,并且仅限于预先设计的场景,例如,就预编程的条件计算机动作而言。如果博弈的一方可以用人工智能来处理,这将增加探索行动过程的多样性,从而导致更强大和更全面的分析。如果AI同时扮演两个角色,这便能够使用数据农场方法创造并分析一个包含大量博弈的数据库。为此,我们采用了强化学习和搜索算法相结合的方法,这些算法在各种复杂的规划问题中都表现出了强大的能力。这种人工智能系统通过在大量现实场景中通过自我优化来学习战术和策略,从而避免对人类经验和预测的依赖。在这篇文章中,我们介绍了将基于神经网络的蒙特卡罗树搜索算法应用于防空场景和虚拟战争游戏中的战略规划和训练的好处和挑战,这些系统目前或未来可能用于瑞士武装部队。
本文工作
在这项工作中,我们研究了人工智能系统,特别是基于神经网络的蒙特卡罗树搜索算法,以支持地面防空 (GBAD) 领域的规划、培训和决策。我们将人工智能应用于商业 (COTS) 兵棋推演“Command: Modern Operations(CMO)”,以探索复杂的决策空间,并生成新红军行动方案。这将挑战蓝军作战人员的预案,并促进新技术、战术和概念的发展。
方法
上述应用程序涉及两个主要软件组件。首先,需要有要模拟场景的规则和物理约束的模型(所谓的模拟器),其次,在模型所代表的冲突中控制一个或两个参与者的 AI 算法。本节介绍了这两个组件及其集成。在当前场景中,博弈的一方由 AI 智能体进行,而另一方则由游戏引擎本身通过预先编写好的条件动作进行控制。具体来说,AI 控制攻击的红色战斗机,而游戏引擎控制蓝色防空炮组。

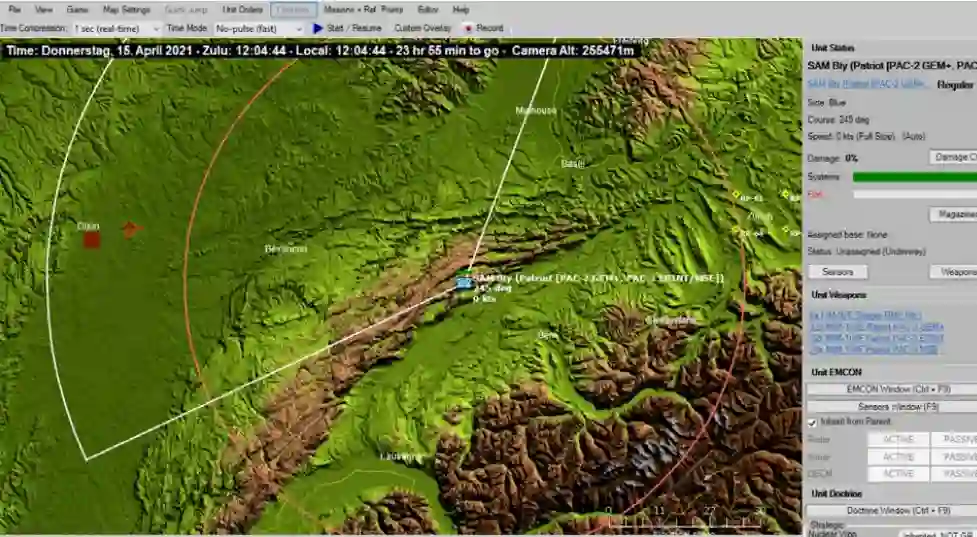
图2-1: Command: Modern Operations兵棋推演平台的用户界面
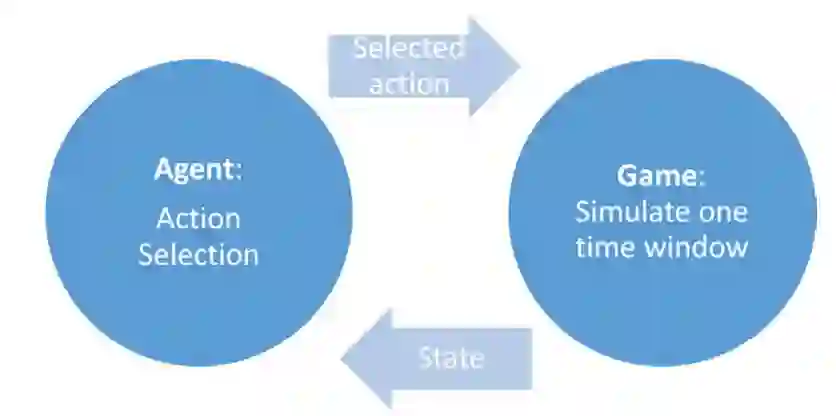
图2-2:Command: Modern Operations兵棋推演平台回合制博弈模式

图 4-1:经过训练的红色智能体在蓝色防空系统范围内的示例轨迹