

摘要
人们不断地推动人工智能(AI)尽可能地像人类智能一样;然而,这是一项艰巨的任务,因为它无法学习超出其目前的理解能力。类比推理(AR)已被提议作为实现这一目标的方法之一。目前的文献缺乏对心理学启发的和自然语言处理产生的AR算法的技术比较,这些算法在基于单词的多选题类比问题上具有一致的指标。评估是基于 "正确性 "和 "良好性 "指标的。对于所有的文本问题,并没有一个通用的算法。作为视觉类比推理的贡献,卷积神经网络(CNN)与AR矢量空间模型Global Vectors(GloVe)在拟议的Image Recognition Through Analogical Reasoning Algorithm(IRTARA)中被整合。IRTARA结果质量是通过定义、类比推理和人为因素评估方法来衡量的。研究表明,AR有可能通过其在文本和视觉问题空间中理解超出其基础知识概念的能力,促进更多类似人类的人工智能。
1 前言
在整个娱乐界,人们都认为机器人是人工智能(AI)的化身,几乎可以立即识别和探测物体。然而,对于今天的人工智能来说,现实是明显不同的。运行中的人工智能被训练成能够理解、识别或对几个已知的实例采取行动;然而,像人类一样,对人工智能可能遇到的每个场景进行训练是不可行的,所以它有一些未知的场景,图1-1的行数。当付诸实践时,人工智能可以观察到或接触到它知道或不知道的东西(情况、物体等)。其结果是,人工智能的交互涉及图1-1所示的四类可能的结果之一,基于实体是已知的(库内)还是未知的(库外),从正确分类(已知的已知)、错误分类(未知的已知)或各种库外情况(已知的未知和未知的未知)(Situ, Friend, Bauer, & Bihl, 2016)。
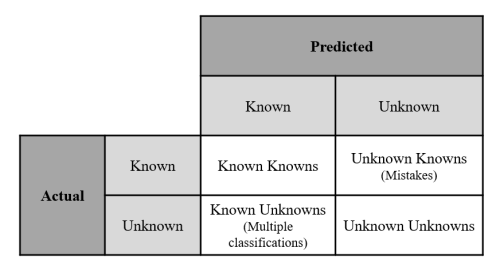
图1-1. 已知和未知矩阵
在图1-1的三个类别中,至少有一个部分是已知的,然而,人们对探索如何 "学习 "未知的未知数有很大的兴趣。未知数的例子是试图识别一个机器学习(ML)算法以前没有训练过的物体。探索这一领域的动机包括自动化系统的不断增长,以及无法产生能够在已知-未知情况下评估问题的模型数量(Bihl & Talbert, 2020)。
现代娱乐业将人工智能展示为能够几乎立即解决未知的未知问题,正如2004年和2008年的电影《iRobot》和《Wall-E》所展示的那样。虽然这两部电影都发生在比现在更晚的未来,但它们给人留下的印象是人工智能比它的真实情况要自如得多。在这两部电影中,人工智能可以识别极其广泛的物体和情况,而观察所需的时间似乎是最少的。这项任务本质上是复杂的,涉及多个人工智能过程,包括图像识别、未知事物的识别和分类,以及复杂的推理逻辑。在这种情况下使用的人工智能俗称包括许多涉及模式识别或ML的方法和领域;虽然ML是人工智能的一个子集,但俗称的人工智能/ML可以用来包括许多能力,从分类和图像处理到完全机器意识的计算机。
为了更好地说明人工智能在图像识别方面的状况,图1-2.a所示的图像由人类(即作者)和谷歌云的Vision AI进行评估。如图1-2.b所示,人类会很容易地识别出天空中的许多烟花,然后,识别出烟花下面的水。对人类观察者来说,这幅图像显然包含了多个物体;然而,视觉人工智能对这一结论感到挣扎。

图1-2. 烟花图像
Vision AI包括Vision API,可以对图像中的各种物体/特征进行分类、识别和检测(Google, 2021)。使用他们的工具的网络演示,图1-2.a所示的同一图像被通过,并在两种不同的情况下被评估,物体识别和图像标签。Vision AI只对物体进行识别,图1-3中的绿框表示的是闪电,得分是51%(其中 "得分 "是一个从无信心,0%到高信心,100%的值(Google, 2021))。
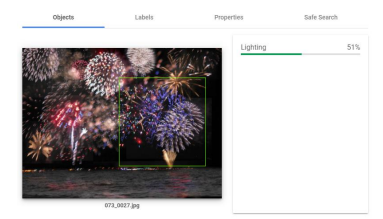
图1-3. 由谷歌云视觉AI分解的烟花图像(谷歌,2021年)
然而,当试图只给整个图像贴上标签而不是搜索特定的物体时,Vision AI明显改善了其预测结果。这些结果,即排名、标签和分数,都显示在表1-1中。开头用 "t-"表示的排名代表得分相同。在排名的顶部,这些标签似乎适合于该图像,特别是 "烟花 "以96%的分数出现在顶部。有几个标签激起了人们对该算法如何工作的好奇心。尽管 "地标 "和 "空间 "的得分是77%,但如果从图像的表面价值来看,它们是不准确的。有几个标签似乎很难被普遍可视化,如 "午夜"、"事件 "和 "假日"。最后,有些标签可能是准确的,也可能是不准确的,这取决于标签的使用环境(例如,同音字,如 "光 "的亮度或重量,这两个词在这里都很合适),以及图片的拍摄环境(例如,"除夕"、"排灯 "和 "中国新年")。
表1-1. 谷歌云端视觉AI标签预测
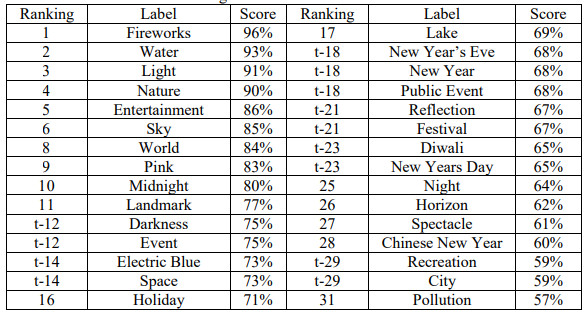
退一步讲,这很可能是一个已知的情况;然而,除了表1-1中的 "烟花 "标签外,其余的顶级分类(得分大于或等于90%)都在不描述图像的类别上,例如 "水"、"光 "或 "自然"。这就是图像分类由于其对它所知道的类/标签的限制而提供了非常狭窄的结果。能够准确地解释或识别这些未知的东西,是目前文献中非常感兴趣的。解决未知数的一个建议是通过应用类比推理(AR),从而通过类比进行推理/学习。
1.1 技术动机
许多图像分类算法是为2010-2018年的ImageNet大规模视觉识别挑战赛(ILSVRC)创建的(Russakovsky, et al., 2015; Stanford Vision Lab, 2020)。ILSVRC主要关注三个不同的任务:图像分类、单一物体定位和物体检测(个别年份有一些变化)(Russakovsky, et al., 2015)。数据集包括1000个不同的类别,有超过一百万张训练图像、五万张验证图像和十万至十五万张测试图像(Russakovsky, et al.) 2010年和2011年的获胜者使用了 "浅层 "人工神经网络(ANNs);然而,从2012年开始,比赛出现了第一个使用深层ANNs的作品,在比赛的生命周期内,深层ANNs一直很受欢迎(Russakovsky, et al., 2015)。这些深度ANNs在图像分类领域是成功的,但需要大量的时间和高性能的计算资源。这些算法,如应用于ILSVRC的ANNs,是在一定数量的熟悉的实例上训练出来的,因此可以处理已知的已知事物。然而,当遇到意想不到的查询时,即一个在最初发布时没有提出的新图像类别时,这种算法要么完全不能胜任,要么表现不佳。
此类问题正是AR在改善人工智能结果方面的巨大潜力。AR可以根据算法已经知道的信息,从一个意外的查询中提取信息。模仿人类使用类比学习的方式,算法也可以做到这一点,而不需要额外的训练场景,更多的计算资源,和/或不合理地延长所需的运行时间。因此,令人感兴趣的是现有的不同类型的AR算法,以及它们如何已经或可以与当前最先进的图像识别程序相结合。
现有的许多AR算法都专注于语言和视觉领域的各种任务。然而,这些算法往往局限于语言或视觉问题,在利用两者的信息方面几乎没有重叠。此外,许多视觉AR算法都集中在基于几何的问题上,例如(Polya, 1990; Sadeghi, Zitnick, & Farhadi, 2015),这并不适用于上面提出的图像分类问题。因此,感兴趣的是在图像识别的背景下使用AR来处理涉及未知数的问题。
1.2 应用动机
图像识别只是人工智能研究的一小部分;然而,它对日常生活的影响是最大的之一。一些例子包括用于解锁手机的面部身份识别,图像到文本的自动字幕生成器,自动驾驶汽车,以及其他许多例子。在这些场景中,不准确和未知的后果大体上从轻微的不便(即不得不手动解锁手机)到可能危及生命的事件(即,自动驾驶汽车没有检测到行人)。随着人工智能的日常使用的增加和后果的扩大,对能够处理未知因素的精确人工智能的需求也在增加。
具体到自驾车场景,图像识别算法需要识别许多不同的东西、物体和/或人,而且越来越不可能为所有可能的现实世界情况收集数据。例如,考虑到一个停车标志,在查看一个停车标志时,各种因素会改变它的表现,如眩光、照明、遮蔽、损坏、阳光角度、背景、油漆质量、外观角度、安装高度等等。由于不可能为每一种可能的情况收集数据,更不用说为其他物体收集数据了,所以能够通过类比推理,认为观察到的油漆褪色的停车标志与已知的停车标志的样子相似,然后判断这可能是一个停车标志,然后指挥汽车停车。
1.3 研究贡献
自1954年Polya的工作开始,算法的AR方法首先在1964年Evan的ANALOGY程序中得到发展(Polya, 1990)。从那时起,AR的许多途径都被探索出来了。与作者的贡献最相关的技术领域列举如下
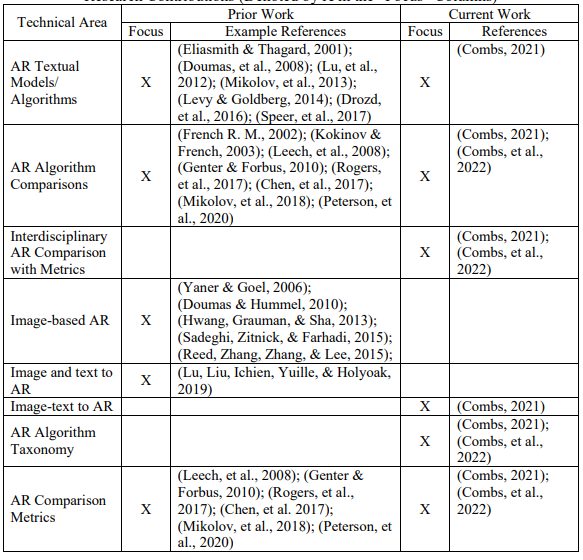
表1-2,列举了最近的前期工作(2000年及以后)以及作者在本论文(Combs, 2021)或单独文章(Combs, Bihl, Ganapathy, & Staples, 2022)中进行的研究的实例参考。
表1-2. 以前的技术贡献和目前的研究贡献之间的关系图(在 "重点 "栏中用X表示)。

1.4 研究目标
了解了技术和应用动机,以便更好地尝试意外的查询,本论文的目标是通过开发一个类比推理-增强的框架,在存在未知的未知因素的情况下提高图像识别。图像识别的发展有很多方式;然而,它们在解释 "已知 "语料库之外的能力方面是有限的。由于其结构围绕着熟悉和不熟悉的场景,AR以前被用来,也将被用来从以前不熟悉的场景中产生信息。为了达到这些目标,研究和开发过程被分成了四个部分。
首先,在第二章中,为了了解AR的现状,需要对AR的算法有一个全面的了解,包括以文本和视觉问题为中心的算法。由于这是在图像分类问题的背景下进行的,所以这里也有一个简短的部分专门讨论图像识别和卷积神经网络(CNN)的研究。其次,在第三章中,由于文献中的AR算法种类繁多,我们进行了广泛的比较,以选择AR中的最佳品种,进一步用于基于图像的问题。六种基于文本的AR算法,包括混合算法和连接主义算法,在评估正确性和良好性的两个指标上进行了比较。接下来,在第四章中,详细描述了一种新的AR集成算法,用于对未知的未知事物进行图像分类。这一节谈到了用于测试算法的数据集,算法的工作原理(技术描述和3个步骤的演练),最后是算法产生的结果。最后,在第五章中,在选定的 "未知数 "背景下,讨论了用于评估结果的两种自动化方法以及作为基线的第三种基于人类的分析。第六章是论文的结尾,一般性地讨论了在图像分类问题上的研究的新颖性,以及未来关于AR如何在其他未知情况下使用的工作。



