

关键词**:**静5青年讲座

编者按
2023年1月11日,香港科技大学助理教授陈启峰博士受邀于北京大学前沿计算研究中心带来题为“AlGC beyond lmages: 3D and Video Synthesis”的在线报告。报告由中心助理教授董豪博士主持,线上近百人观看。

陈启峰博士做线上报告
在报告的开始,陈老师介绍了生成式 AI(Generative Al)的一些应用,比如 OpenAI 发布的 DALL.E 2 在文本生成图像(text-to-image)和图像补全(Image Completion)场景中的应用、Google 发布的 Imagen 在视频生成(video generation)场景的应用以及陈老师实验室探索的 AIGC 在 3D scene Generation,Dynamic Novel Views 和 Image Editing 场景的应用。
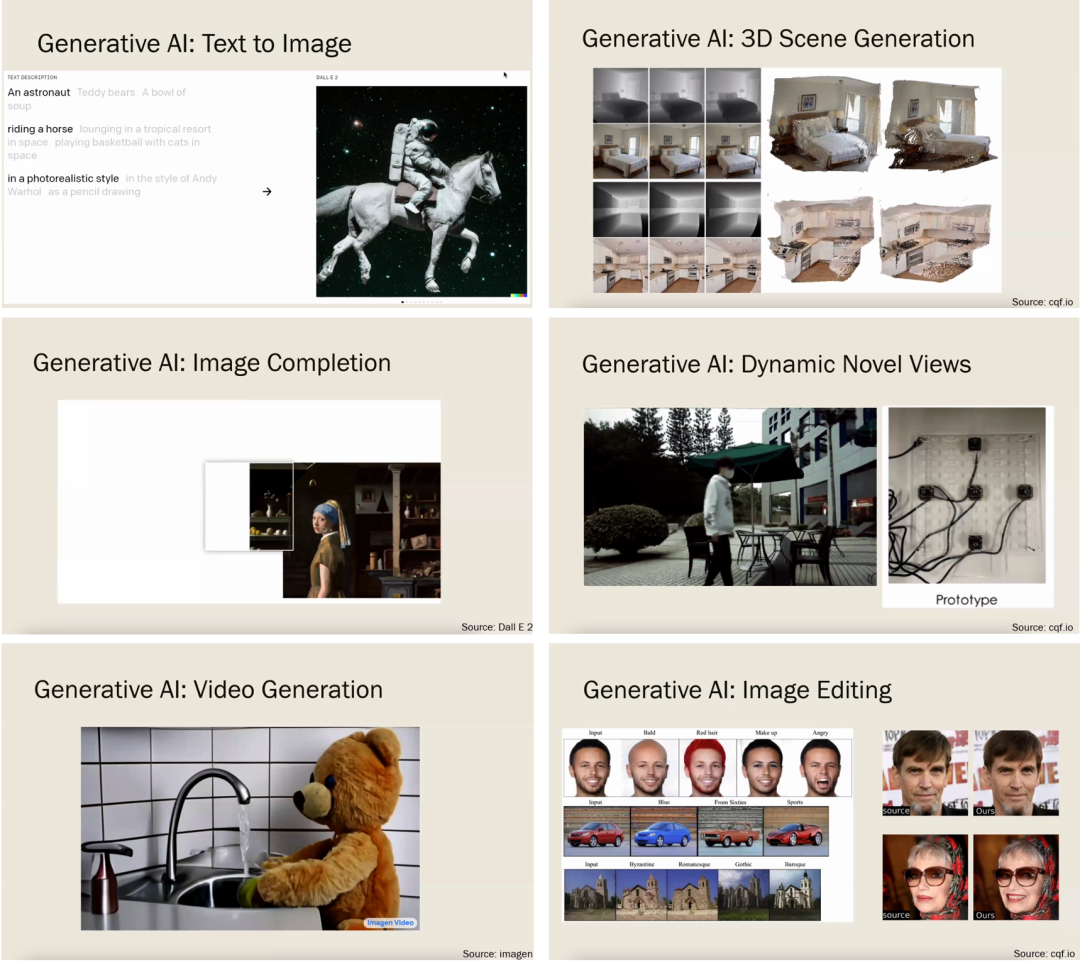
左:AIGC的一些应用。右:陈老师团队在AIGC方向的探索
在过去几年中,生成对抗网络(GANs)已经成为了生成模型的主要技术之一。随着时间的推移,VAE、Flow-based models、扩散模型(Diffusion Models)等新的生成模型慢慢涌现,在数据合成和图像处理等方面取得了很好的表现。陈老师以如下两个主题介绍了生成模型在 3D 视频场景中的拓展和应用:3D 场景和物体合成(3D Scene and Object Synthesis)和可驱动 3D 数字人合成(Controllable 3D Avatar Synthesis)。
1 3D场景与物体合成
3D Scene and Object Synthesis 陈老师首先介绍了其团队发表在 ECCV 2022(Oral)的工作“3D-Aware Indoor Scene Synthesis with Depth Priors”。该工作考虑目前多数室内场景合成的工作都集中在研究 2D 图像合成上,而忽略了 3D 几何结构信息的准确性与多视角一致性。为了解决这个问题,陈老师展示了一种考虑深度先验的 3D 室内场景合成方法,该方法提出了一种 Dual-path Generator,其中一条分支用于生成室内场景深度图,并以此为先验另一分支生成对应的 RGB 图,进一步提出 Switchable Discriminator,利用预训练单张图像深度估计网络设计 3D 一致性损失,实现了较好的室内场景合成的效果。

接下来陈老师介绍了其团队在 NeurIPS 2022(Spotlight)的工作“Improving 3D-Aware Image Synthesis with a Geometry-Aware Discriminator”。先前多数基于 GAN 的图像合成模型只设计了考虑 3D 结构的生成器(如利用 NeRF 实现),该工作探索了考虑 3D 结构的判别器的设计,以提升图像合成的效果。
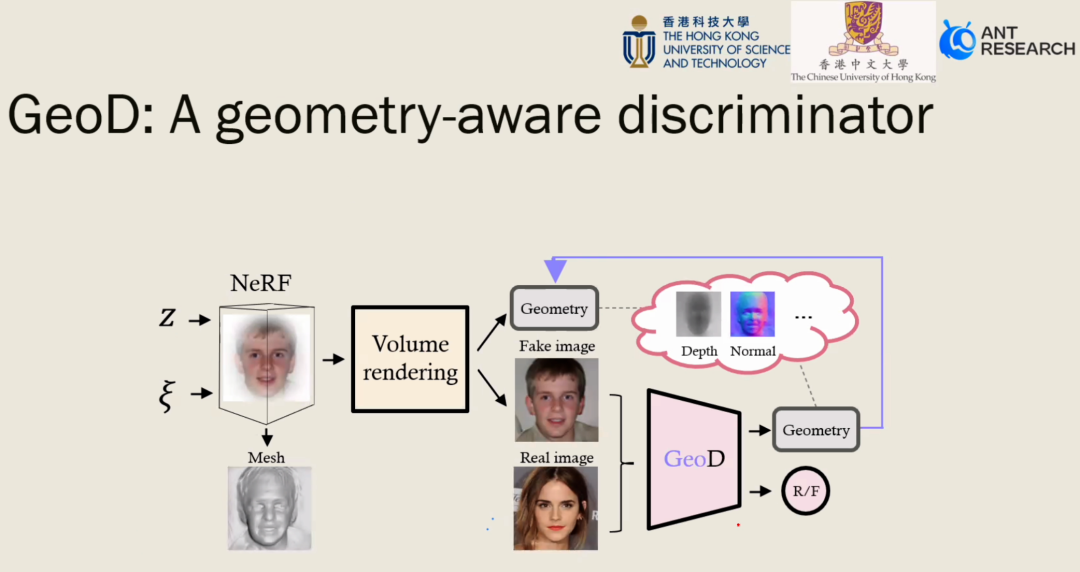
2 可驱动数字人合成
Controllable 3D Avatar Synthesis 如何实现可驱动的数字人的合成是 AIGC 的研究热点,其在游戏和电影制作等领域中应用广泛,陈老师进一步介绍了其在可驱动数字人合成方向上的一些工作,主要涉及数字人的肢体动作、脸型及表情的驱动与合成。
关于数字人的肢体动作驱动与图像合成,陈老师介绍了其团队在 ECCV 2022的工作“Real-Time Neural Character Rendering with Pose-Guided Multiplane Images”,该工作提出了一种基于 Pose-Guided Multiplane Images 的模型,利用输入的人体姿态控制人物动作,利用 Multiplane Image 的表征用来实时渲染不同视角的图像。
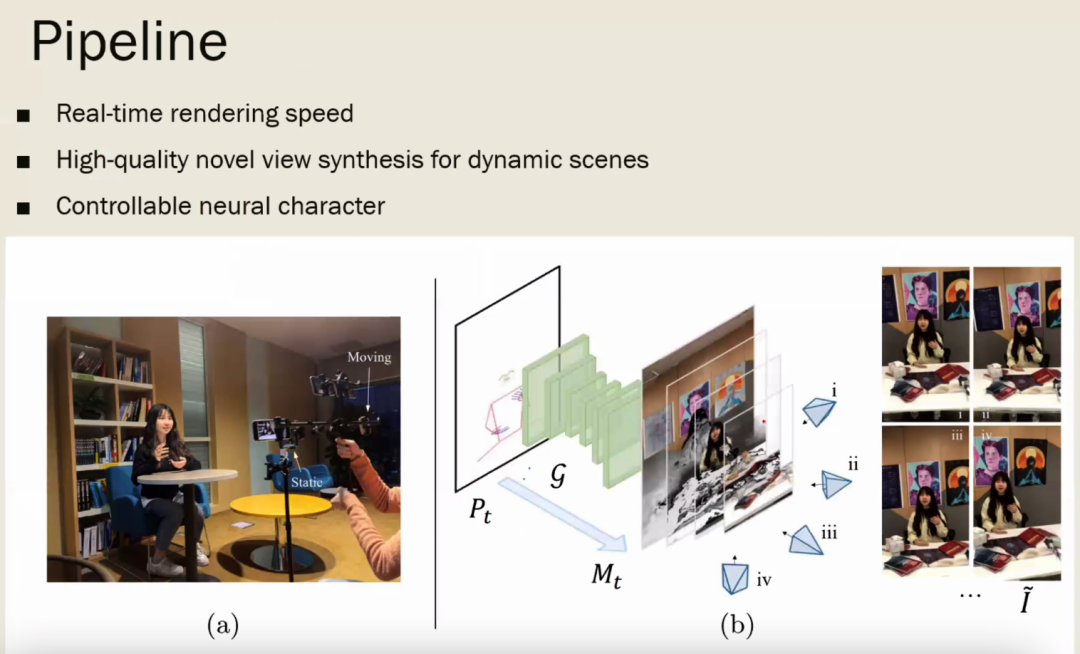
关于数字人的脸型及表情的图像合成,现有多数工作可以从不同的角度渲染人物头像,但是合成的人物表情是不可控的。陈老师介绍了其团队发表于 NeurIPS 2022(Spotlight)的文章“AniFaceGAN: Animatable 3D-Aware Face Image Generation for Video Avatars”。该工作关注表情可驱动的人脸合成问题,把人脸合成任务中人脸的脸型以及表情解耦,通过生成模型生成某一表情对应的变形场,并将其作用于生成的标准的(无表情)人脸模型,实现了表情可驱动的人脸合成。
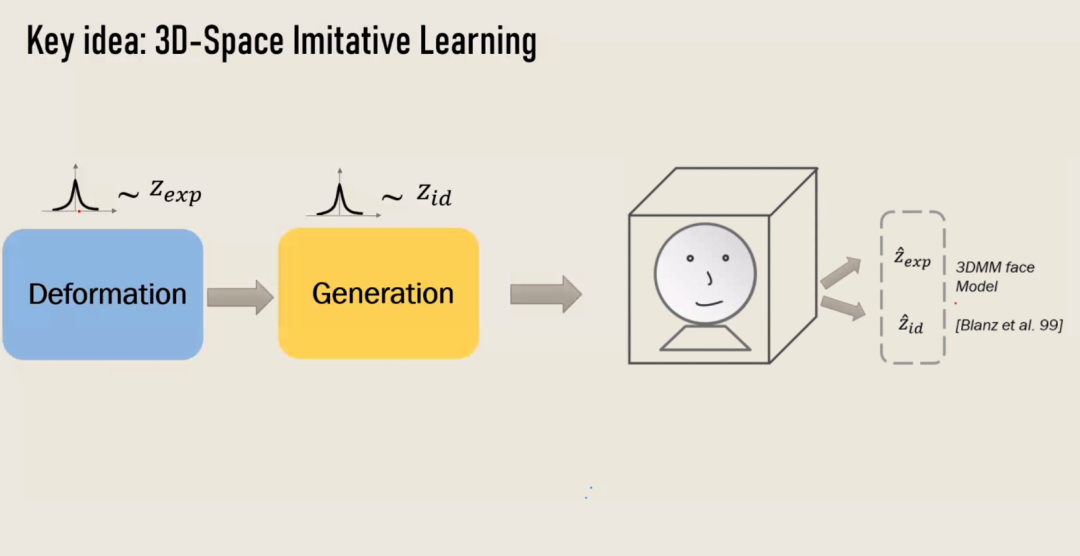
讲座尾声,陈老师表达了对 AIGC 应用的未来展望。AIGC 作为工具的使用对象会更加泛化,不只是艺术工作者还可以是普通用户,3D 和视频合成将是 AIGC 的主要研究方向以及还会在元宇宙、AR/VR 等领域更受欢迎!最后并对同学们提出的提问进行了详细的解答。

