基于姿态的人物视频生成【附PPT与视频资料】

关注文章公众号
回复"sffai1"获取PPT资料
视频资料可点击下方阅读原文在线观看
导读
合成特定姿态下的人物图像,并进一步让人物动起来,做出逼真,连贯的动作,是多媒体领域颇具趣味的研究方向。近年来,图像生成及图像翻译领域快速发展,为人物动作视频合成问题提供了有效的实现路径。利用骨架+纹理特征合成视频帧的研究思路,现有研究取得了一定突破,已经能够合成较为流畅的高分辨率人物动作视频,但在处理遮挡,提升动作真实性,以及特征解耦等方面还有明显改进空间。本次讲座将带大家一同回顾人物动作视频生成的发展历程,解读若干最新的重要成果,并同大家共同探讨未来的发展趋势。
作者简介
杨凌波,北京大学数字媒体研究所在读博士生,本科毕业于北大数学系数学与应用数学专业。目前主要研究方向为骨架引导下的人物图像/视频生成。

杨凌波
前言
基于姿态的人物图像/视频合成,可以分为两个子问题:学习足以表达,刻画人体结构及人物动作的特征表示,以及学习从特征表示到人物图像/视频帧空间的生成映射。随着人体姿态估计及条件图像生成/翻译领域的发展,上述两个子问题有了相应的解决途径,在若干局部取得了可喜的进展。下面将扼要介绍四篇人物图像/视频生成领域的经典工作,简要分析其创新点及局限性,并简要总结该领域当前面临的问题与挑战。
相关工作
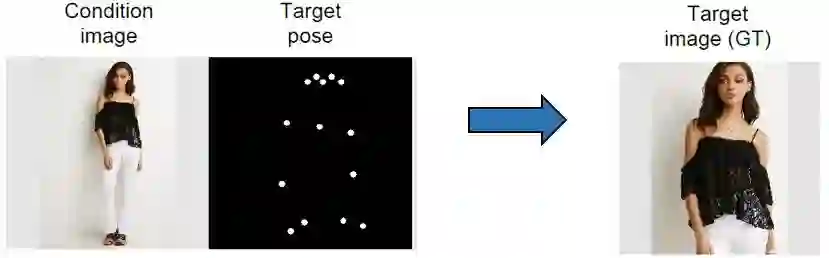
MaLiqian等人于2017年NIPS(现NeurIPS)发文“Pose guided Person Image Generation”,首次明确了人物姿态图像合成问题的一般形式:给定一张内容图像(content image)和待合成目标姿态(target pose),生成图像中人物在新姿态下的外观,如下图所示:
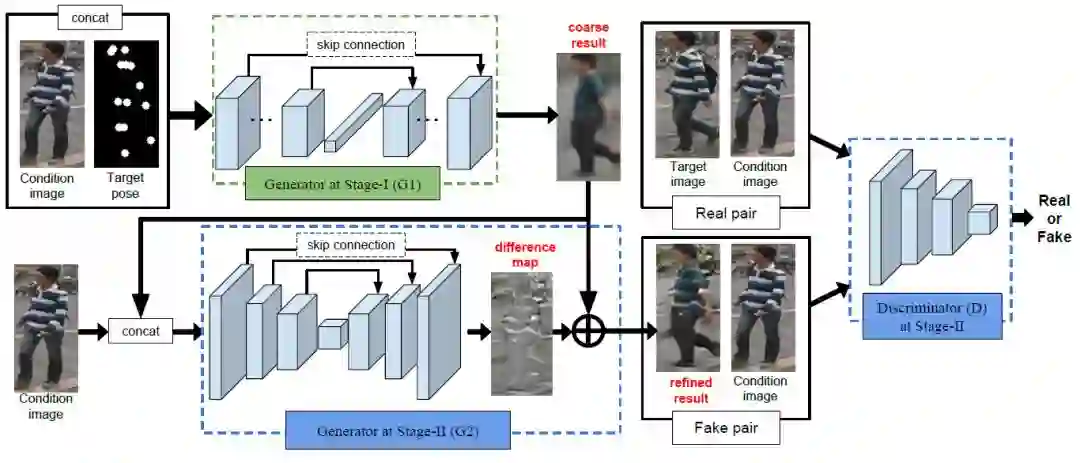
本篇文章中提出了一种两段式学习框架,通过从粗到精的方式合成新姿态下的人物图像:第一阶段首先合成目标姿态下人物的大体轮廓,并大致保持衣着颜色;第二阶段在前一阶段的结果基础上再学习精细的残差,增强合成图像的细节纹理。训练流程图如下所示:
在DeepFashion数据集上的生成效果如下所示:

在生成方面,作者直接借鉴了同时期图像翻译工作pix2pix的网络设计,通过引入跳层连接(skip connection)保持原图的纹理细节。
Alexander Siarohin等人考虑到姿态迁移问题中的结构不一致性,提出了Deformable GAN,利用“形变跳层连接“(deformable skip connection)来保持纹理信息与骨架位置的对应关系,原理图如下:
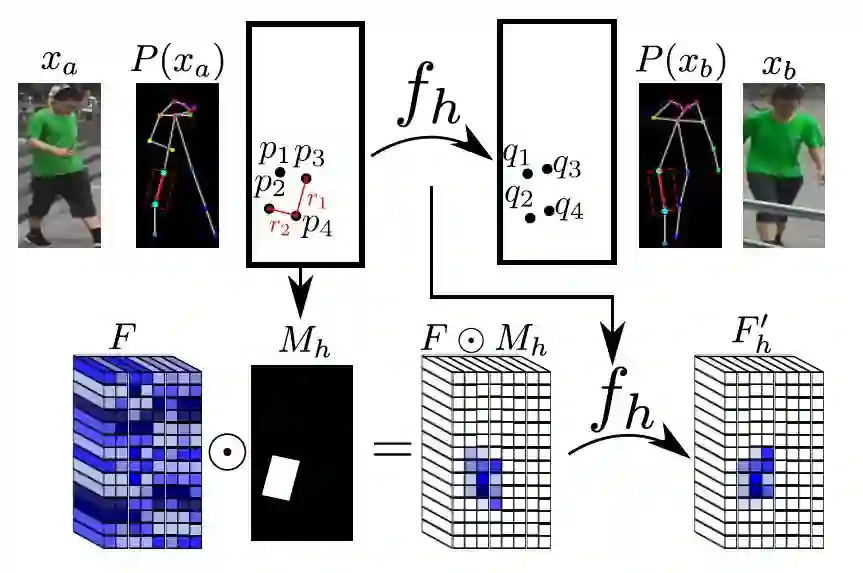
通过形变跳层连接将人体不同部位的纹理信息“搬“到新的姿态骨架上,Deformable GAN能够保留更多的纹理信息,显著提升了生成的图像质量:

前两种方法都只考虑2D层面的人物特征提取,因此无法很好处理遮挡的情形,下图即为一例:

Facebook则另辟蹊径,提出了一种更为丰富,考虑人体3D表面信息的姿态表示Densepose(http://densepose.org/):

基于Densepose表示,Facebook进一步提出了Dense Pose Transfer,通过融合生成网络预测(predict)模块及人物纹理形变(warpping)模块的结果来获得更为鲁棒的人体姿态外观表征:
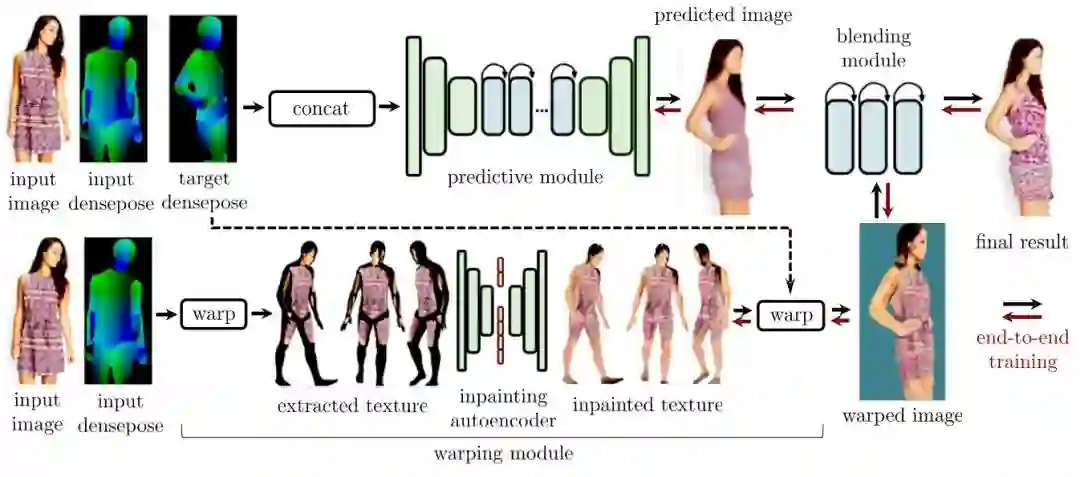
与Deformable GAN相比,Dense Pose Transfer由于在姿态表示中融合了人体表面纹理信息,从而能够更好地保持衣着纹理细节,并有效解决一部分的遮挡,断肢等问题。下图中第一行为Deformable GAN的结果,第二行为Dense pose transfer的结果:

与图像生成不同,视频动作生成的工作更多收到图像翻译(Image-to-image translation)的启发,直接学习人体骨架图到真实视频帧的映射,纹理信息完全由数据驱动的方式从训练视频中提取。Berkeley AI Lab的Caroline Chan等人于2018年Siggraph提出EverybodyDance Now,首次合成了高分辨率的人物舞蹈动作视频(视频地址:https://www.youtube.com/watch?v=PCBTZh41Ris)。

EverybodyDance Now综合了生成领域的各种实现技巧:骨架尺寸归一化,前后帧联合预测提升时域一致性,以及人脸部分单独增强等(相应的图可以从PPT里直接找到)。
问题与挑战
人物动作视频生成问题自提出至今不足两年,尚属初期阶段,各种不同的特征表示及生成策略纷纷出现。其中基于骨架的特征表示,以及基于图像翻译领域的pix2pix生成网络结构引领了当前研究的主流,并取得了较好的结果。个人认为,目前人物视频合成领域面临两个核心问题:其一,人物肢体遮挡造成纹理细节缺失,单纯依靠单帧图像提供纹理信息有明显缺陷,需要引入更多3D-aware的姿态特征表示,如Densepose;其二,对于自然人物动作视频的统计特性学习及表示还有待进一步发展,以便更好地建模人体运动,避免动作生硬,不连续等问题。未来基于3D人体模型及人物纹理贴图渲染的思路可能会带来下一个新的突破点。
参考文献
[1] Ma, Liqian, et al."Pose guided person image generation." Advances in NeuralInformation Processing Systems. 2017.
[2] Siarohin, Aliaksandr, etal. "Deformable gans for pose-based human image generation." CVPR20 18-Computer Vision and Pattern Recognition. 2018.
[3] Neverova, Natalia, RızaAlp Güler, and Iasonas Kokkinos. "Dense pose transfer." arXivpreprint arXiv:1809.01995 3 (2018).
[4] Chan, Caroline, et al."Everybody dance now." arXiv preprint arXiv:1808.07371 (2018).
SFFAI讲者招募
为了满足人工智能不同领域研究者相互交流、彼此启发的需求,我们发起了SFFAI这个公益活动。SFFAI每周举行一期线下活动,邀请一线科研人员分享、讨论人工智能各个领域的前沿思想和最新成果,使专注于各个细分领域的研究者开拓视野、触类旁通。
SFFAI目前主要关注机器学习、计算机视觉、自然语言处理等各个人工智能垂直领域及交叉领域的前沿进展,将对线下讨论的内容进行线上传播,使后来者少踩坑,也为讲者塑造个人影响力。
SFFAI还将构建人工智能领域的知识树(AI Knowledge Tree),通过汇总各位参与者贡献的领域知识,沉淀线下分享的前沿精华,使AI Knowledge Tree枝繁叶茂,为人工智能社区做出贡献。
这项意义非凡的社区工作正在稳步向前,衷心期待和感谢您的支持与奉献!
有意加入者请与我们联系:wangxl@mustedu.cn


历史文章推荐:
芯片行业都难在哪儿?这篇说得最详细!
陶哲轩对数学学习的一些 建议
448页伊利诺伊大学《算法》图书【附PDF资料】
一文看尽2018全年计算机视觉大突破
从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
SFFAI分享 | 曹杰:Rotating is Believing
SFFAI分享 | 黄怀波 :自省变分自编码器理论及其在图像生成上的应用
AI综述专栏 | 深度神经网络加速与压缩
若您觉得此篇推文不错,麻烦点点好看↓↓
