CVPR 2022 | 快手&百度提出MobRecon:移动端手部三维重建网络
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:陈星宇 | 已授权转载(源:知乎)编辑:CVer
https://zhuanlan.zhihu.com/p/494755253
本文介绍我们发表在CVPR2022上的工作,MobRecon: Mobile-Friendly Hand Mesh Reconstruction from Monocular Image。本文的主要贡献是同时实现了轻量、准确、稳定的手部三维重建方法,并已在移动端应用。

论文链接:
https://arxiv.org/abs/2112.02753
代码链接:
https://github.com/SeanChenxy/HandMesh
1. 背景和研究动机
我们的社会正在走向越虚拟化,将会有越来越多的穿戴式混合现实产品或者沉浸式虚拟现实产品问世。与现实世界一致,手部也将成为我们与虚拟世界交互的重要工具。因此,手部的虚拟化对未来的XR技术有着十分重要的意义。
从单目RGB估计手部几何结构的问题,已发展成为了一个成熟的视觉与图形学的交叉领域,可参见以下链接详细了解近年来该领域的研究进展。
提出了MobRecon框架,仅包含123M Mult-Adds (乘加操作)和 5M #Param(参数量),能够在Apple A14 CPU上达到83FPS。
设计了轻量化的2D编码结构与3D解码结构。
提出了feature lifting module来桥接2D与3D特征表达,其中包括了用于2D关键点估计的MapReg(map-based position regression),用于点特征提取的pose pooling,用于特征映射的 PVL(pose-to-vertex lifting)。
2. 方法
Overview
MobRecon沿用基于图方法的vertex回归思路,在传统的编-解码结构 [1,2] 中间插入一个feature lifting阶段。所谓lifting,指的是从2D空间到3D空间的映射,我们着重在并在这个阶段中降低参数成本,并同时提高精度与时序稳定性。另外,我们也轻量化了3D解码部分,在降低计算成本的同时尽可能保持其他性能不变。MobRecon的整体框架如图1所示。

2D encoding:图像特征编码
Feature lifting:2D特征向3D空间映射
3D decoding:3D特征向3D坐标解码
2D encoding
如图2所示,我们设计了两种Hourglass结构来表达图像,称为DenseStack和GhostStack,计算量和参数量为
DenseStack:373M Multi-Adds,6M #Param
GhostStack:96M Multi-Adds,5M#Param
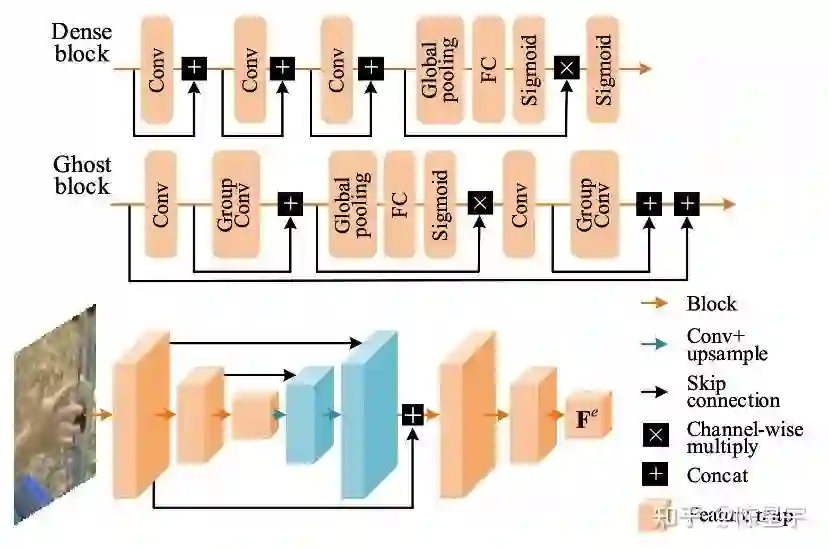
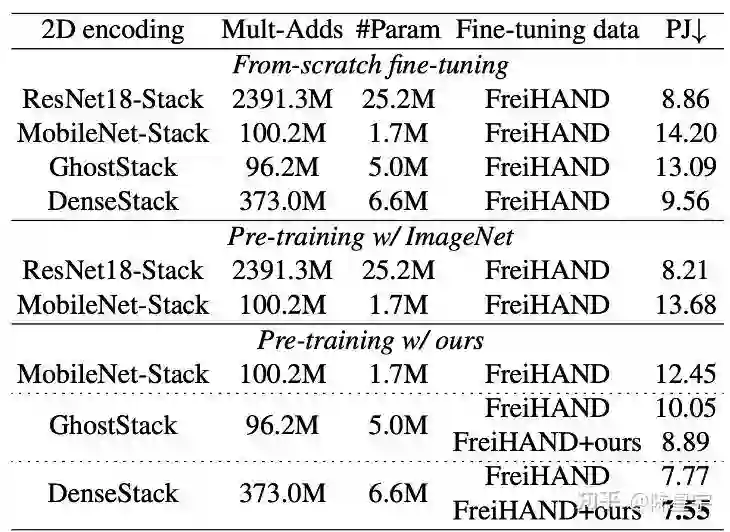
表1对2D encoding进行了详细的分析,我们的模块在大幅优化计算量与参数量的情况下保持了不错的重建精度。同时,表1还展示了我们的虚拟数据的作用,虚拟数据的设计思想详见paper的补充材料。
Feature lifting
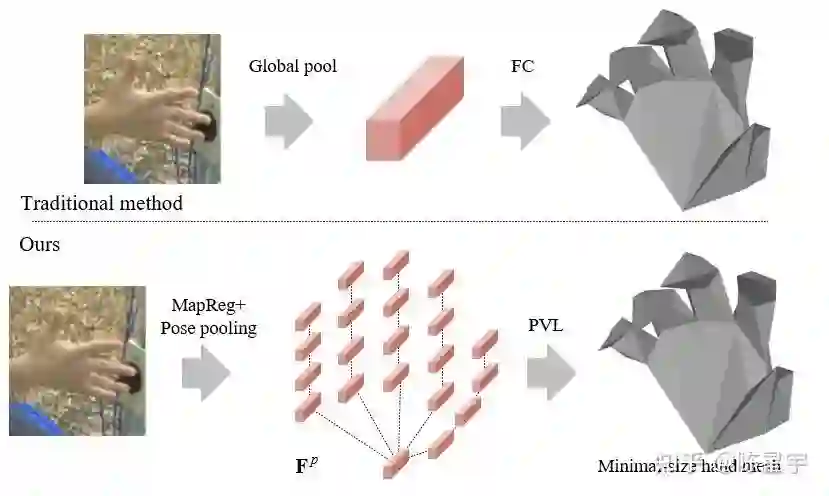
这个阶段的目的是将图像特征从2D空间映射到3D空间。如图6所示,传统方法[1,2]没有显示的feature lifting阶段,而使用一个全连接操作把图像的全局特征映射为一个很长的特征向量,再重组为3D点特征。我们的设计分为3个步骤:2D关键点估计,关键点特征提取,特征映射。
我们提出Map-based position regression(MapReg)来估计2D关键点。如图4所示,已经有许多成熟的方法处理2D关键点估计,因此这个问题常常被大家忽略,也少有工作探索如何同时提高2D关键点的精度与时序一致性。我们对这个问题的思考如下:
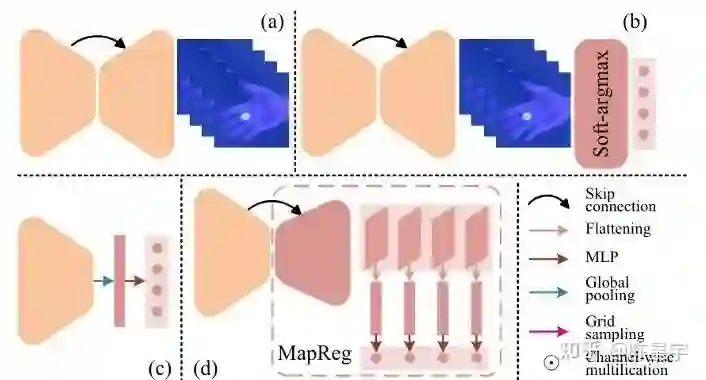
heatmap,图4(a)。
高分辨率表达(e.g., 64x64),通过融合浅层特征和语义特征,表达粒度更细。
但是,感受野过小,难以产生关键点之间的约束。
regression,图4(c)。
低分辨率表达(i.e., 1x1),始终保持语义上的全局感受野,结构表达能力更强。
但是,浅层特征丢失,细节表达能力不足。
以上两种基本方法各有优缺点,并优势互补,能否将他们结合起来?
heatmap + soft-argmax,图4(b)。
高分辨率表达 ,继承了heatmap的优点。
虽然有全局感受野,但来自启发式规则,因此并未继承regression的优点。
MapReg,图4(d),也是本文所提出的方法。我们设计了一个很小的4倍上采样结构,在上采样的过程中融入浅层特征。将融合后的特征沿channel维度展开,即, 将2D空间结构展开为1D向量。使用MLP把多个1D向量回归为多个关键点的2D坐标。MapReg有以下特点:
中分辨率表达(e.g., 16x16),继承了heatmap的优点。
语义全局感受野,继承了regression的优点。
MapReg计算复杂度与空间复杂度上都介于heatmap和regression之间。
从图5中可以明显地观察到MapReg的优势:(1)heatmap表达的粒度很细,但每个点独立地被表达;(2)heatmap+soft-argmax的全局感受野是启发式的,因此它的结果只是heatmap的平滑;(3)MapReg能够自主表达关键点之间的约束。

我们使用pose pooling来提取关键点特征。如图6所示,我们对CNN编码特征 



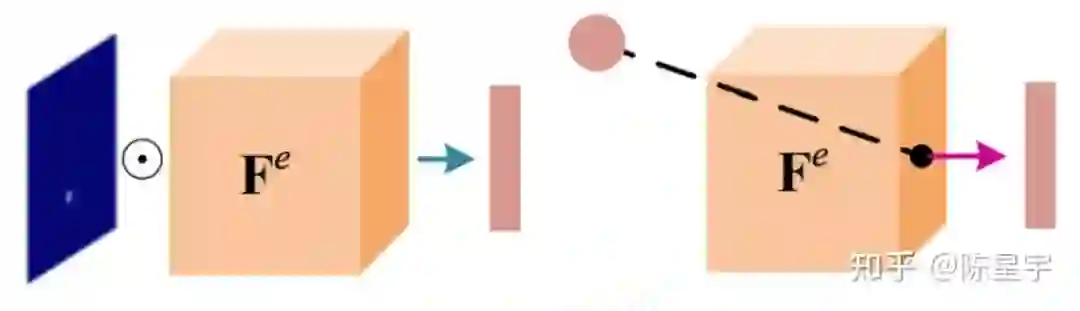
我们提出pose-to-vertex mapping(PVL)来实现特征映射。如图3所示,传统方法通常使用全连接操作对全局特征进行mapping,导致大量的计算成本。我们设计了更轻量的PVL。
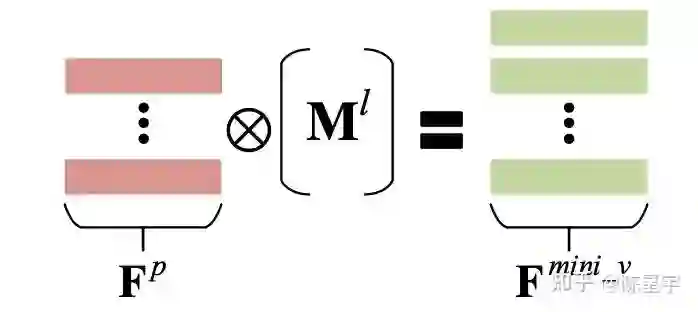

由于 A, D 为常量,上式可简化为图7所示的结构。
图8展示了一个学习后的 M' ,其中,行的方向为2D关键点的索引,列的方向为mesh顶点的索引。图9展示了关键点与mesh顶点之间的高度相关的特征传播。可见 M' 有以下特点:
稀疏的性,大部分位置接近0。
存在全局特征表达,i.e., joint #5 对几何每个mesh顶点都有贡献。
特征传播具有语义一致性。
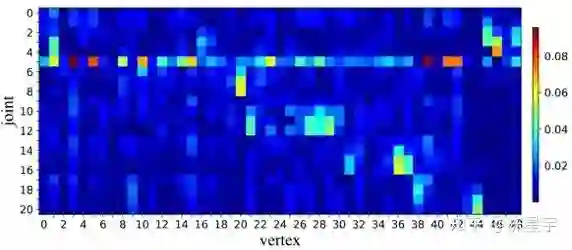
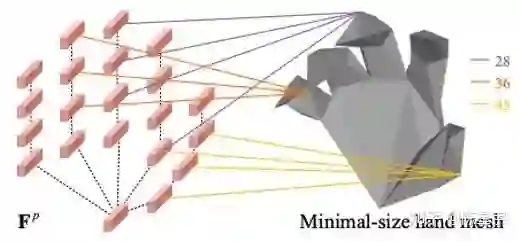
表2对整个feature lifting过程进行了详细分析:MapReg同时获得了最好的2D精度(2D AUC)、加速度(2D Acc),PVL的计算成本更优,并同时获得了最佳3D精度(3D AUC)与加速度(3D Acc)。

一致性约束
在轻量化3D decoding之前,我们通过一致性约束进一步加强时序一致性。如图10所示,利用单样本的仿射变换制造样本对,并在原空间中对模型预测的mesh 顶点及2D关键点进行一致性约束:
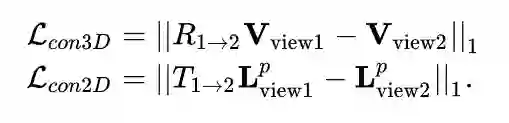
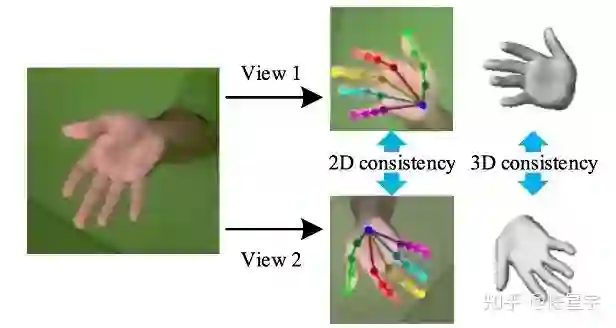
实验结果表明一致性约束有助于降低时序加速度,同时对重建精度也有轻微的正向作用。
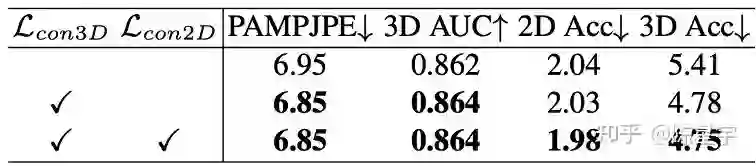
3D decoding
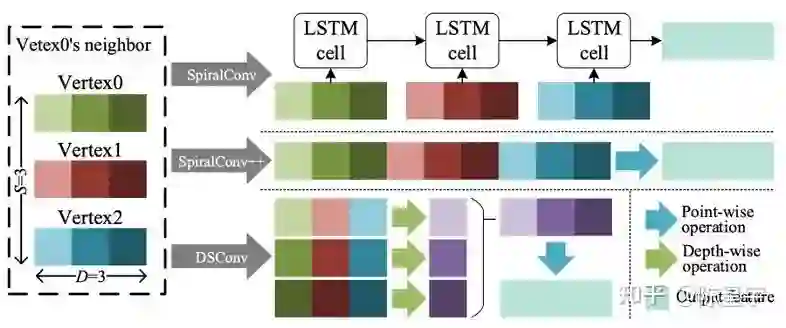
由于mesh的本征维度是二维,我们采用简单高效的的螺旋卷积实现3D解码。mesh顶点的的邻域定义如图11所示,这种方式完全等价于图像卷积对邻域的定义。
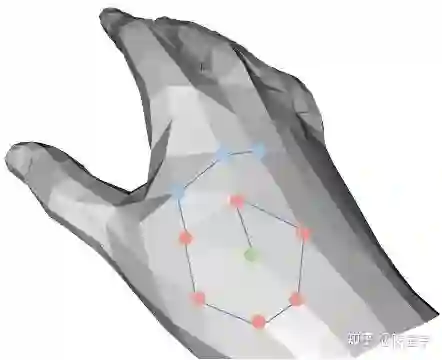
定义邻域后,卷积操作的下一步是特征融合。如图12所示,传统方法使用LSTM [5] 或者很大的FC [6] 进行特征融合,它们或者无法并行计算或者有很高的计算成本。我们提出DSConv,迁移Depth-wise separable convolution到针对mesh顶点的特征操作。与[6]相比,DSConv的计算复杂度更优,即:
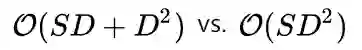
实验结果表明DSConv有效降低了计算量与参数量,并保持重建性能基本不变。整个MobRecon在Apple A14 CPU上达到83FPS。
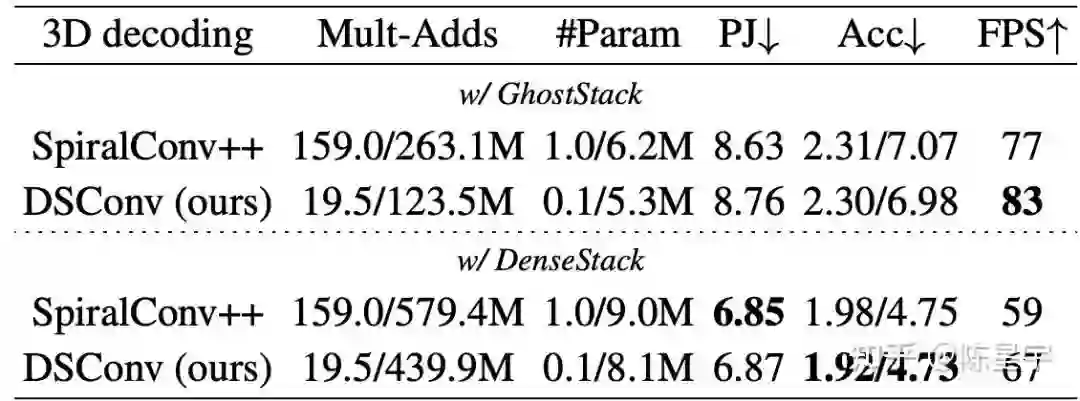
Limitation
MobRecon 是一个对移动端CPU友好的框架,但在GPU上的并行计算效率并不高。主要原因是可分离卷积、螺旋邻域采样等方法增加了内存访问成本。
3. 对比实验
重建精度
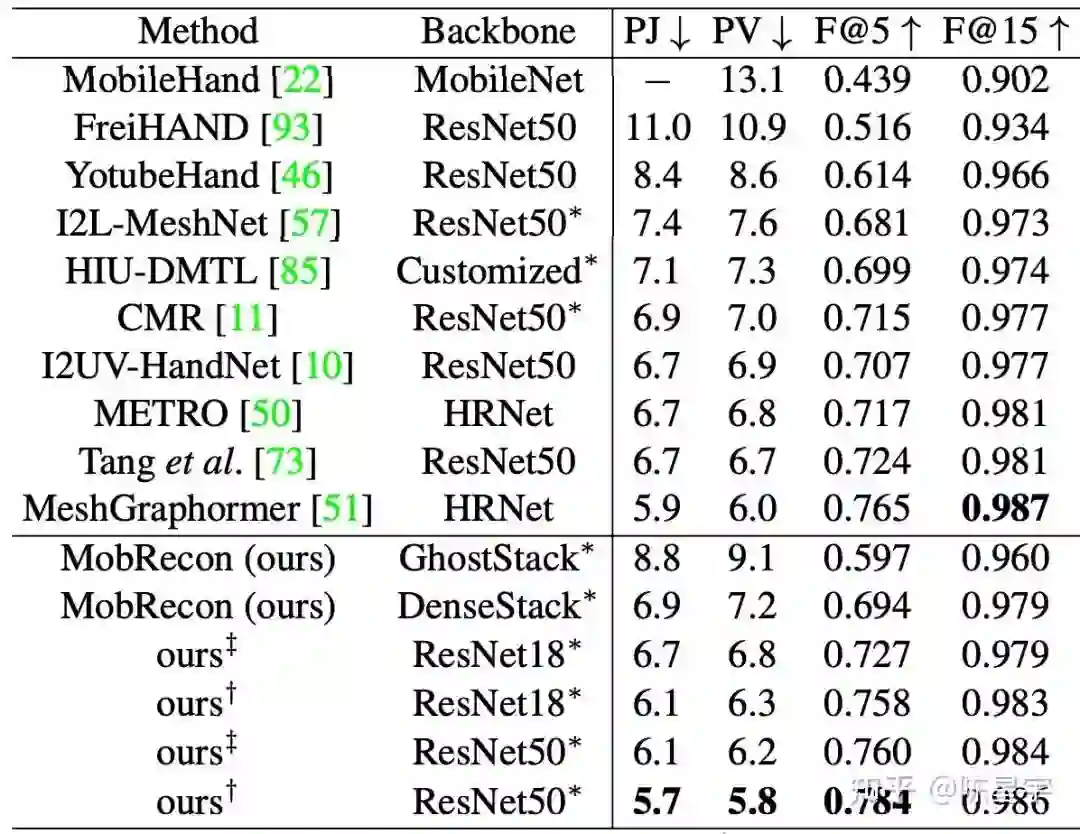
如图13所示,基于FreiHAND数据集,MobRecon的重建精度与一些大模型方法几乎一致。如果替换MobRecon的2D encoding部分为ResNet50,能够获得非常不错的精度。更多对比实验请参见paper。
时序一致性
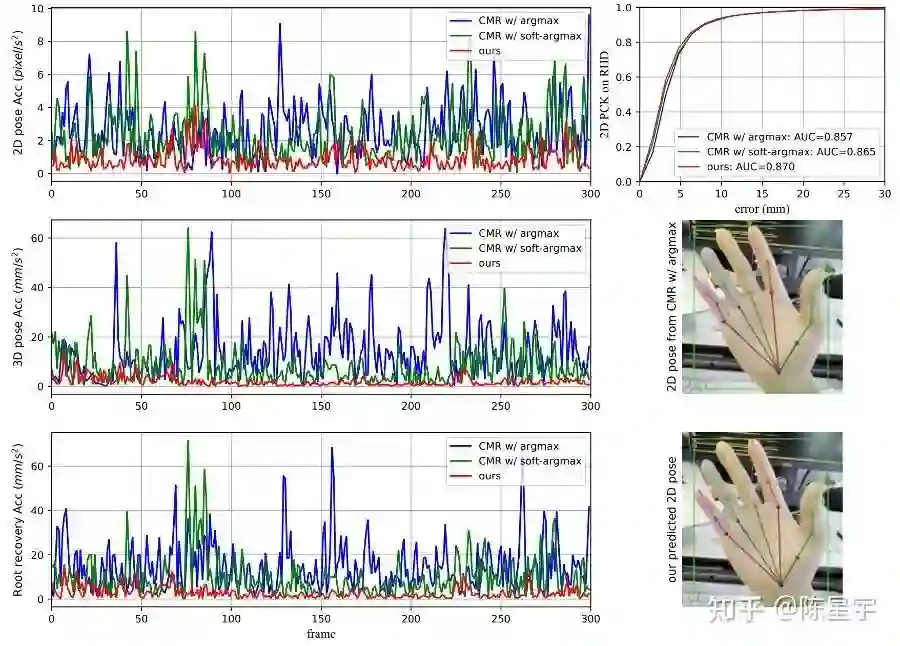
在图14中,我们与[2]对比时序性能。视频序列的内容如右下子图所示,尽管在整个视频中保持手部姿态不变,预测结果依然存在抖动。图中左边的三个图表分别展示了2D空间、人体3D空间和相机空间预测的加速度,红色曲线为MobRecon的结果,明显由于基于heatmap的[2]。如右下子图所示,相比于heatmap,MapReg产生了更好的关键点间的约束与2D结构,从而在时序上表现出更强的稳定性。可以得出结论,MobRecon是一种非序列的单目方法,并不存在时序模块,而它在时间维度上的稳定性本质上是由空间维度中的结构化表达带来的。
4. Outlook
就精度而言,基于RGB的hand pose/mesh估计已基本达到可以实际应用的水平,学术界未来会更多关注手部的渲染、自监督、时序建模、手部行为理解等高阶任务。同时,面向双手、手物、人体的交互类工作将越来越多。此外,手部肌肉建模、机器人操作、手+语音多模态交互等方向也值得关注。
Reference
[1] Dominik Kulon, Riza Alp Guler, Iasonas Kokkinos, Michael Bronstein, Stefanos Zafeiriou. Weakly-supervised mesh-convolutional hand reconstruction in the wild. CVPR2020.
[2] Xingyu Chen, Yufeng Liu, Chongyang Ma, Jianlong Chang, Huayan Wang, Tian Chen, Xiaoyan Guo, Pengfei Wan, Wen Zheng. Camera-space hand mesh recovery via semantic aggregation and adaptive 2D-1D registration. CVPR2021.
[3] Alejandro Newell, Kaiyu Yang, and Jia Deng. Stacked hourglass networks for human pose estimation. In ECCV2016.
[4] Thomas N. Kipf, Max Welling. Semi-supervised classification with graph convolutional networks, ICLR2017.
[5] Isaak Lim, Alexander Dielen, Marcel Campen, and Leif Kobbelt. A simple approach to intrinsic correspondence learning on unstructured 3D meshes. In ECCV, 2018.
[6] Shunwang Gong, Lei Chen, Michael Bronstein, and Stefanos Zafeiriou. SpiralNet++: A fast and highly efficient mesh convolution operator. In ICCV Workshops, 2019.
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号

整理不易,请点赞和在看




